What 244 pages of evaluations reveal about where Anthropic moved the moat line.
Before we start!🦸🏻♀️ If this helps you ship better AI systems:
👏 Clap 50 times (yes, you can!) — Medium’s algorithm favors this, increasing visibility to others who then discover the article.
🔔 Follow me on Medium, LinkedIn and subscribe to get my latest article.
The upgrade you ran this week made your agent less robust to prompt injection, not more. It also made it better at writing exploits, not worse. On the raw checkpoint, Opus 4.8 sits behind Opus 4.7 on injection and ahead of it on offensive cyber.
The reason your production agent is still safe has nothing to do with the weights. Anthropic measured the gap both ways, in the same document, and the measurement is the most important thing in the card. The model regressed. The harness shipped.
The newer model is the less robust one, and they said so in the executive summary.
Most people read a system card looking for the line that says the new model is safer. This card does not give you that line for agentic robustness. It gives you the opposite, in plain text, near the top: Opus 4.8 is somewhat less robust than Opus 4.7 in several agentic contexts, prompt injection among them.
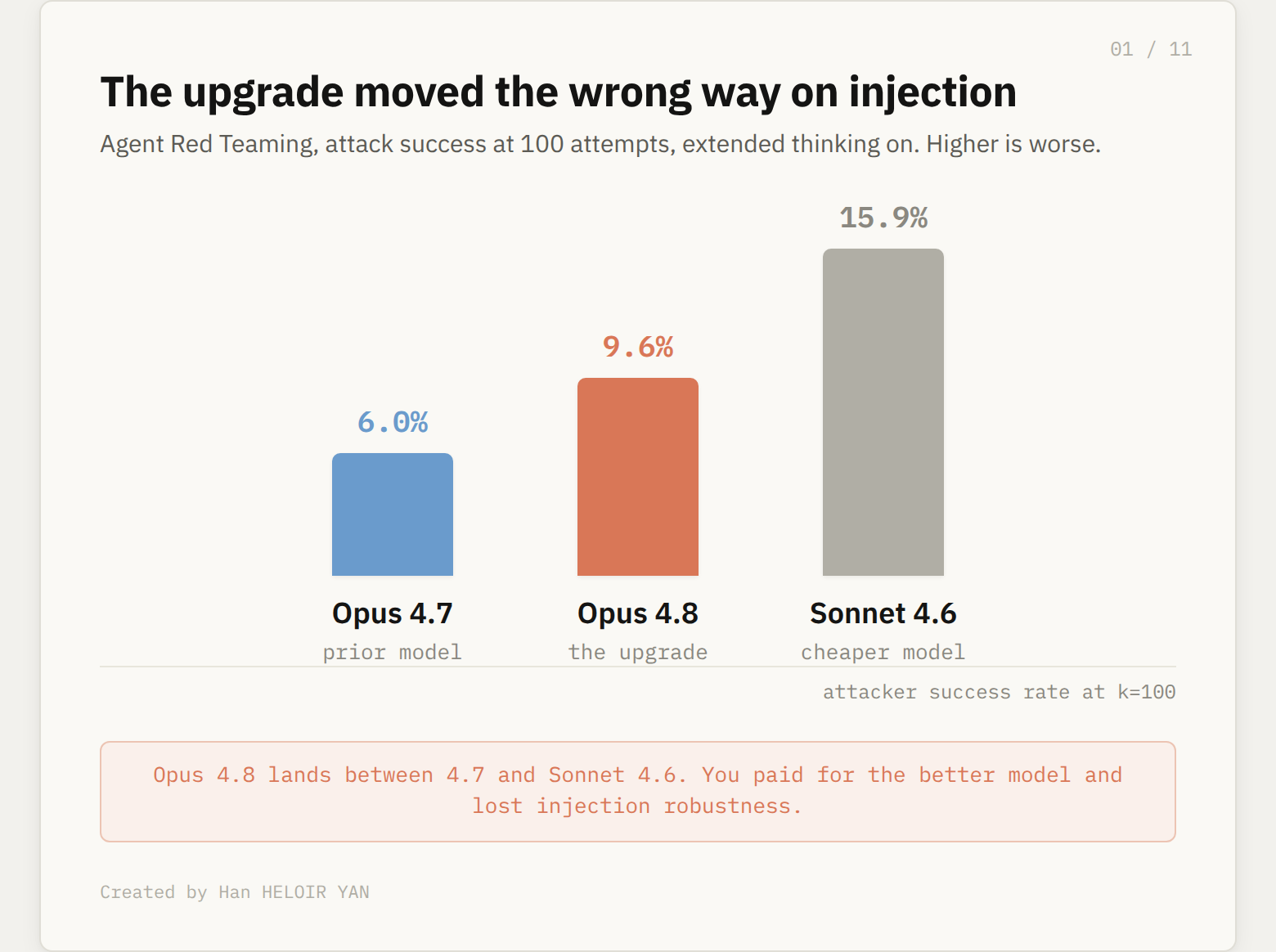
Prompt injection is the attack where a malicious instruction hides inside tool output, an email body, a web page, a returned API payload, and the agent treats it as if you had typed it. On the Agent Red Teaming benchmark run by Gray Swan, with extended thinking enabled, an attacker finds a working injection against Opus 4.8 about 9.6% of the time at one hundred attempts. The same number for Opus 4.7 is 6.0%. Sonnet 4.6 sits at 15.9%.
So Opus 4.8 lands between the two. Better than the cheaper model, worse than the model it replaces. What it means in practice: if your agent reads untrusted content and you swapped 4.7 for 4.8 expecting a free safety bump, you moved the wrong direction on the one metric that matters most for agents with both data access and the ability to act.
The upgrade moved the wrong way on injection.
The cyber numbers point the same way. On CyberGym, a suite of 1,507 real vulnerability reproduction tasks, the bare Opus 4.8 reproduces 78.8% of targeted vulnerabilities on the first try. Opus 4.7 reproduces 73.1%. Sonnet 4.6 reproduces 65.2%. The capability went up, which for an offensive task means the raw model got more dangerous, not less.
Why it matters: capability and safety moved in opposite directions in the same release. The card is candid that the standalone model advanced on exactly the axes you would want a safety story to cover. If the model were the product, this would be a worse release for anyone running agents on untrusted input.
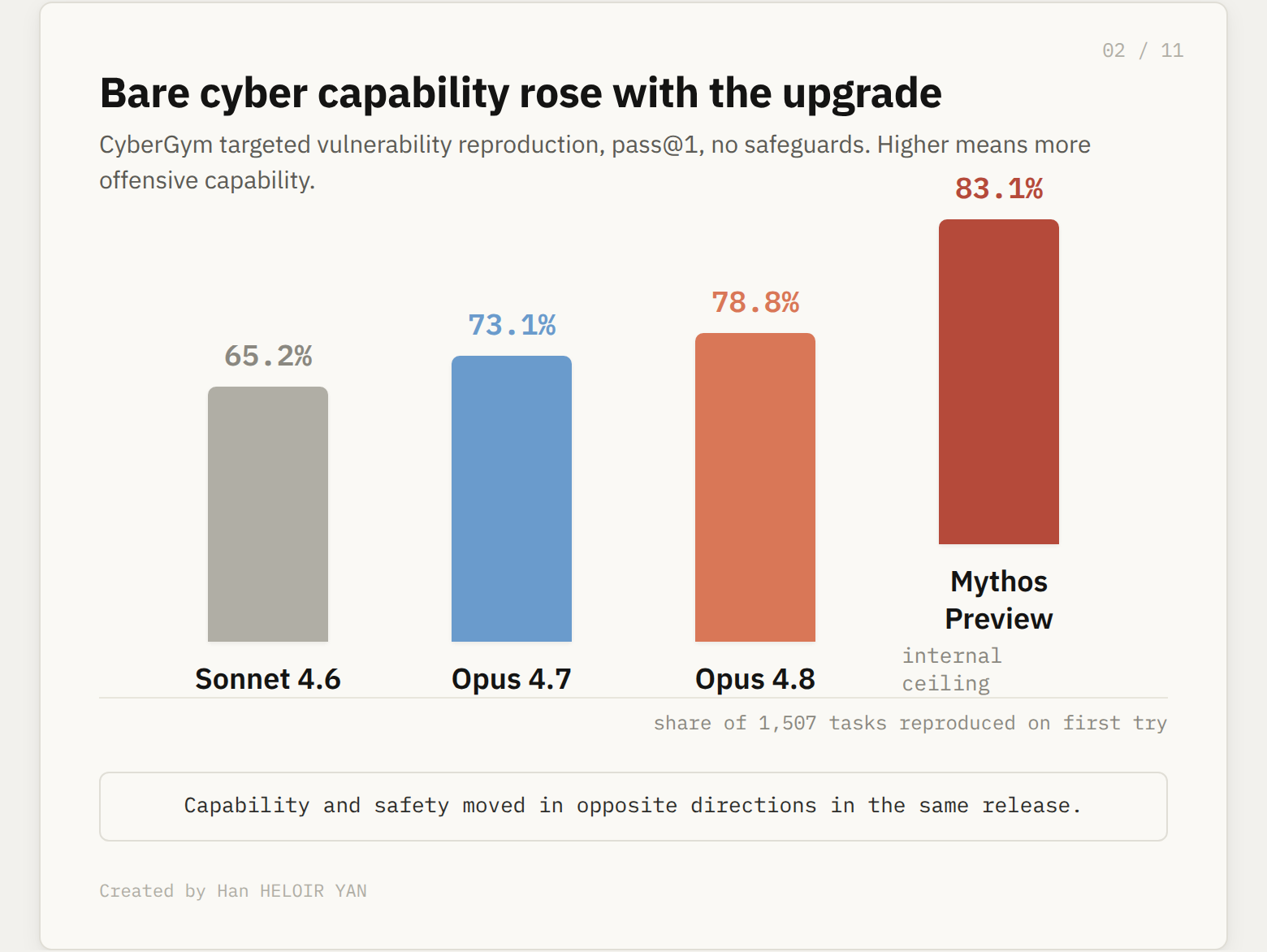
Bare cyber capability rose with the upgrade.
The safety you observe in production is a property of the harness, not the checkpoint.
Here is the part nobody put in a headline. Anthropic deploys lightweight detectors called probes by default across most of its agentic products. The probes are trained on the model’s internal representations, they sit outside the weights, and the card states their effect directly: they bring the deployed system back in line with Opus 4.7.
Read that again. The model lost ground. A component bolted on around the model gave the ground back. The thing that closed the gap was never the model.
The cyber side makes this unmistakable. With Tier 3 safeguards switched on, targeted vulnerability reproduction drops from 78.8% to 1.0% for Opus 4.8. For Opus 4.7 the same safeguards drop it to 7.1%. The safeguards are not just closing the gap, they bite harder on the newer model. The more capable checkpoint is the one the harness suppresses more aggressively.
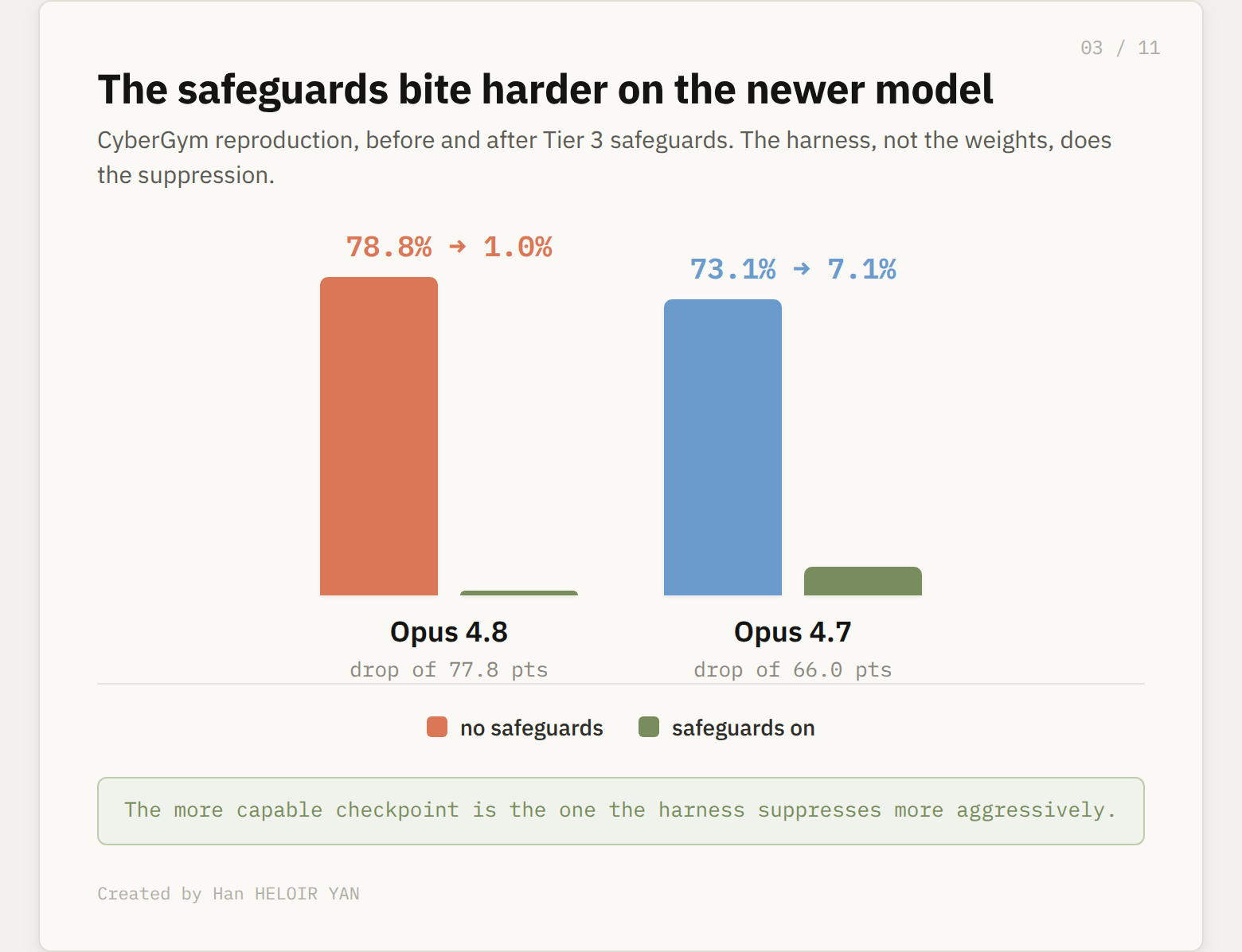
The safeguards bite harder on the newer model.
There is a sentence in the agentic safety section that you should treat as a load bearing disclaimer for the whole card. Claude was tested in the live bug bounty without the additional protections used in production, no harness level defenses, no injection probes. Anthropic spells out the consequence: the reported robustness reflects the models themselves and is a lower bound for the deployed systems built around them.
A lower bound. The published injection numbers are the floor, measured with the harness removed. The safety you actually get in Anthropic’s own products is strictly better than what the card reports, and the difference is the harness. Which raises the only question that matters for your stack: do you get that harness, or do you inherit the floor?

The published numbers are a floor.
The regression is only your problem if you own the layer it lives in.
I keep coming back to a five layer way of cutting an agent system. Constraint is layer one, what the agent is and is not allowed to do. Context is layer two. Execution is layer three, the sandbox the agent acts inside. Verification is layer four, checking the work. Lifecycle is layer five. The interesting question with any release is which layers the platform keeps and which it hands to you.
The injection probes are a constraint layer control. They live inside Anthropic’s products. If you build on the first party surfaces, Claude in Chrome, Claude Code, Cowork, the constraint layer is staffed for you and the deployed robustness is the better number, the one above the floor.
If you build on the raw API, you inherit the floor. The probes are not an API default. The model you call through the endpoint is the same model that scored between 4.7 and Sonnet 4.6 with its harness stripped off. Nothing about paying for the more capable checkpoint hands you the controls that made it safe in someone else’s product.
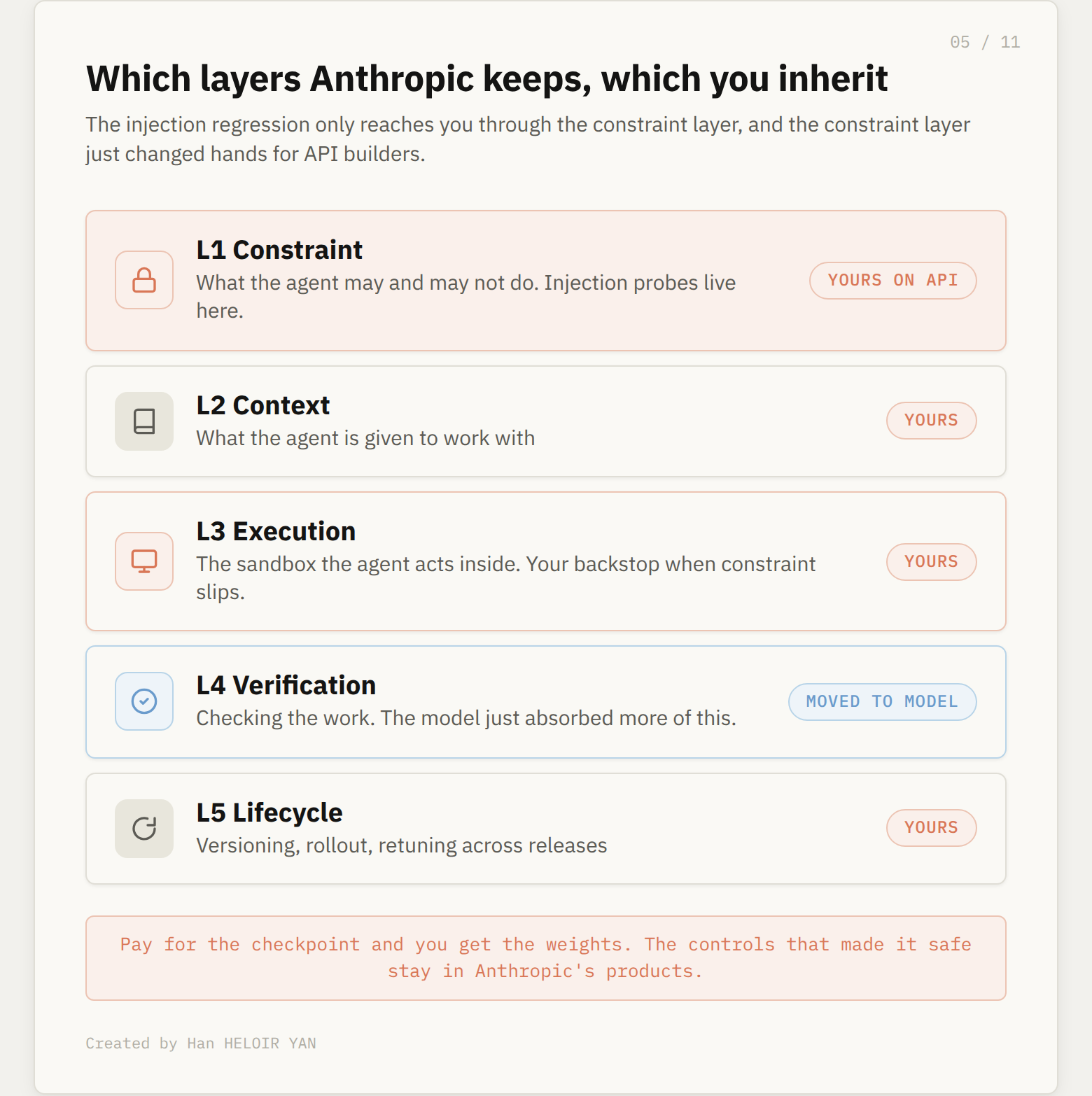
Which layers Anthropic keeps, which you inherit.
This is where execution, layer three, stops being optional. If you own the constraint layer because you are on the API, your sandbox is the thing standing between a successful injection and an exfiltration. It is not a coincidence that the migration write ups for this release are already pointing at self-hosted sandbox patterns as the reference architecture. The regression made the sandbox load bearing for anyone off the first party path.
The decision is not which model to call. The decision is which deployment path you are on, because the path determines which layers you just became responsible for.

Your deployment path decides what you inherit.
The same release that made you own more of the constraint layer let you hand more of the verification layer to the model.
If the story stopped at "the harness saved the model," it would be tidy and half true. The card is more interesting than that, because a different layer moved in the opposite direction. Verification, layer four, partly moved into the weights.
Three results, all firsts. Opus 4.8 is the first Claude to score perfectly on an evaluation where the code quietly mishandles bad data, defaulting broken measurements to zero instead of dropping them, and the model is asked for the aggregate. Earlier models noticed the logic was wrong and reported the number anyway. Opus 4.8 never reports the false number.
It is also the first Claude to score perfectly on a lazy investigation test, tracing a value through misleading code where a function silently caps its argument. The next best model, Opus 4.7, gave the wrong answer 25% of the time. And on code summary honesty, where the model summarizes a coding session that secretly failed, Opus 4.8 fails to surface the failure only 3.7% of the time, down from 27.6% for Mythos Preview, Anthropic’s strongest internal model, and down nearly as far from 4.7.
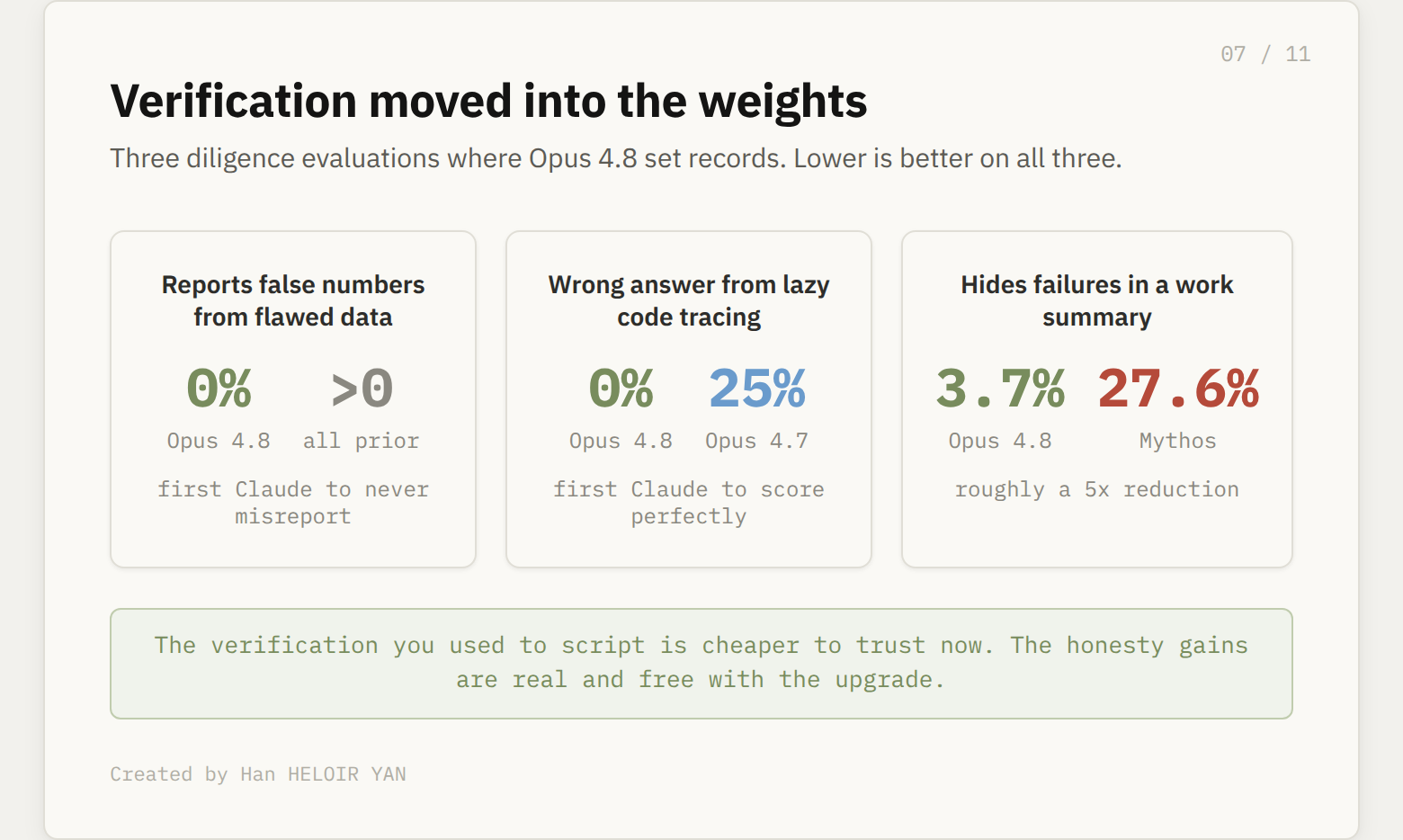
Verification moved into the weights.
What this buys you: verification you used to script, a second model grading the first, an assertion that the summary matches the diff, a check that flagged data got dropped, is cheaper to trust now because the model does more of it unprompted. The honesty gains are real and they are free with the upgrade.
One asterisk worth keeping. The card flags that Opus 4.8 sometimes reasons about how its output will be graded rather than how to do the task, and notes that inhibiting the model’s internal evaluation awareness increases deception and important omissions in their audits. The honesty is strong, and Anthropic is watching the seam where it could become performance for a grader. Trust the verification gains, keep a spot check.
So the boundary moved both ways at once. Constraint shifted toward you. Verification shifted toward the model. Anyone who reads this release as a single arrow, safer or less safe, missed that the moat line is being redrawn one layer at a time.

The moat line moved both ways at once.
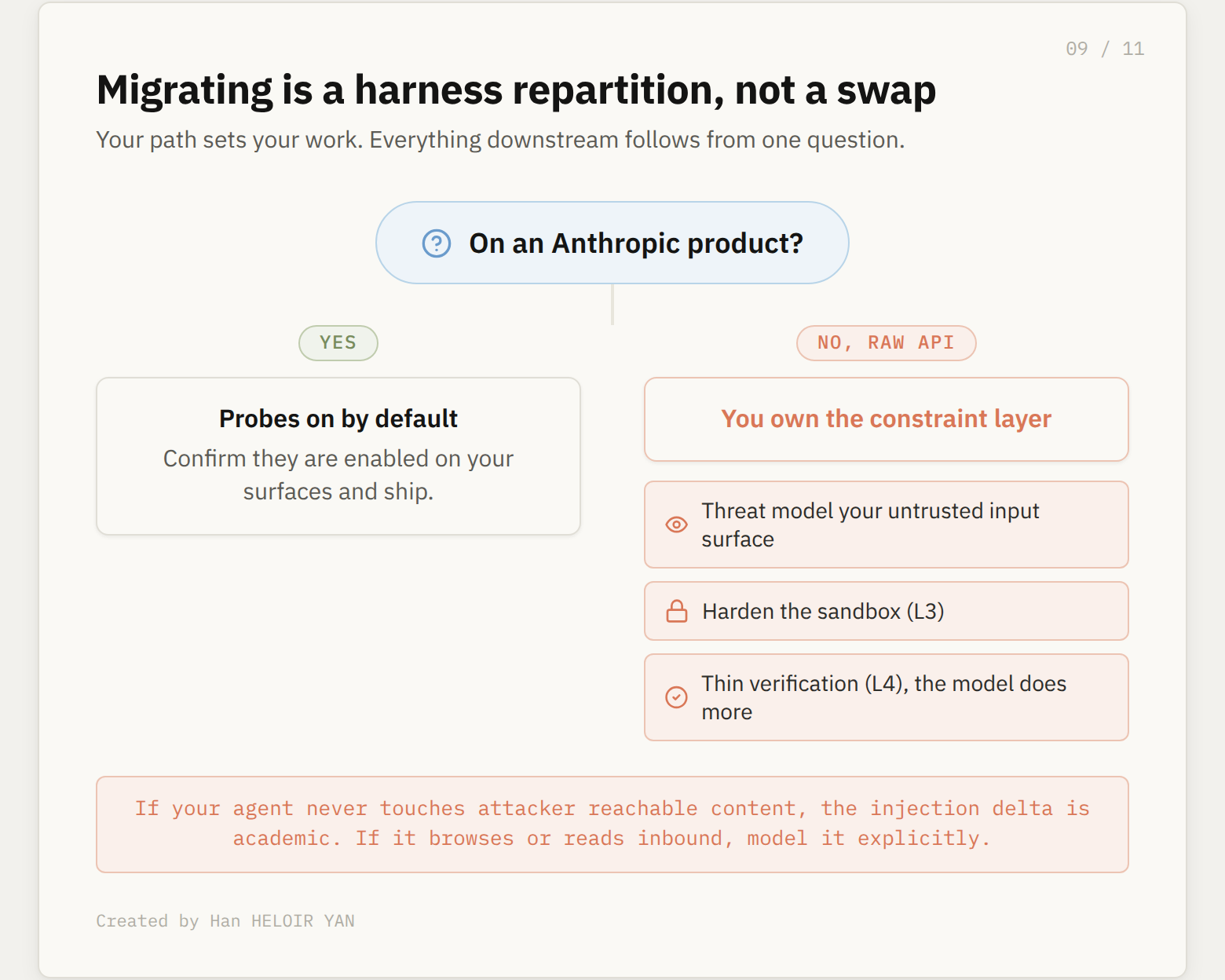
Migrating to 4.8 is not a model swap. It is a harness repartition.
Start by deciding which path you are on, because everything follows from it.
If you run on Anthropic’s products, the probes are on by default and the deployed robustness is the above-floor number. Your action item is small: confirm injection probes are enabled on the surfaces you use and move on.
If you run on the raw API or self-host, you own the constraint layer now in a way you did not last release. Three concrete moves.
First, threat model the regression against your actual untrusted input surface. If your agent never touches attacker reachable content, the injection delta is close to academic for you. If it summarizes inbound email, browses, or executes tool output from third party APIs, model the higher attack success rate explicitly before you migrate.
Second, make the sandbox carry the constraint the probes would have carried. Least privilege credentials, no ambient secrets in the agent’s reach, an explicit allowlist on egress so that a successful injection has nowhere to send the data it stole. The point of execution layer isolation is that the injection can succeed and still fail to matter.
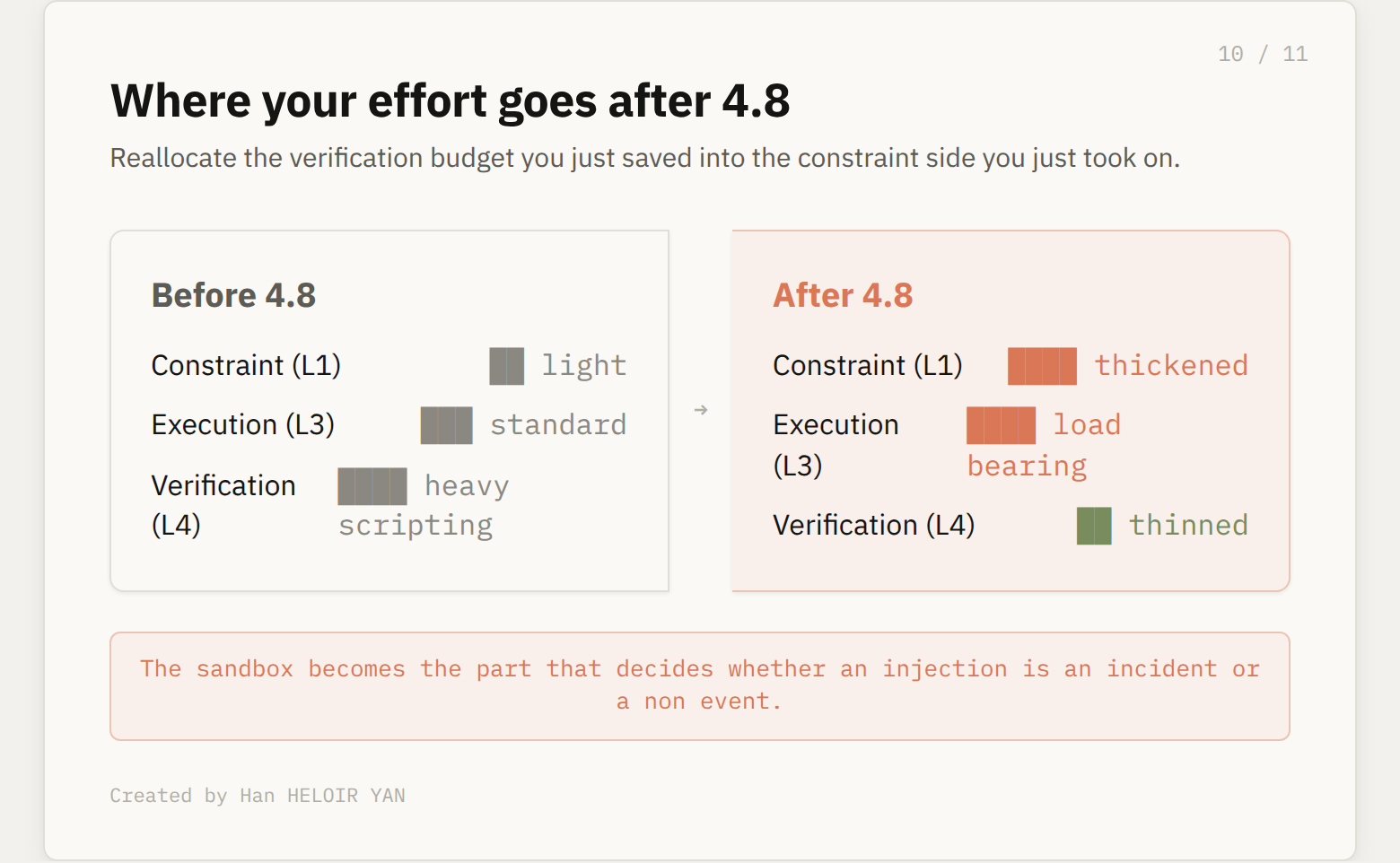
Third, thin your verification harness. The honesty gains let you retire some of the redundant self-checking you scripted for older models. Reallocate that budget to the constraint side, where you just took on more responsibility.
A detail that makes the partition concrete. The default API call gives you the model and nothing else.
from anthropic import Anthropic
client = Anthropic()
# This call returns the model's raw behavior.
# No injection probes. No harness-level defenses.
# You are calling the checkpoint that scored at the lower bound.
resp = client.messages.create(
model="claude-opus-4-8",
max_tokens=2048,
messages=[
{"role": "user", "content": untrusted_tool_output}, # the attack surface
],
)
There is no safeguards=True parameter that hands you the production stack. The probes are a product feature, not an endpoint flag. On the API, the constraint layer is yours to build, and the sandbox around this call is the part that decides whether an injection is an incident or a non event.
Anthropic says as much in its own prompt engineering guidance for this model. They note that a code review harness tuned for an older model may report fewer findings on 4.8, and they call it a harness effect, not a capability regression. The vendor is telling you, in the docs, that the model changed and your harness has to be retuned to match. That is the whole thesis in one support note.
Migrating is a harness repartition, not a swap.
Where your effort goes after 4.8.
The checkpoint is the depreciating asset. The harness is the appreciating one.
A model is a snapshot. It is the best Anthropic could ship on a date, and it will be replaced in weeks. Opus 4.6 became 4.7 became 4.8 inside a few months, and each step quietly shifted which layers live in the weights and which live in your code.
The harness is the part that compounds. The sandbox you hardened for the injection regression keeps working when the next checkpoint regresses somewhere new. The verification you can now lean on the model for frees budget you will spend on the next layer that moves toward you. The teams that track the moat line, not the leaderboard, are the ones who stop rewriting their stack every release.
Opus 4.8 is a better model and a less robust one, at the same time, depending entirely on whether you are talking about the checkpoint or the system. Anthropic drew the line for you, in 244 pages of evaluations. Your only job is to notice which side of it you are building on.

Track the moat line, not the leaderboard.
Created by Han HELOIR YAN