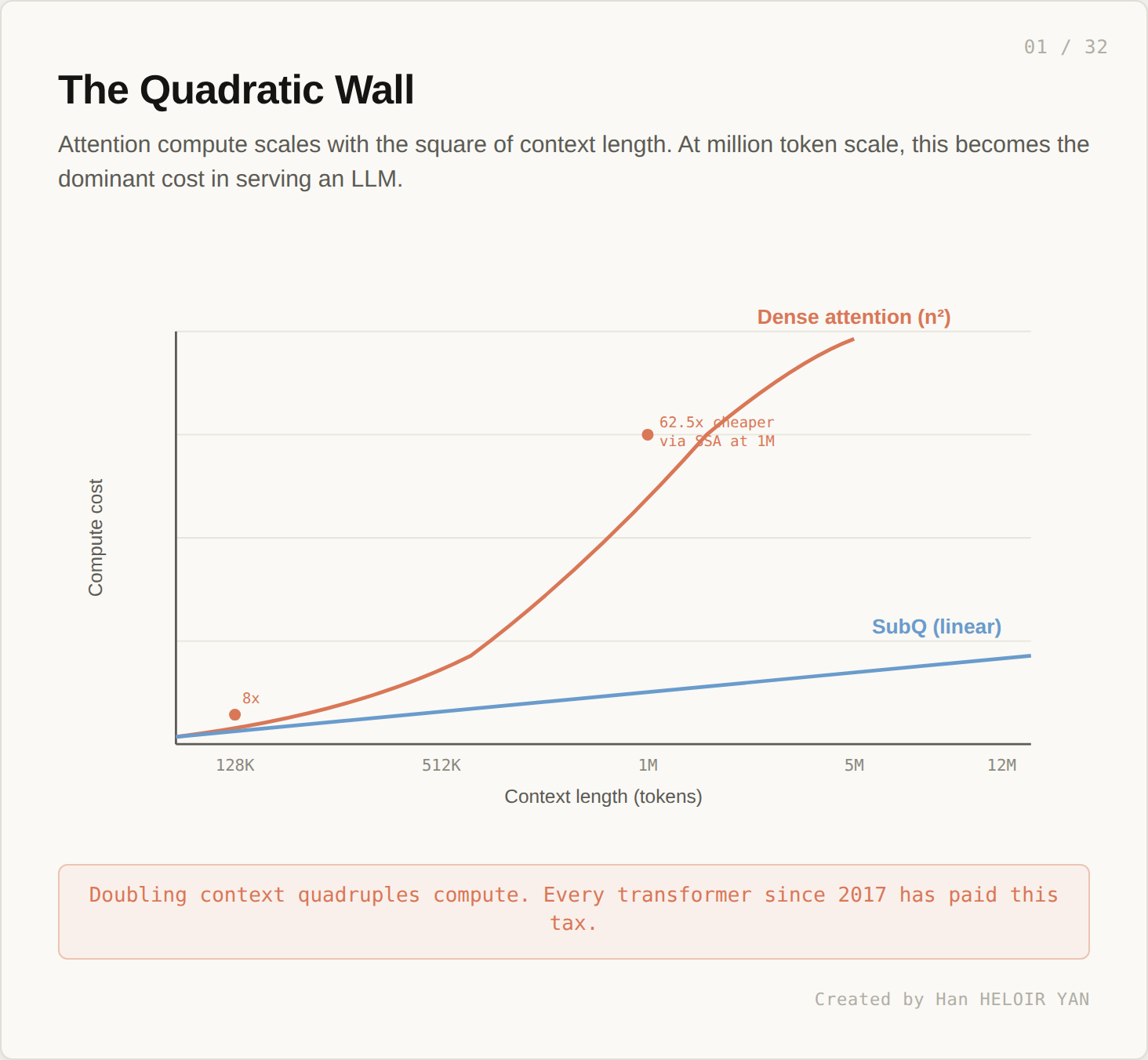
You ship a model with a 1 million token context window. Production traffic looks fine at 50K. At 200K, latency doubles. At 800K, the GPU bill triples. By 1M, you are debating whether to break the request into chunks because the math says one forward pass is no longer worth doing.
This is not a configuration issue. Every transformer since 2017 pays the same tax: attention compute scales with the square of context length. Doubling tokens quadruples the work. The wall is in the architecture itself.
On May 5, 2026, a Miami startup called Subquadratic claimed they had walked through it. Their model, SubQ, advertises a 12 million token context window with linear scaling and no obvious trade off in capability. Reported numbers include a 52x wall clock speedup over FlashAttention 2 at one million tokens, and parity with Claude Opus 4.6 on RULER.
This article is a field map. What came before. Why each prior approach made the compromises it did. What would have to be true for SubQ’s claim to hold.
If this helps you ship better AI systems:
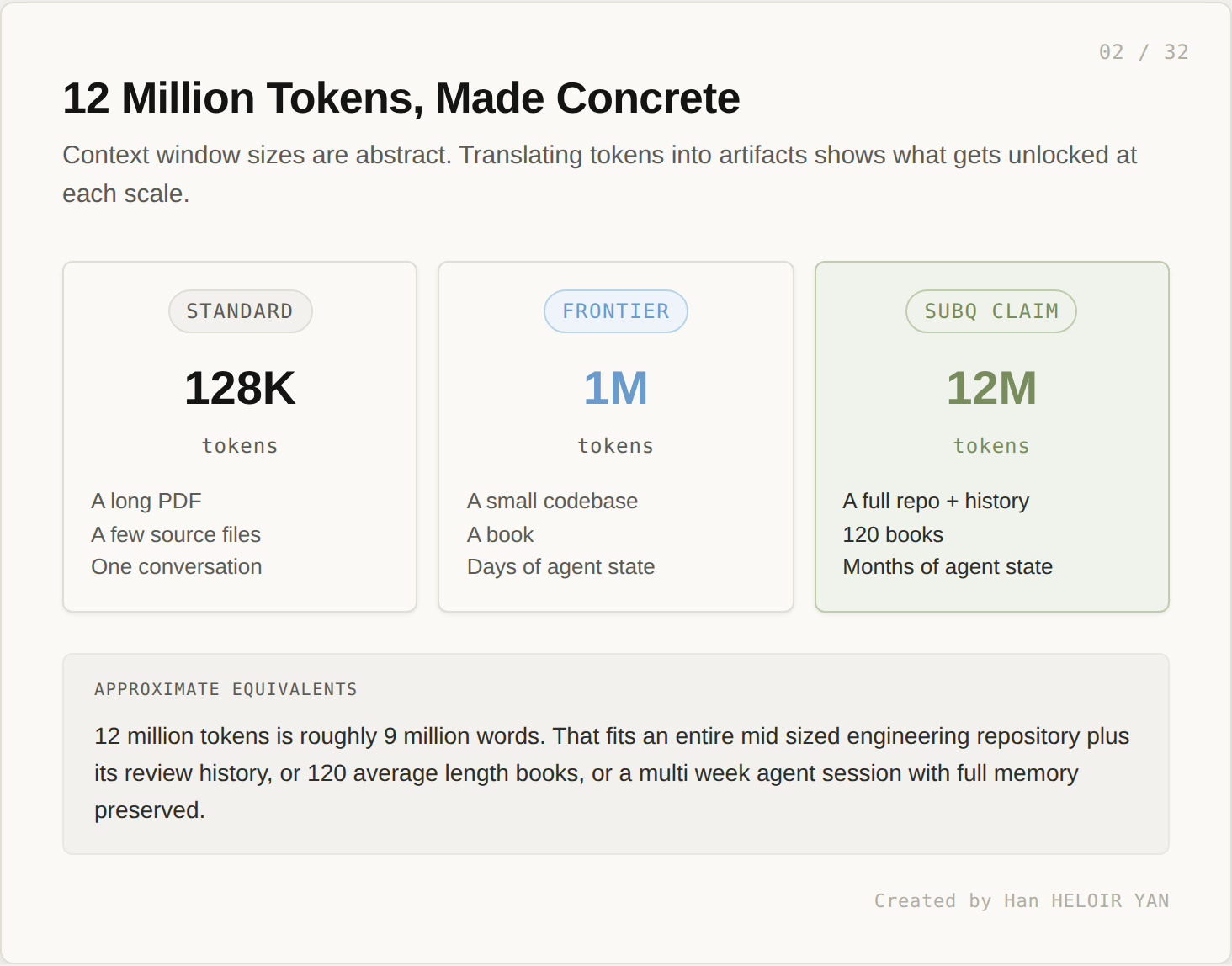
The shape of the context window decides the shape of the system you can build around the model. At 128K tokens, you build a chatbot with retrieval. At 1M, you build a coding agent that holds a small repository in head. At 12M, if it works, you replace several layers of infrastructure with one model call.
That last sentence is the controversial one. It assumes long context is structurally cheap, not just nominally available. Many models advertise million token windows. Few are economical to actually use at that length, and the engineering economics shape what gets shipped.
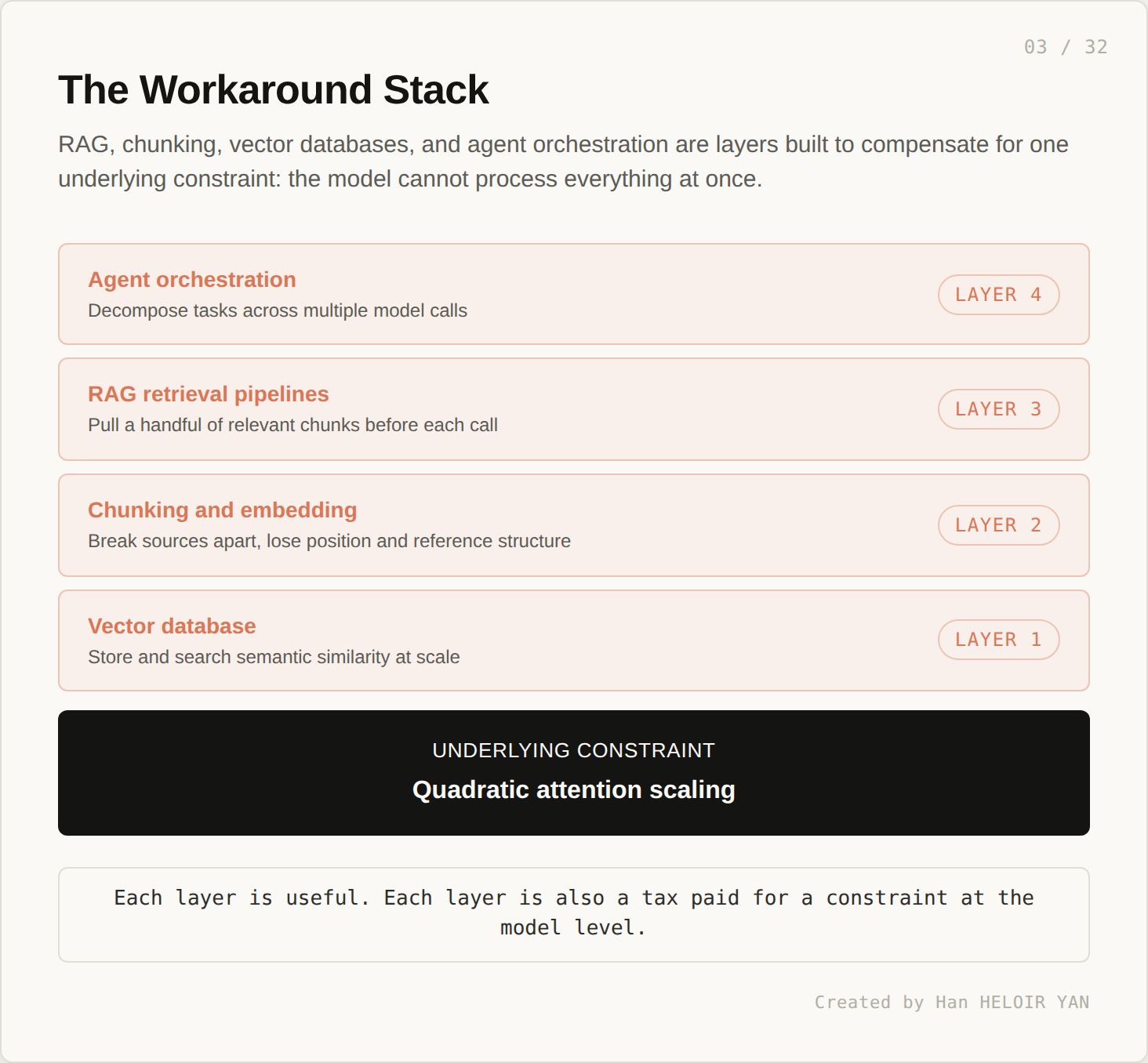
The cost of working around the limit is paid in engineering. You build a vector database. You write chunking strategies. You add a retrieval layer in front of the model. You orchestrate multi step agents to assemble information one slice at a time. Each layer is useful. Each layer is also a tax paid for one underlying constraint at the model level.
If long context becomes truly cheap (not just available, but cheap enough that you would actually use it at production traffic), parts of that stack compress. The promise of SubQ, and of any architecture that breaks the trilemma, is that this compression becomes economically inevitable rather than just technically possible.
Attention is the operation that lets a transformer relate tokens to each other. For one position to update once, it has to ask: which other tokens matter to me, and how much?

Each query token scores its relevance against every other token (the keys), then aggregates the values weighted by those scores. This is a useful operation. It is also an expensive one.
To process a sequence of length n, attention computes an n by n matrix. Every cell is a score between two tokens. The number of comparisons is n squared.
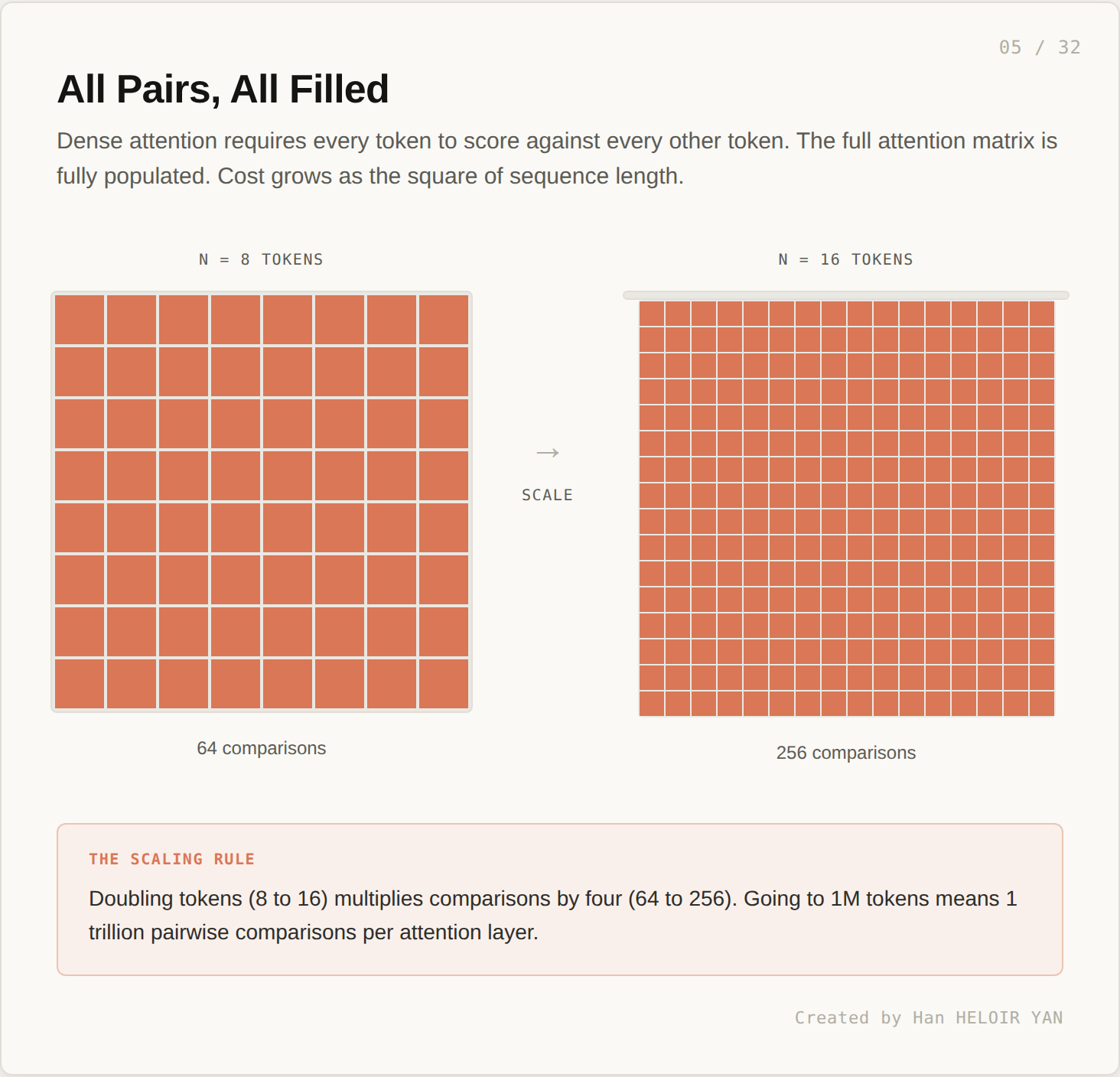
Doubling tokens (8 to 16) multiplies comparisons by four (64 to 256). The pattern looks fine at small sizes. It does not look fine at production scale.
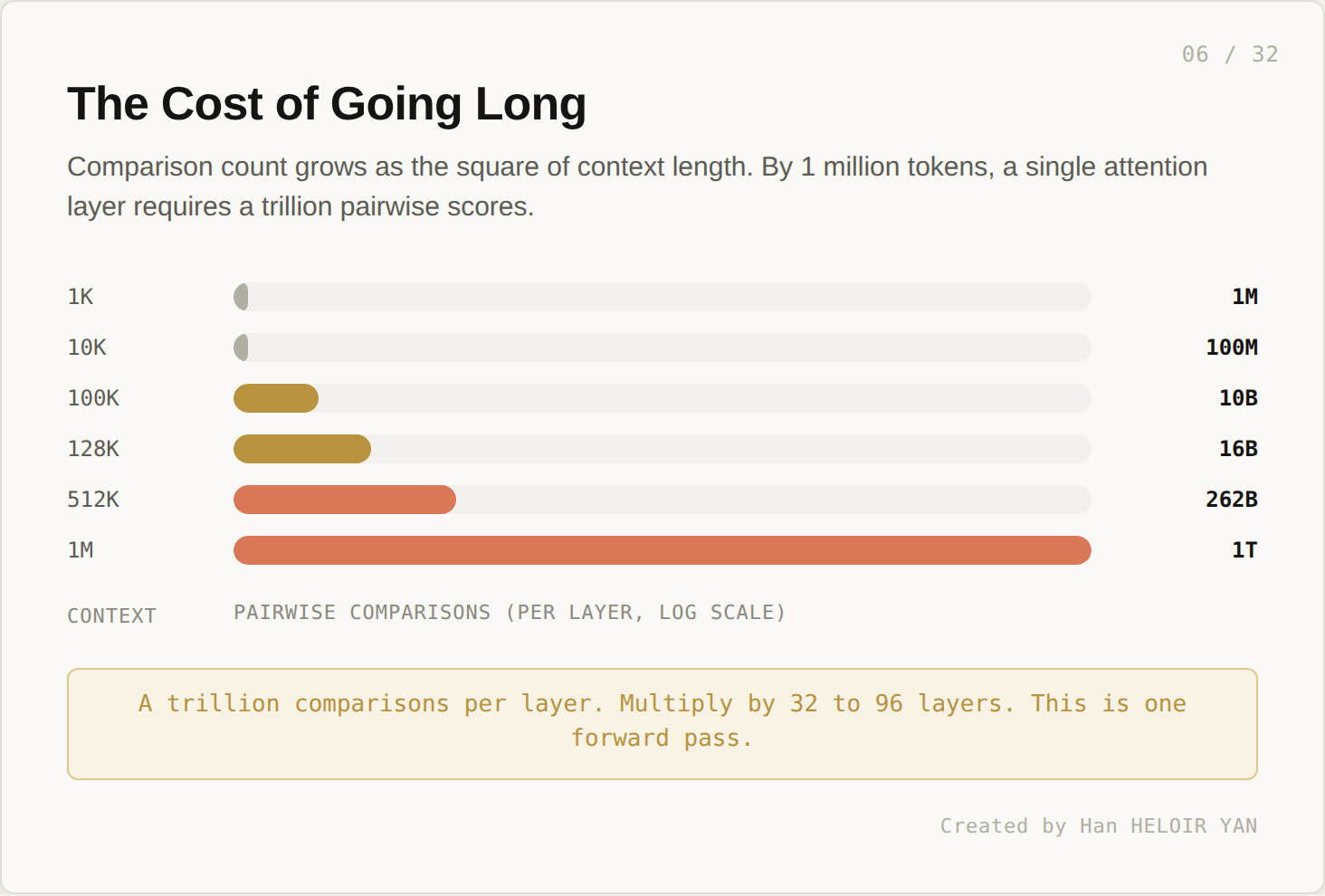
A 1 million token sequence requires roughly a trillion pairwise scores per attention layer. Multiply by 32 to 96 layers in a real model. This is one forward pass. The math has been the central engineering constraint of the field since 2017.
In 2022, FlashAttention from Tri Dao reorganized how this work runs on a GPU. By avoiding the materialization of the full attention matrix in memory and tiling the computation, FlashAttention drove down wall clock time substantially.
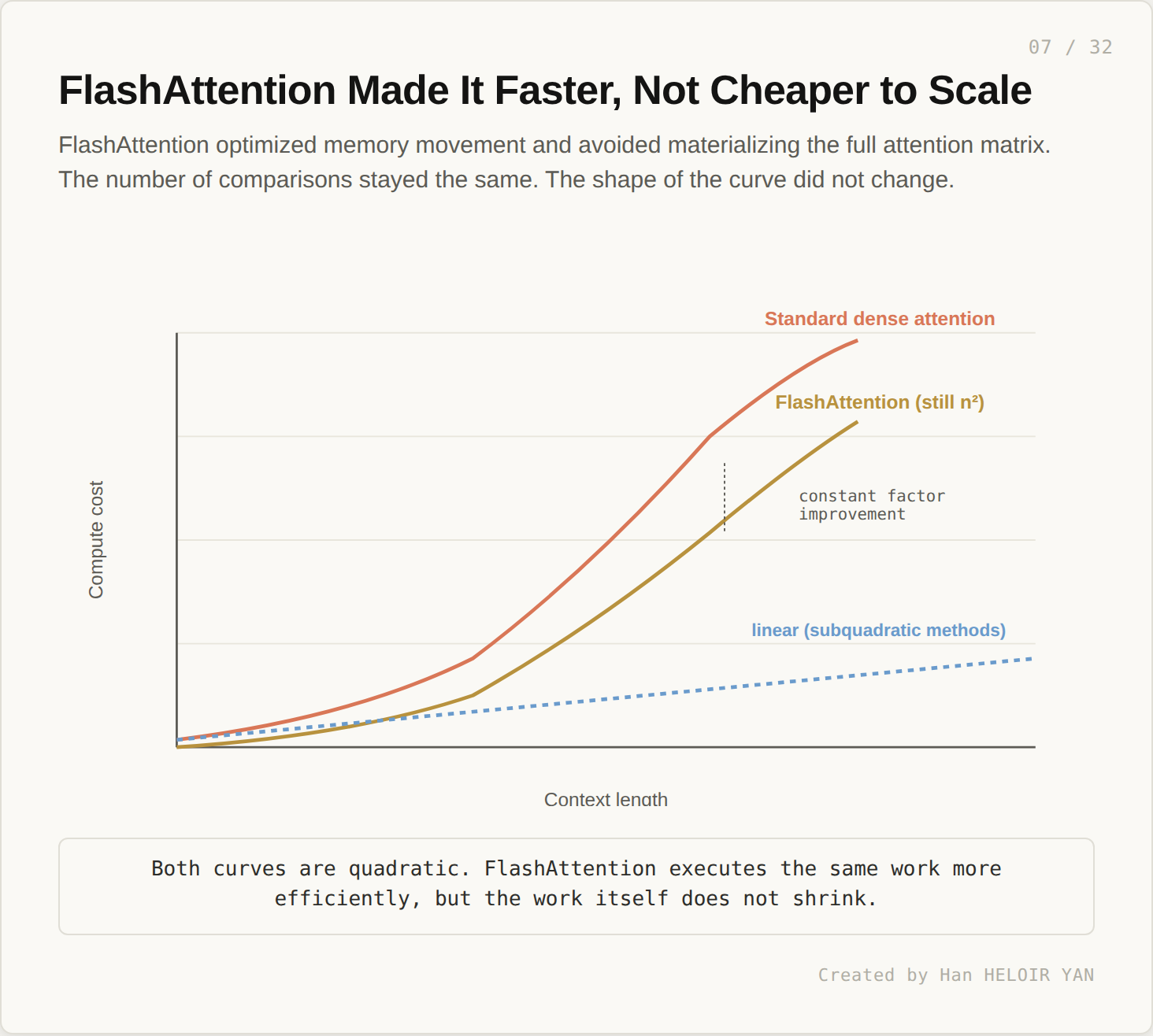
But the work itself did not shrink. FlashAttention executes the same n squared comparisons more efficiently. The shape of the curve stays the same. At 1M tokens, FlashAttention is much faster than the naive version, and it is still in the regime where doubling context quadruples cost.
This is the constraint that everything downstream of the model has to compensate for.
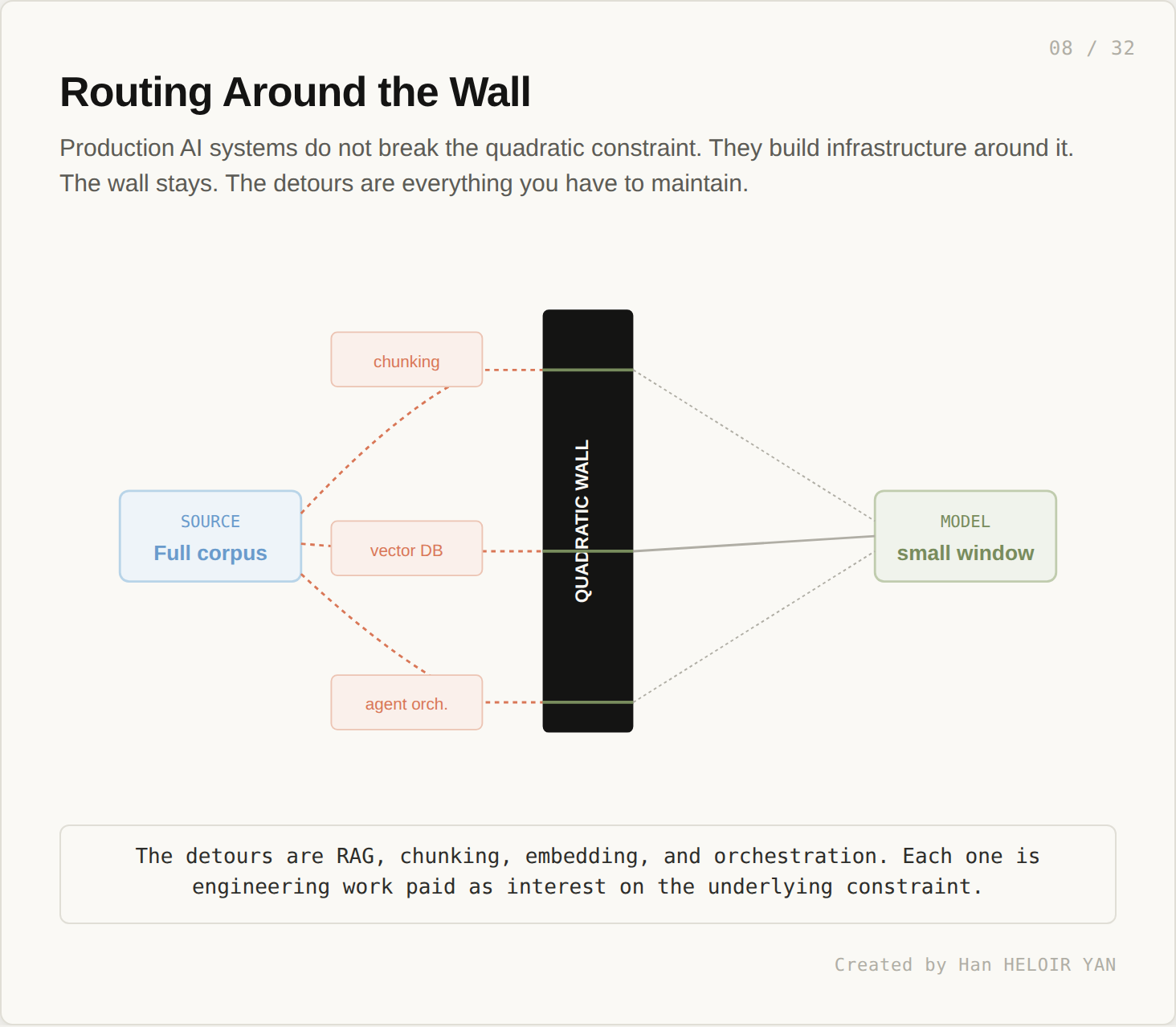
Vector databases, chunking, RAG retrieval, and agent orchestration are not features. They are detours around the quadratic wall. Each is engineering work paid as interest on the model’s underlying constraint. The wall stays. The detours are everything you have to maintain.
The first wave of attempts to break the wall was structural. If most of the attention scores are small or near zero anyway, why compute all of them? Restrict attention to a fixed pattern of positions, decided in advance.
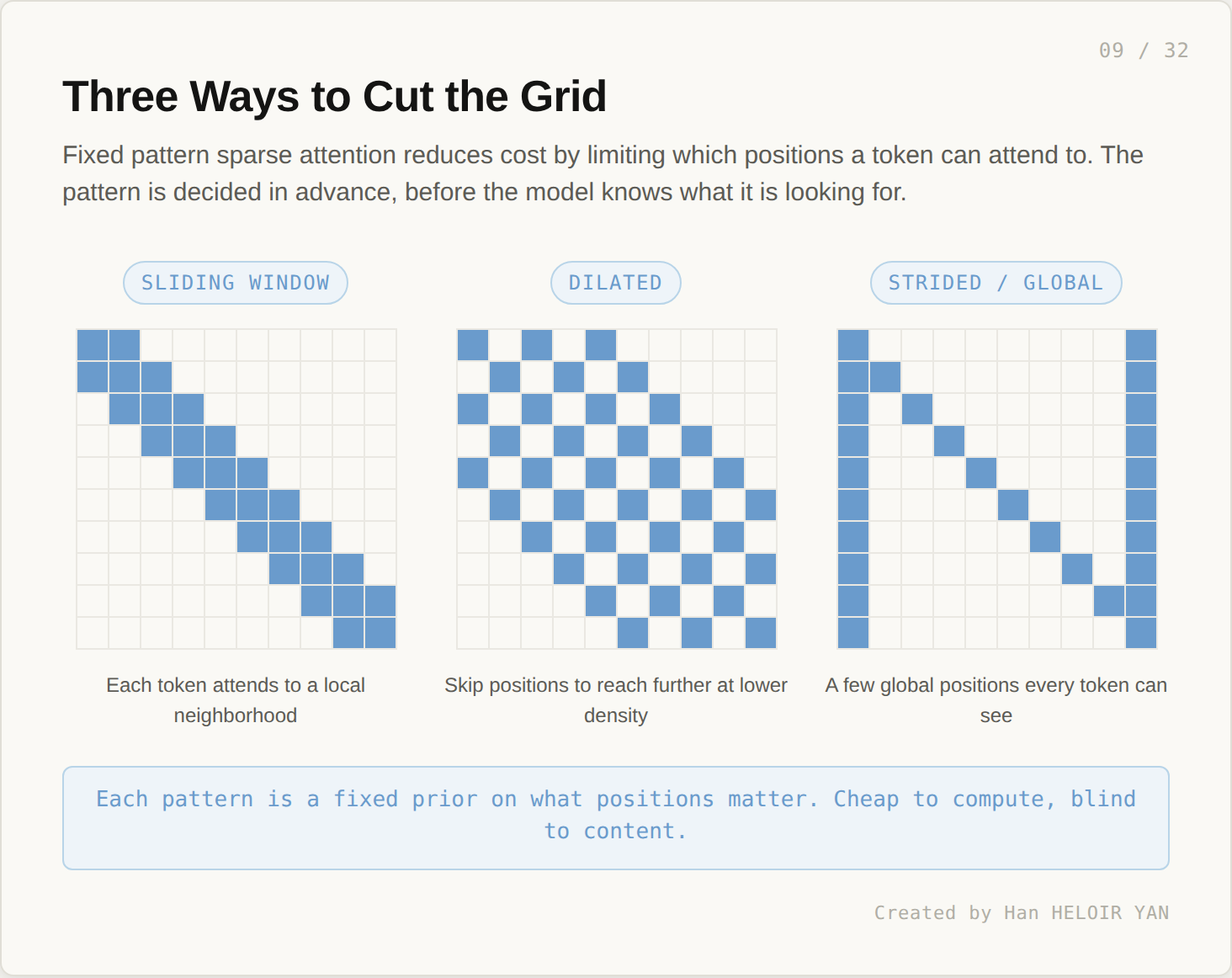
Three patterns dominate the literature: sliding windows (each token attends to a local neighborhood), dilated patterns (skip every k positions to reach further at lower density), and strided or global patterns (a few designated positions every token can see). Each is a different prior on what positions matter. All are cheap to compute. None are content aware.
Of the three, sliding window attention is the simplest and most studied.
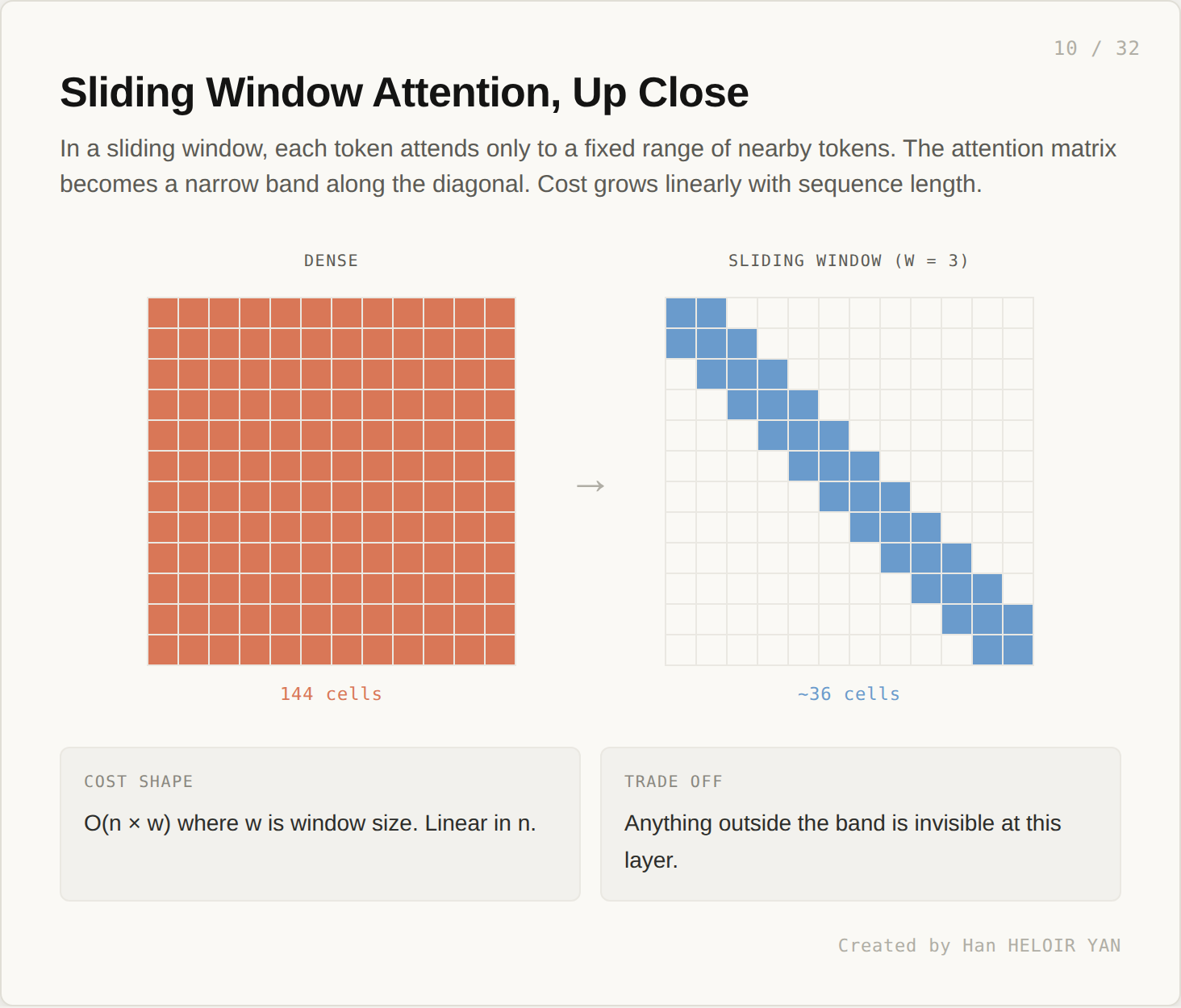
A 12 token sequence with full attention requires 144 cells. With a window of size 3, only about 36 cells are computed. Cost grows as O(n × w) where w is window size. Linear in n.
When Mistral 7B shipped in September 2023, sliding window attention was a leading bet on efficient long context. The architecture is a clean exemplar of the fixed pattern approach.
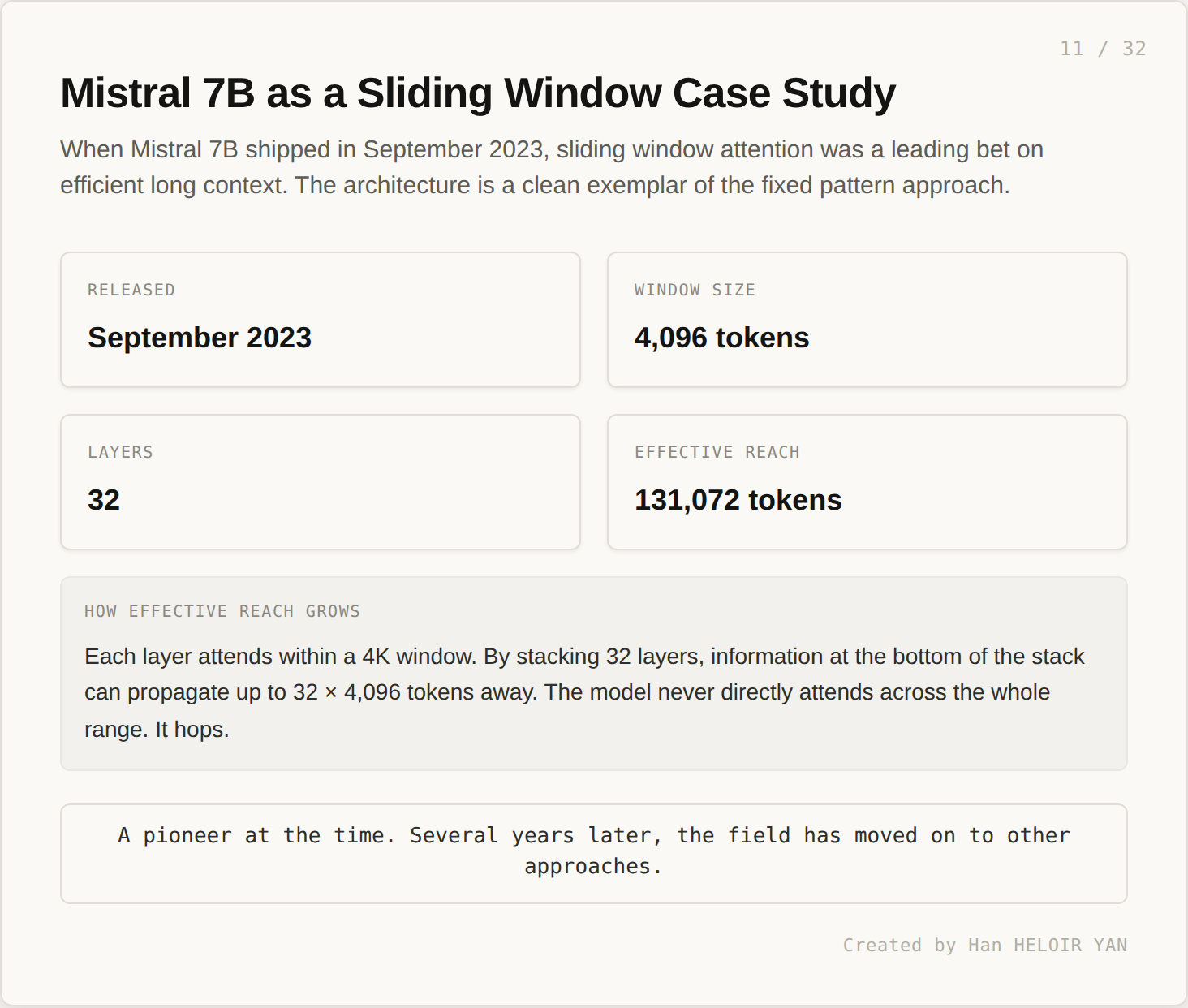
The model paired a 4,096 token sliding window with 32 stacked layers. Effective reach was extended to roughly 131,072 tokens through layer stacking. Information at one position propagates to distant positions by passing through one window per layer.
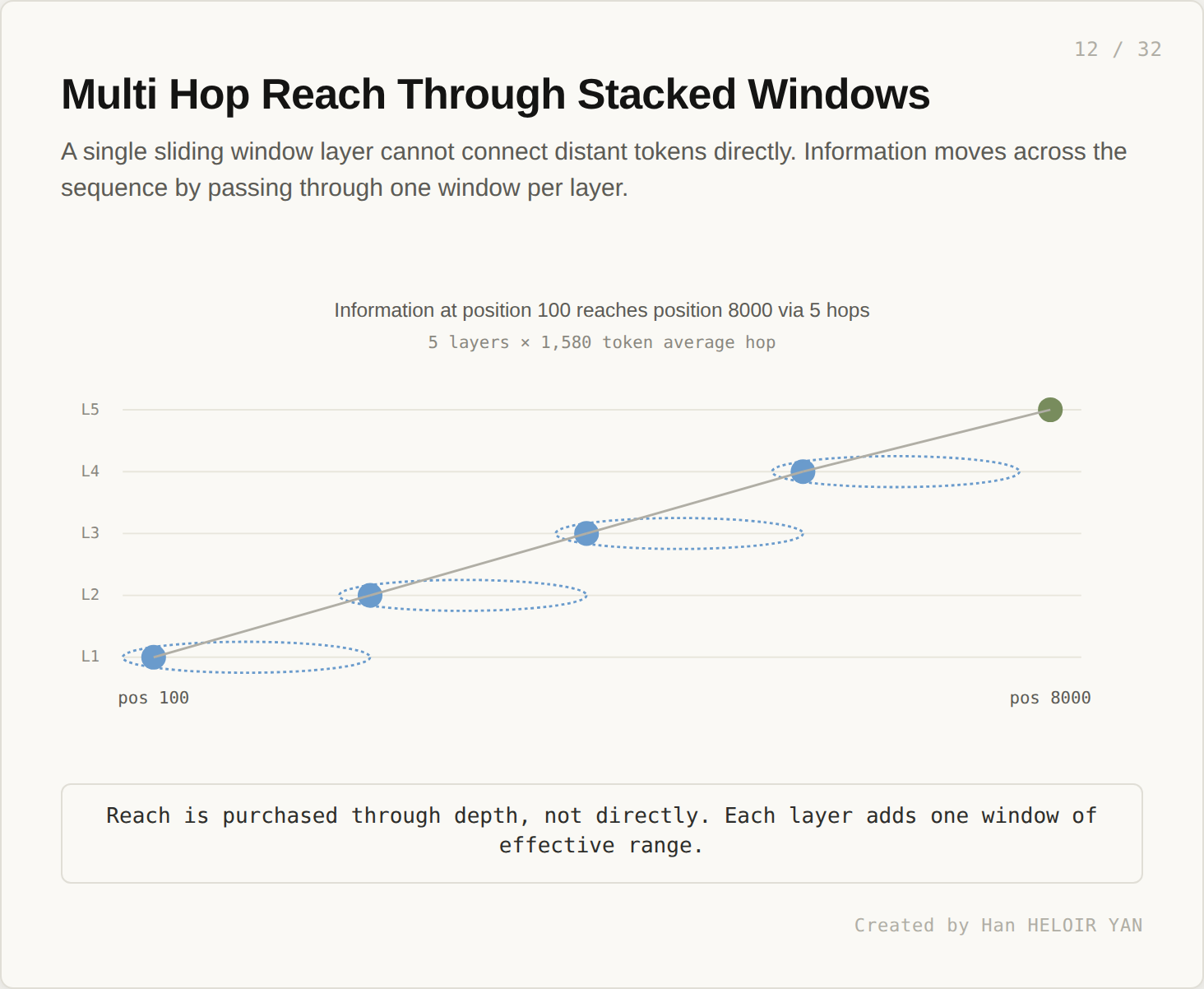
Reach is purchased through depth, not directly. Each layer adds one window of effective range. A token at position 100 reaches a token at position 8000 over five hops, each hop covering about 1,580 tokens.
This works well when the multi hop chain is reliable. It fails when relevant evidence sits outside the window pattern and the chain misses it.
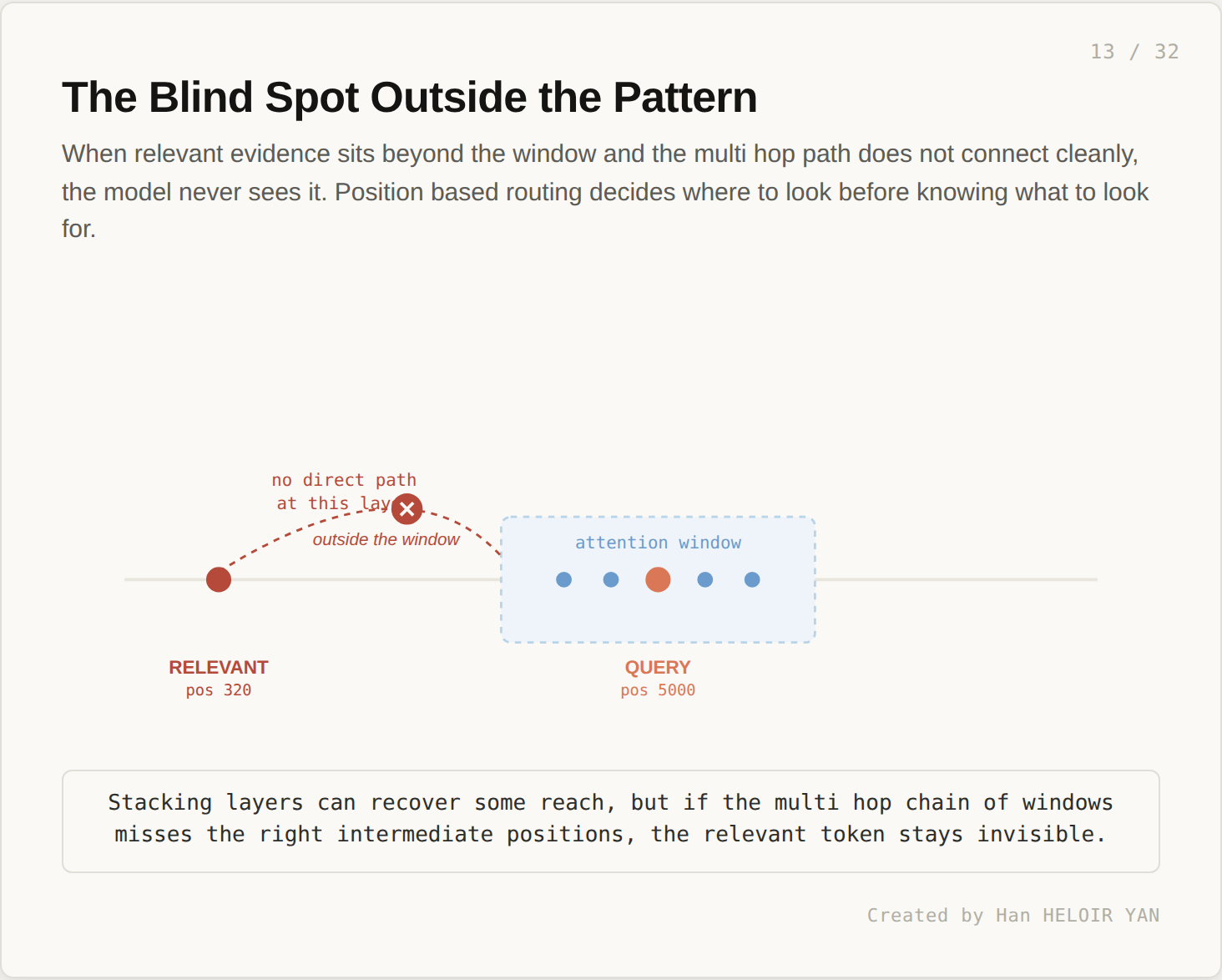
Position based routing decides where to look before knowing what to look for. If the relevant evidence is at position 320 and the query is at position 5000, no single attention layer connects them directly. The model relies on intermediate tokens to carry the information across, and if the chain is weak, the information stays invisible. Mistral 7B was a pioneer at the time. Several years on, the field has continued to explore other approaches.
If pairwise attention is too expensive, drop pairwise comparison entirely. State space models replace the attention matrix with a hidden state that updates sequentially.
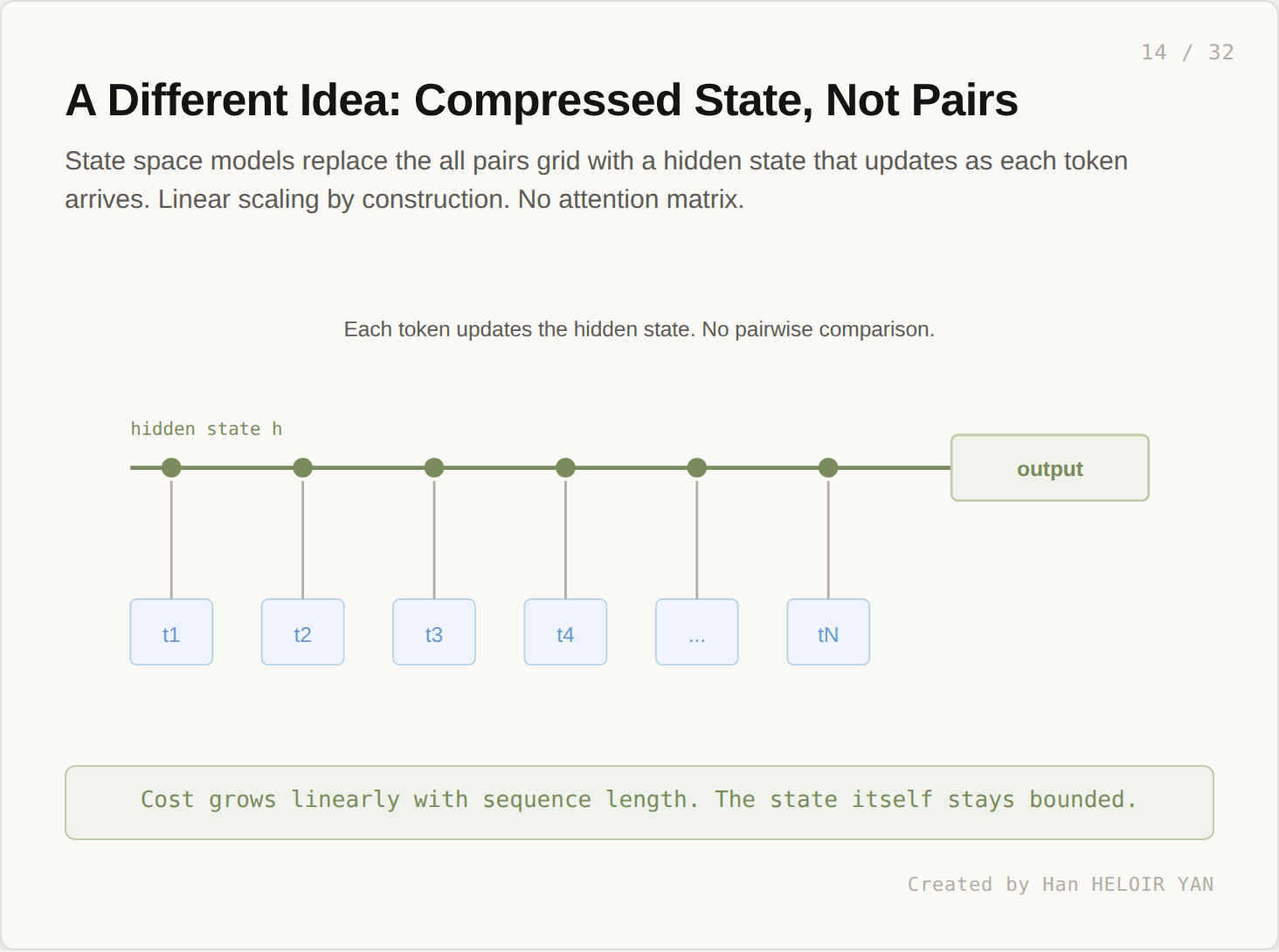
Each token, on arrival, updates a fixed size state vector. There is no n by n grid. Cost grows linearly with sequence length. This was the structural promise of architectures like Linear Attention, S4, and eventually Mamba.
Pure state space models update the state uniformly. Each token influences the state in roughly the same way. This is suboptimal. Some tokens (a sudden topic shift, a numeric value, a named entity) deserve more weight than others. Mamba, introduced by Albert Gu and Tri Dao in late 2023, added content gating to the state update. The model decides per token how much each input influences the state.

A sentence like “the price is $42 per unit” should not update the state evenly. The numeric value matters more than the article. Mamba routes more update strength to the high signal tokens. Linear scaling stays. Selectivity gets added.
Codestral Mamba, released in July 2024, was one of the early production scale Mamba based models.
The model demonstrated that a pure state space backbone could handle code generation at competitive quality, with linear inference time. It tested at 256K context. The release validated the SSM family as production viable for at least one workload class. Another early bet in the efficient attention space. The field has continued to evolve since.
The constraint that comes with state space models is fundamental. The state has fixed capacity. Every new token has to fit into the same container.

At 10K tokens, the state can carry the full sequence. At 100K, it carries a summary. At 1M, it carries a compression. At 10M, the compression is so aggressive that specific facts become probabilistic to recover.
This shows up in benchmarks as recall decay.
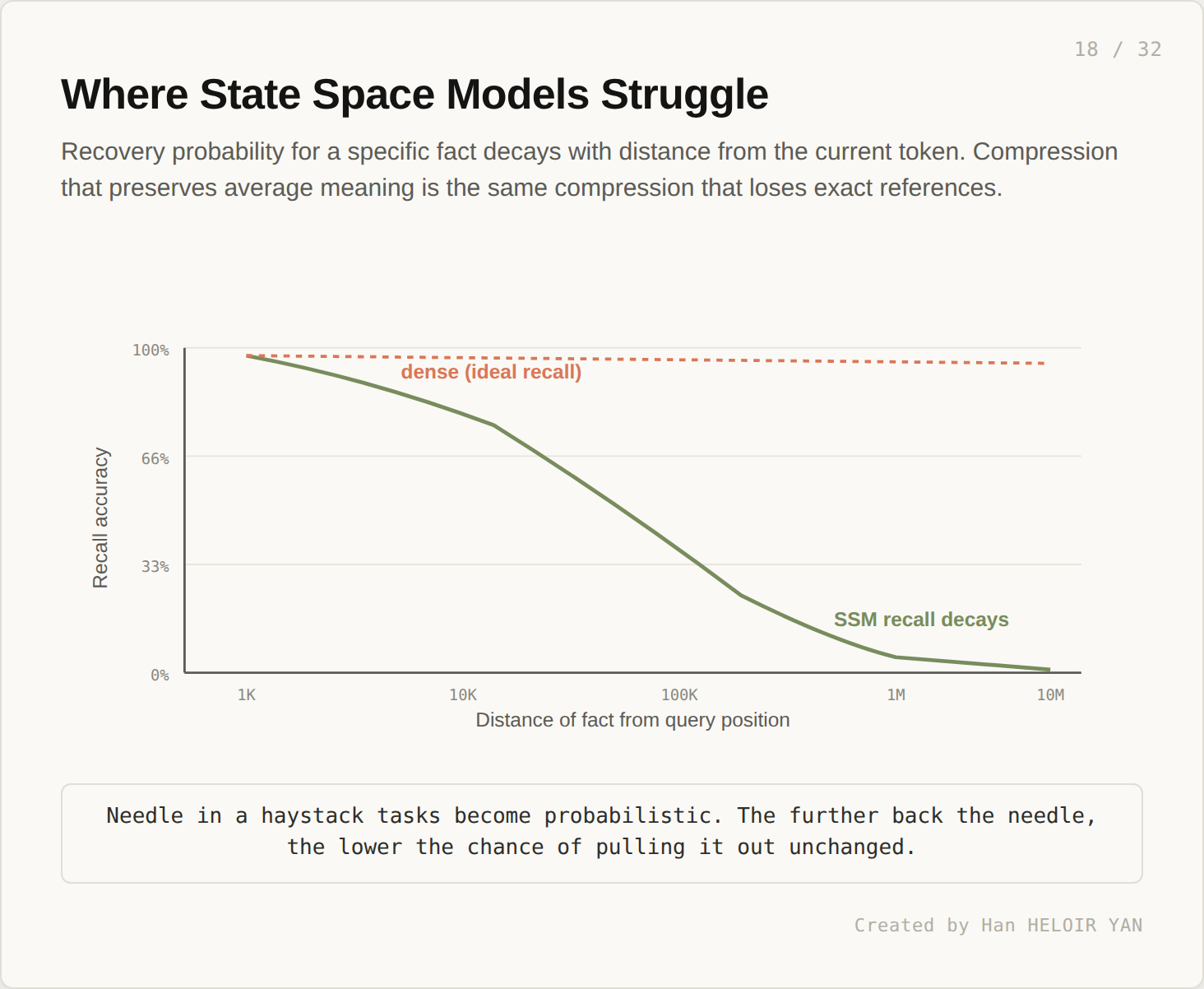
For an exact fact at distance d from the current token, recall accuracy drops as d grows. Gist and structure survive. Specific values introduced far back in the sequence become harder to recover unchanged. Needle in haystack tasks become probabilistic. Mamba style models are linear and content aware. They are not designed for arbitrary position retrieval at very long distances.
If state space models compress too aggressively for some workloads, and dense attention is too expensive, the obvious idea is to mix them. Use efficient layers for most of the model. Use a handful of dense layers to preserve retrieval.

Recent hybrid models like Jamba interleave layer types. The split varies: 1 dense layer per 4, or 1 per 8, or only at strategic depths in the stack. The intuition is that the efficient layers carry the bulk of computation while the dense layers handle the retrieval that pure SSMs struggle with.
The math here is interesting. The efficient layers carry most of the parameter count. The dense layers carry most of the asymptotic compute.
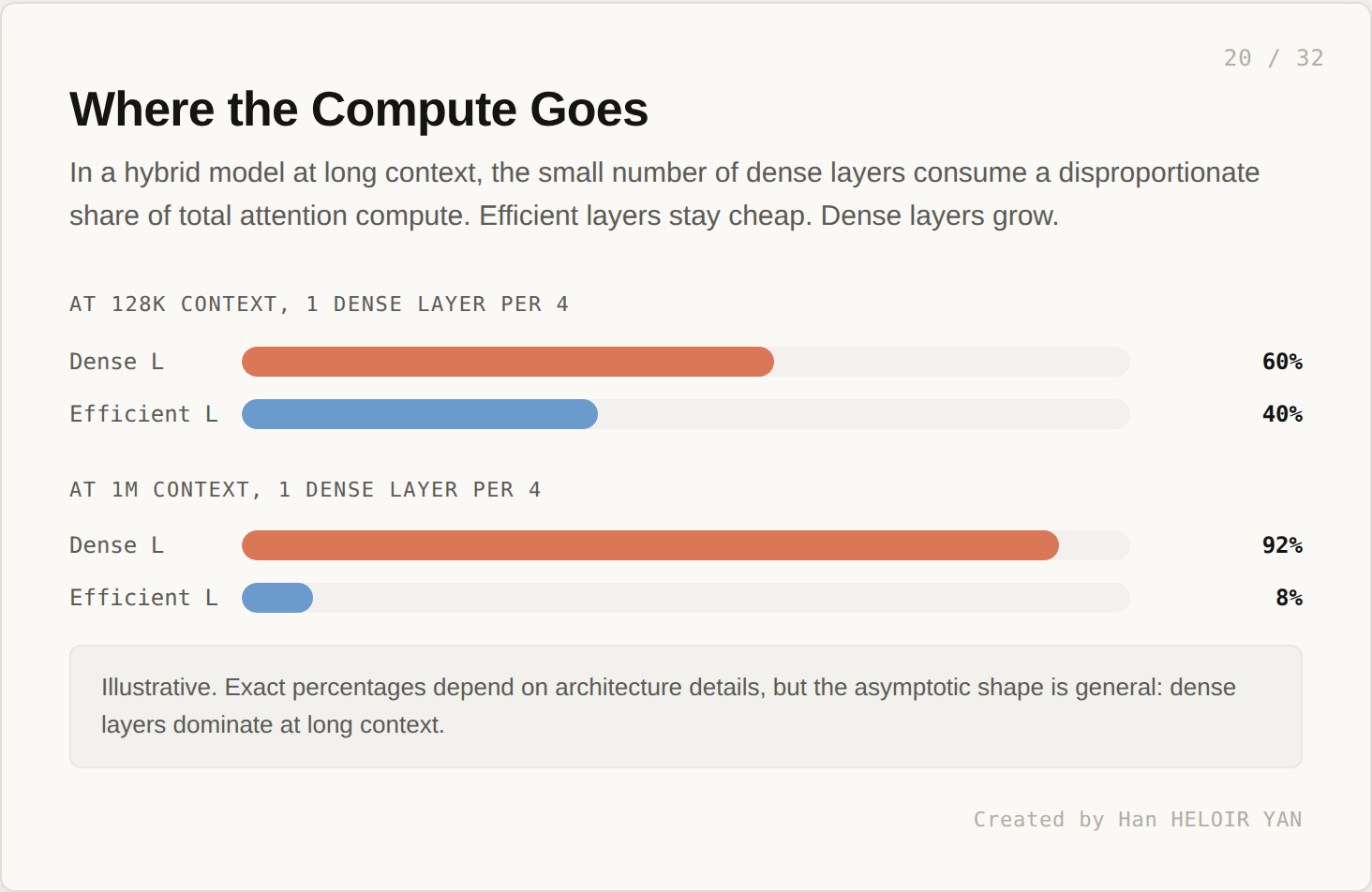
At moderate context (128K) with 1 dense layer per 4, the dense layers might consume 60% of attention compute. Already disproportionate. At 1M context, the same configuration sees dense layers consume more than 90% of compute. The few quadratic layers swamp the cost savings of the many linear layers.
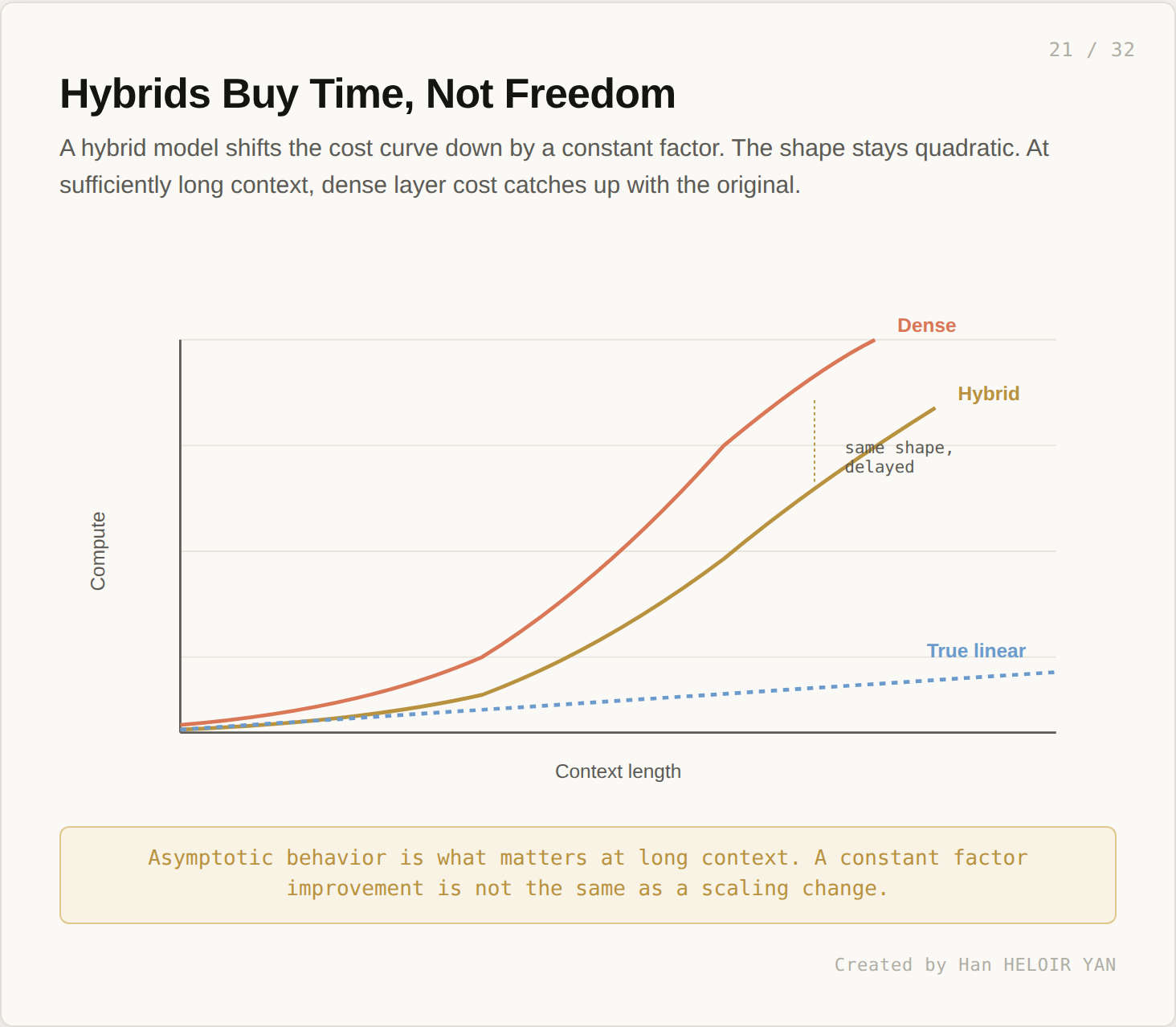
The cost curve still bends quadratically. It bends later, but it bends. A hybrid model is a constant factor improvement over a fully dense one. At sufficiently long context, the fully dense curve and the hybrid curve converge in shape, even if they sit at different absolute levels.
A hybrid architecture is a real engineering improvement. It does not change the asymptotic regime. Asymptotic behavior is what matters at the long context lengths where this conversation is interesting.
The most recent prior attempt before SubQ is DeepSeek’s Sparse Attention, introduced with the DeepSeek V3.2 release. DSA looks like it solves the problem. It does not, quite.
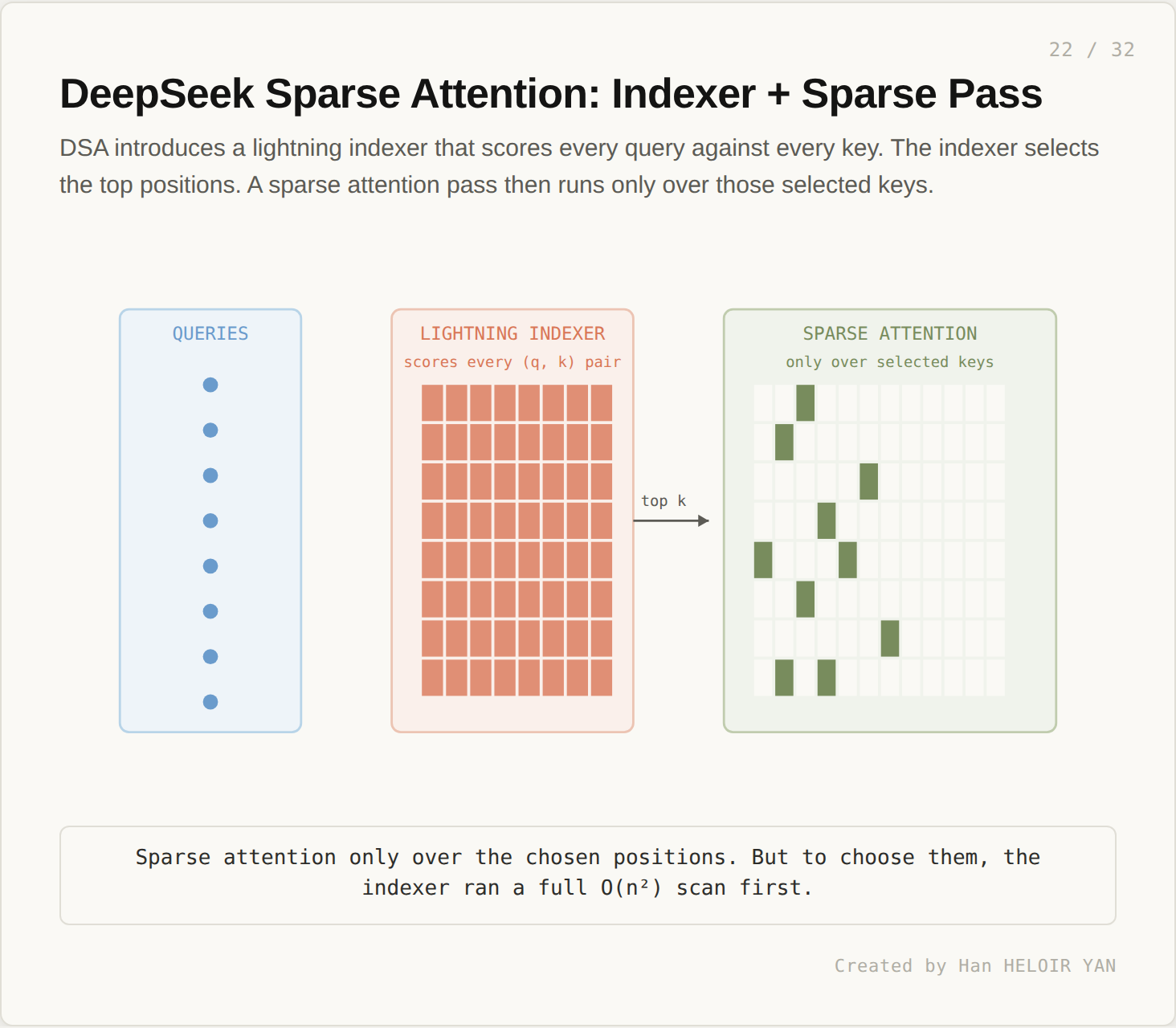
DSA introduces a lightning indexer. The indexer scores every query against every key, but with a smaller per pair operation than full attention. After scoring, the indexer selects the top k positions. A sparse attention pass then runs only over the selected keys.
This sounds subquadratic. It is not.
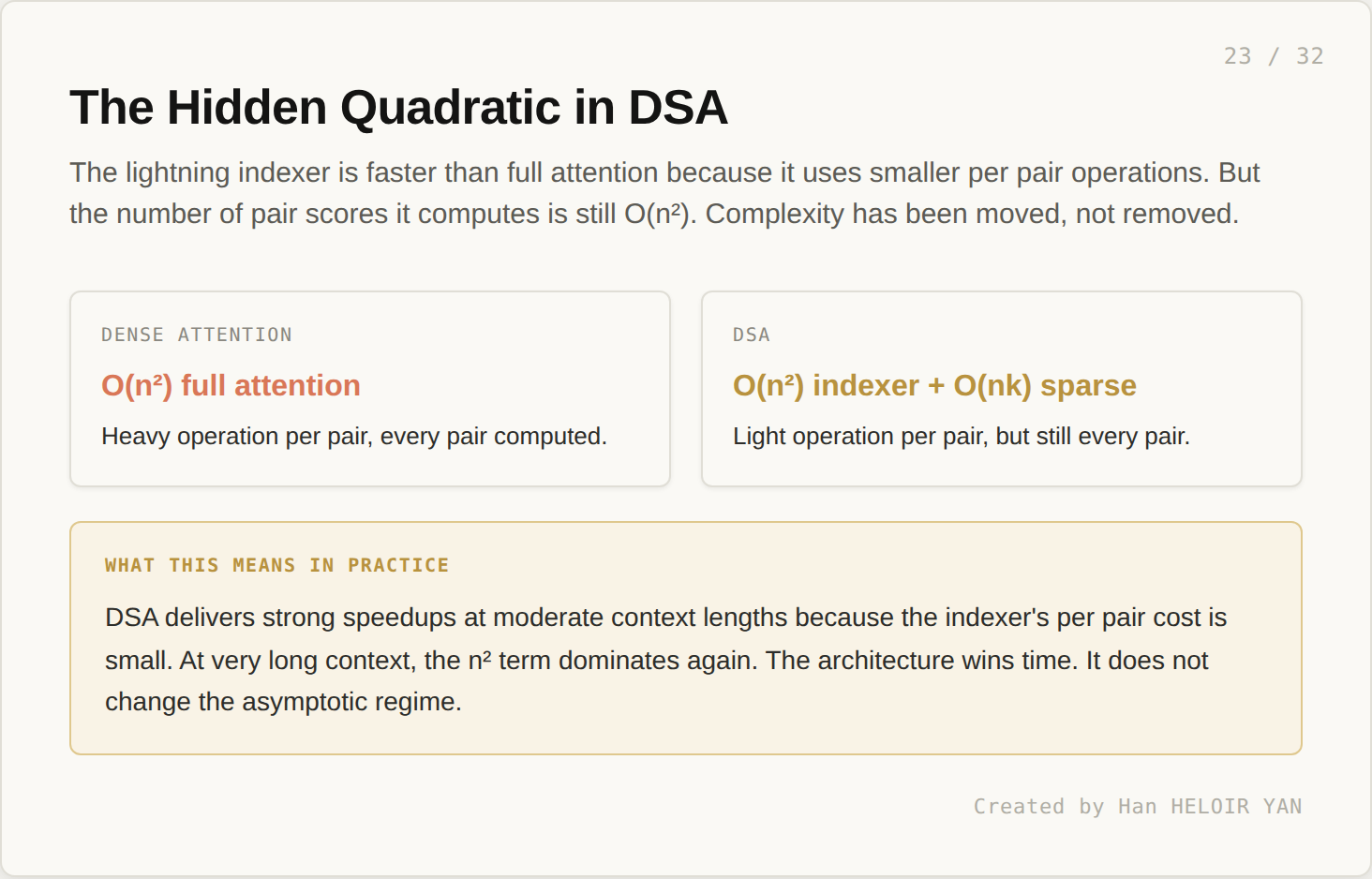
Dense attention is O(n²) full attention: heavy operation per pair, every pair computed. DSA is O(n²) indexer plus O(nk) sparse: light operation per pair, but still every pair. The number of pairs scored has not changed. Only the per pair cost. Complexity has been moved, not removed.
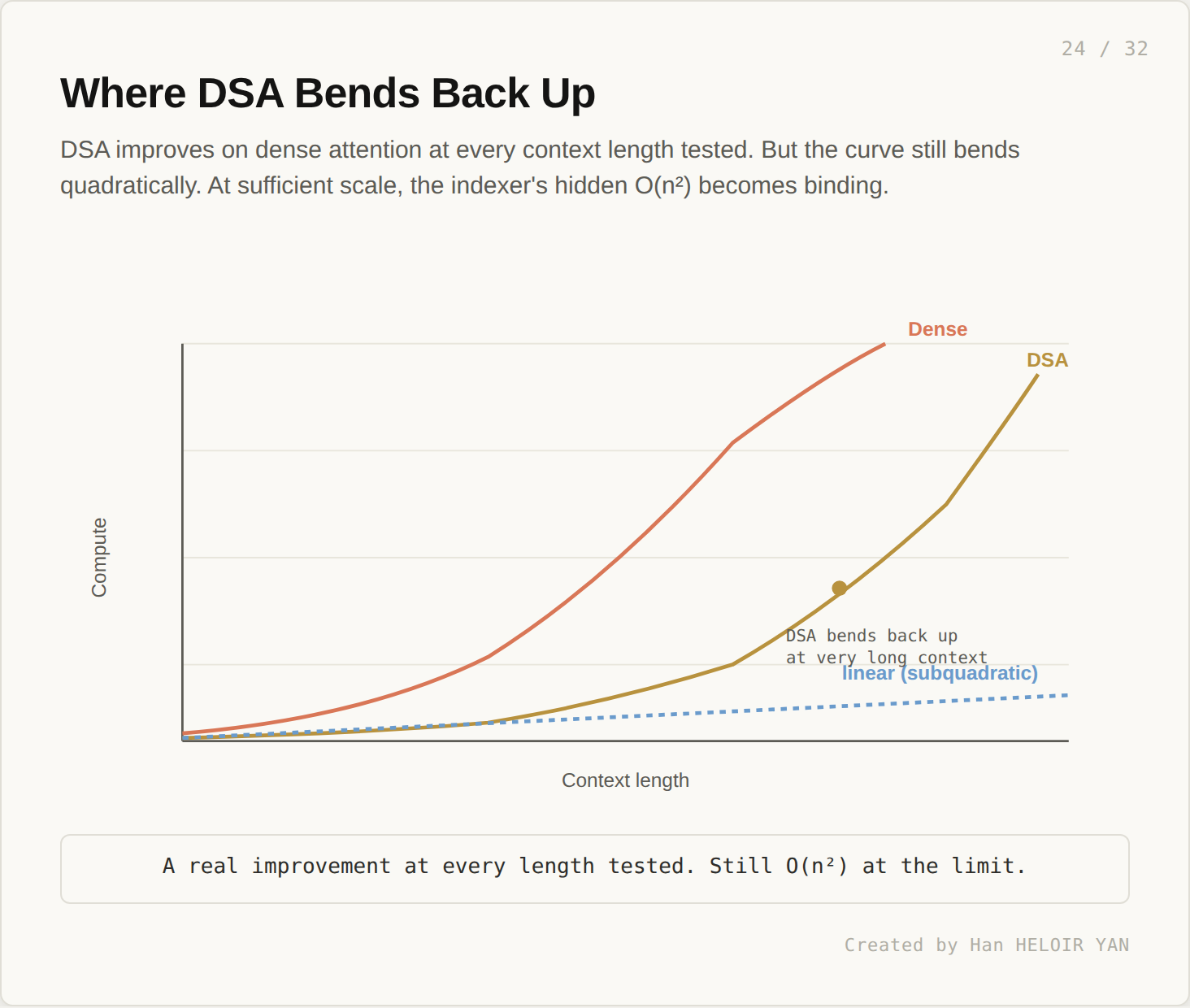
DSA delivers strong speedups at moderate context lengths because the indexer’s per pair cost is small. At very long context, the n squared term dominates again. The architecture wins time. It does not change the asymptotic regime. A real improvement at every length tested. Still O(n²) at the limit.
This is the architectural claim that distinguishes SubQ from everything that came before.
Subquadratic Sparse Attention selects which positions to attend to based on content, but the selection itself is subquadratic. The architecture does not score every (q, k) pair as a precondition to choosing the relevant ones.
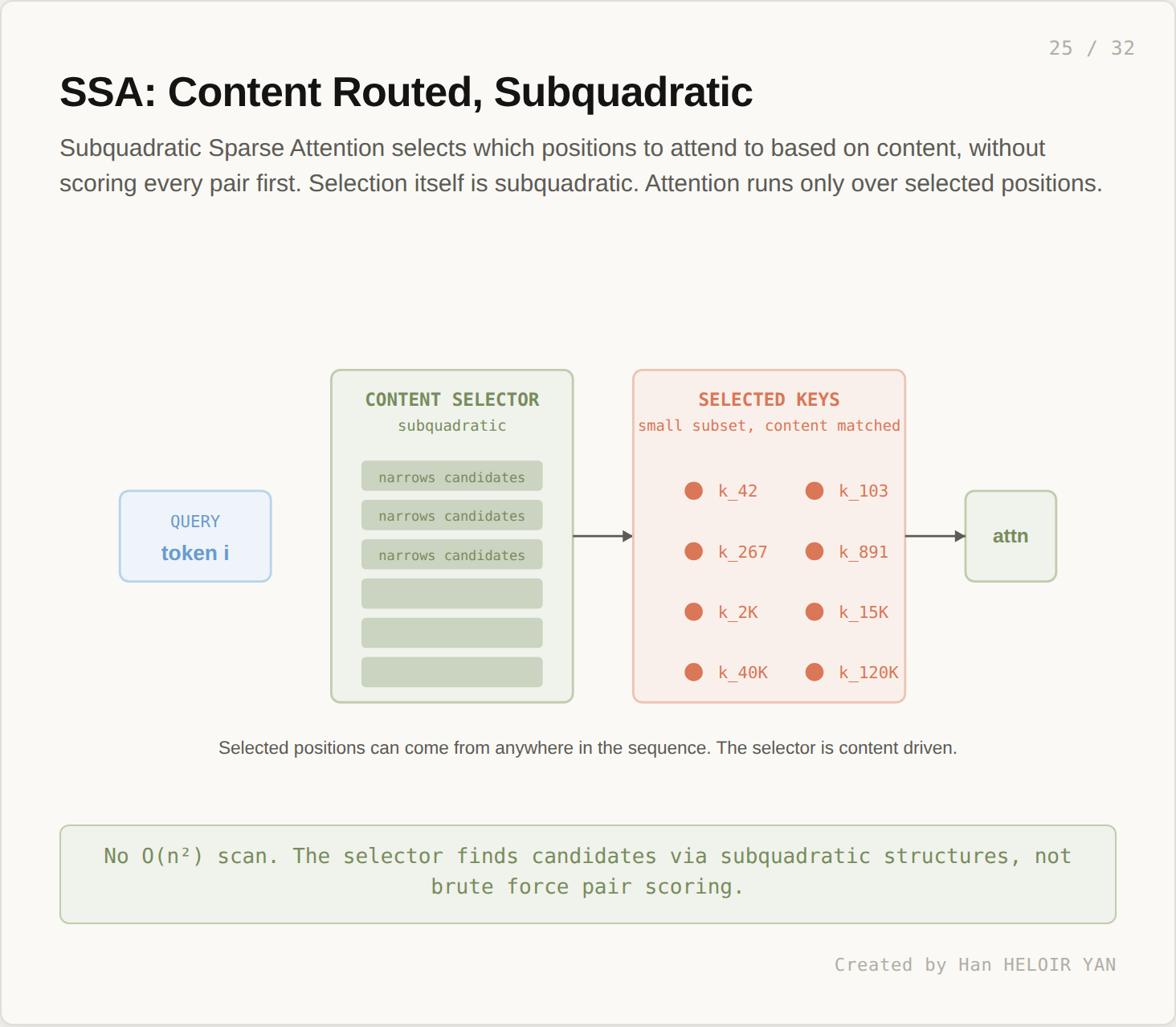
The SSA selector narrows the candidate set through structures that scale better than n². Hash based lookup, hierarchical clustering, learned routing: the public technical paper from Subquadratic describes the mechanism in detail. The selected positions can come from anywhere in the sequence. Selection is content driven. The mechanism is what differentiates SSA from DSA: in DSA, the indexer still touches every pair (with a cheaper operation per pair). In SSA, the selector reaches the right positions without ever scanning all of them.
If the claim holds, SSA is the first architecture to deliver all three trilemma properties at once.
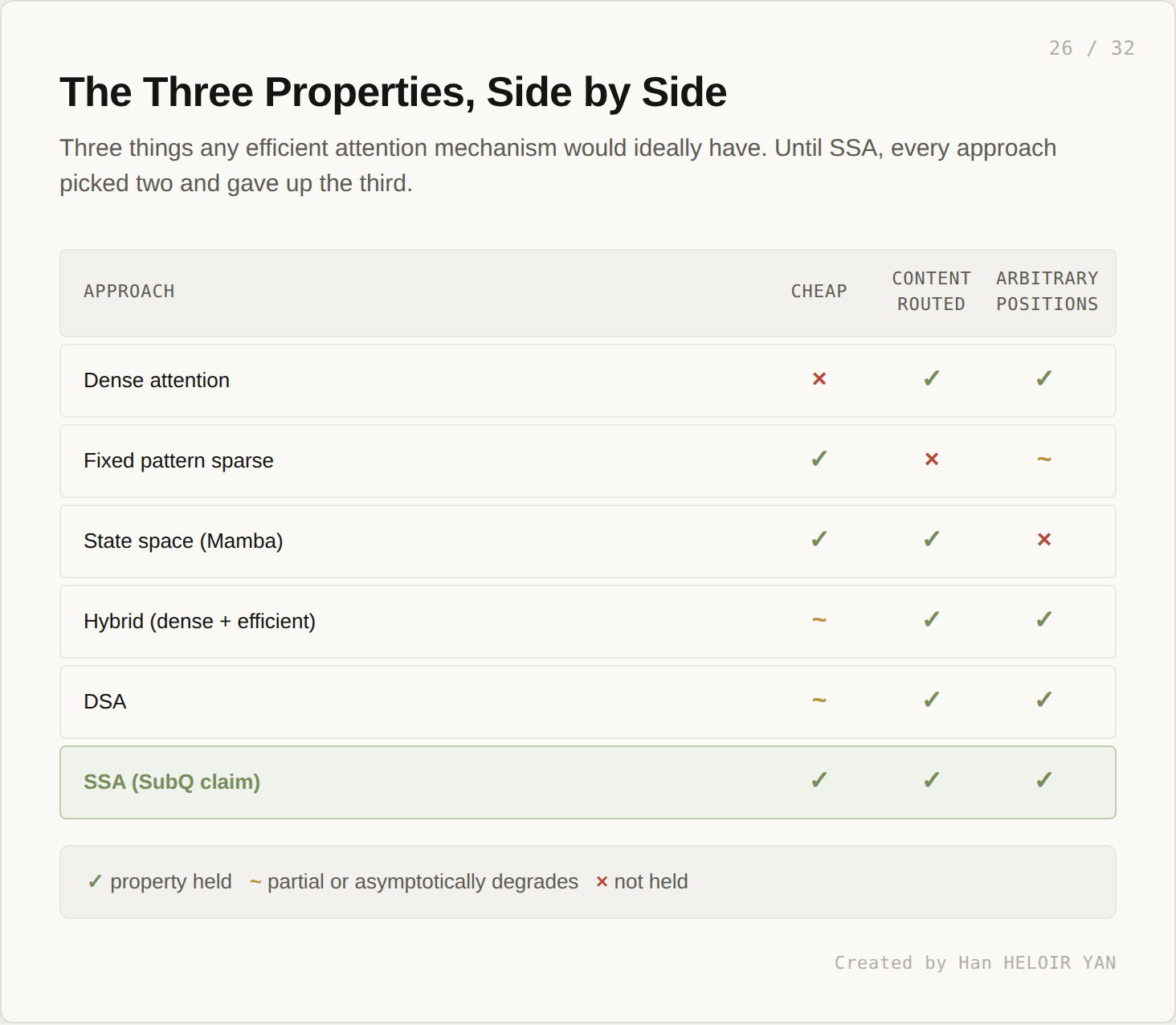
Dense attention is content routed and arbitrary positions, but expensive. Sliding window is cheap and arbitrary positions (asymptotically, through stacking), but blind to content outside the pattern. State space is cheap and content routed, but compresses arbitrary positions away. Hybrids and DSA are improvements, but neither is asymptotically subquadratic. SSA, as claimed, is all three.
The reported speedups are aggressive.
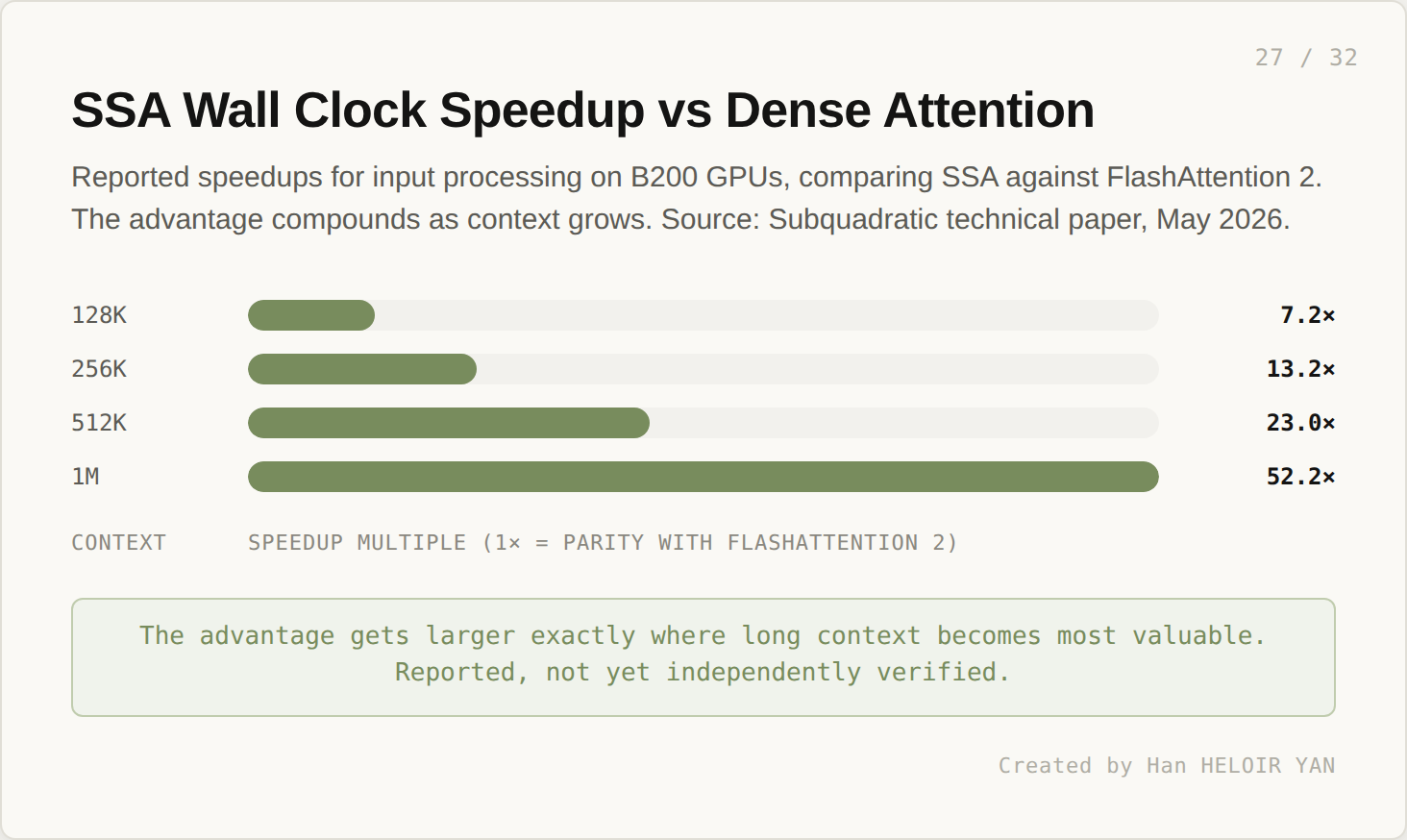
On B200 GPUs, comparing SSA against FlashAttention 2: 7.2x faster at 128K, 13.2x at 256K, 23.0x at 512K, 52.2x at 1M. The advantage gets larger exactly where long context becomes most valuable. These numbers are reported by Subquadratic. Independent verification is pending.
Wall clock speedup depends on hardware. Hardware independent: FLOP reduction.
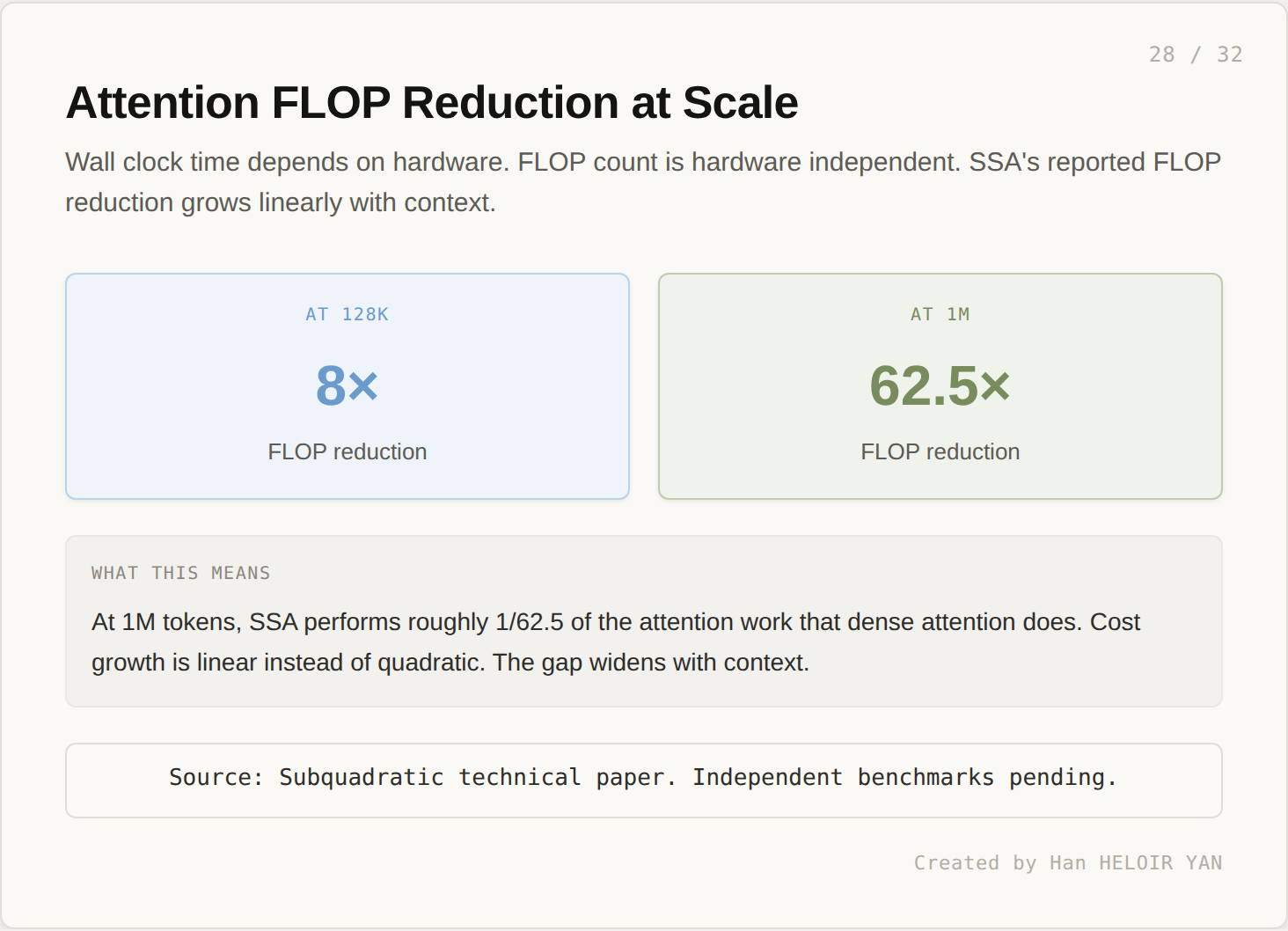
At 128K, SSA performs roughly 1/8 the attention FLOPs of dense attention. At 1M, the ratio grows to 1/62.5. Cost growth is linear instead of quadratic. The gap widens with context.
Quality benchmarks are mixed.
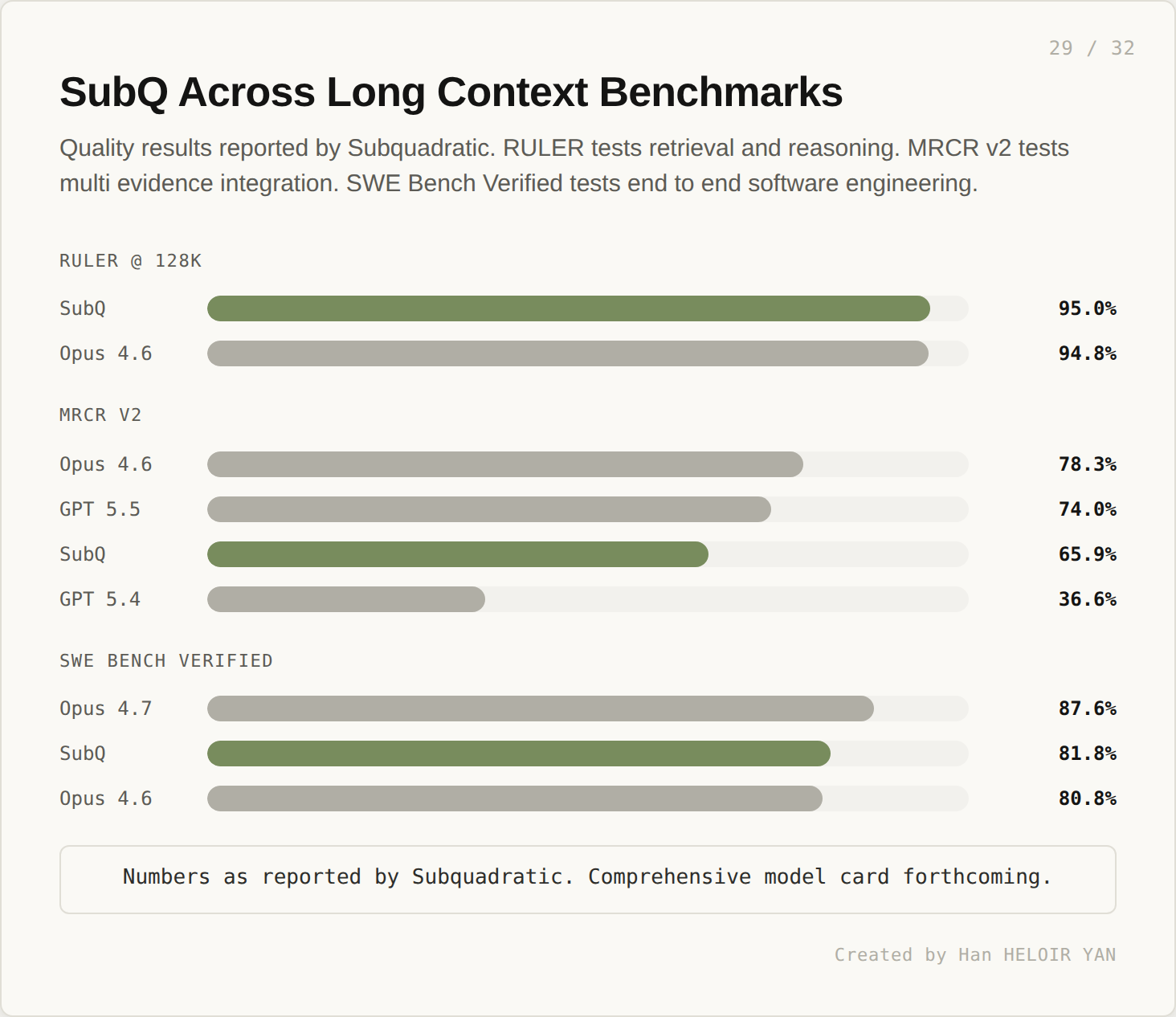
On RULER at 128K, SubQ scores 95.0%, in parity with Claude Opus 4.6 at 94.8%. On MRCR v2 (multi evidence integration), SubQ scores 65.9%, behind Opus 4.6 (78.3%) and GPT 5.5 (74.0%) but ahead of GPT 5.4 (36.6%). On SWE Bench Verified, SubQ scores 81.8%, behind Opus 4.7 at 87.6% but ahead of Opus 4.6 at 80.8%. The picture is uneven: strong long context retrieval, mid pack multi document reasoning, competitive but not leading agentic coding.
The CTO of Subquadratic, Alex Whedon, has confirmed publicly that the model uses an open weights base (Kimi or DeepSeek were named as candidates) as a starting point for training, with SSA grafted onto the architecture. Post training is Subquadratic’s own. A comprehensive model card is forthcoming.
Three properties define the design space for efficient attention. Subquadratic compute (cost grows slower than n²). Content routing (the model decides what to attend to based on what it sees, not where things sit). Arbitrary position retrieval (the model can recover specific information from anywhere in the sequence, including the deep past).

Each prior approach picks two of three. Sliding window: subquadratic and arbitrary positions (through stacking), not content routed. State space: subquadratic and content routed, not arbitrary positions. Hybrid: content routed and arbitrary, but quadratic at the limit. DSA: content routed and arbitrary, but quadratic at the limit. Dense attention: content routed and arbitrary, but emphatically not subquadratic.

The interior of the triangle is where SSA claims to sit. If the claim holds, this is the first time all three corners get held simultaneously at the asymptotic limit. That is the architectural claim worth tracking. The benchmarks, the open weights base, the specific MRCR v2 number: those are details. Whether the trilemma actually breaks is the structural question.
Suppose for a moment that SubQ specifically delivers, or that someone else delivers SSA’s properties soon. What changes?
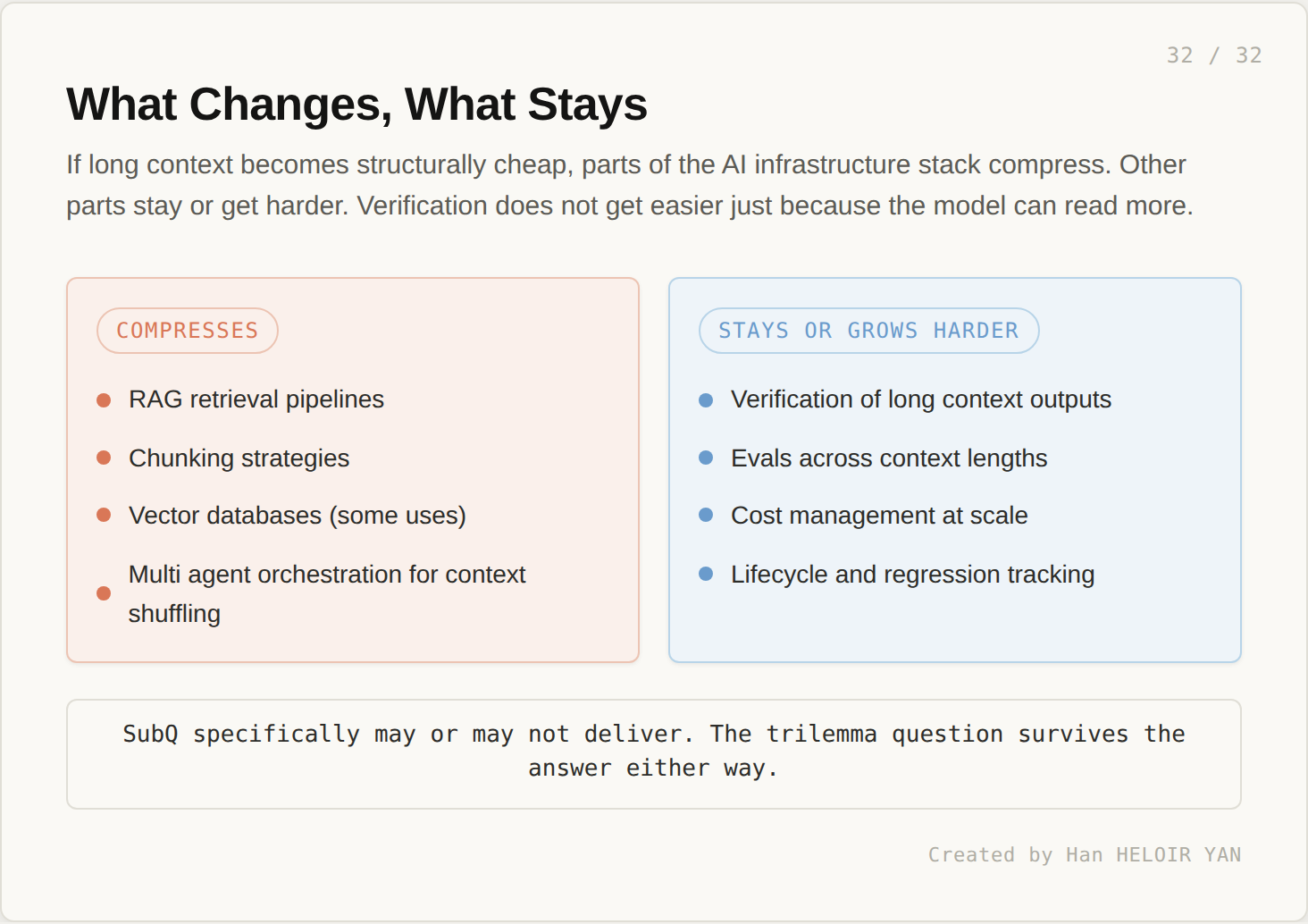
What compresses: RAG retrieval pipelines, chunking strategies, vector databases (for some uses), and multi agent orchestration whose primary purpose is to shuffle context in and out of a small window. These exist to compensate for the model’s limited reach. If the model’s reach is no longer limited, the compensating layers compress accordingly. Some of this infrastructure goes away. Most of it gets reduced to specific cases where it still earns its place.
What stays the same or gets harder: verification of long context outputs, evals across context lengths, cost management at scale, and lifecycle and regression tracking. A 12 million token forward pass produces a 12 million token decision space. Verifying that the model correctly used all that context is harder, not easier, than verifying a 128K decision. The harness gets more, not less, important.
This is the part that does not get said often enough in the launch coverage. A bigger window does not mean less infrastructure. It means different infrastructure. The kind of work the surrounding system does shifts. The total amount does not necessarily shrink.
SubQ specifically may or may not deliver. The benchmarks are reported by the vendor. The model card is forthcoming. Independent evaluation is the next milestone, and the gap between vendor numbers and independent reproduction is where most architectural claims get tested. But the trilemma question survives the answer either way. If SubQ delivers on its claim, the field has a new baseline. If SubQ does not, the next attempt will inherit the same target. Either way, the question of whether all three corners can be held simultaneously is now active in a way it has not been since 2017.