
You changed one string. claude-opus-4-7 became claude-opus-4-8, the session started with zero config changes, and the benchmarks came back better across the board. You shipped. Nothing in your pipeline broke, so nothing felt like it had changed.
Something did. While you were reading the benchmark table, three of the five layers of your harness quietly stopped being your job. Anthropic did not frame the release that way. They called it a model upgrade, and almost every writeup today repeated it: better coding scores, cheaper fast mode, a more honest model.
That framing is the misdirection. Opus 4.8 is not mainly a smarter model. It is Anthropic reaching into your harness and absorbing the parts you used to build yourself. Here is what they did not say out loud, one layer at a time.
Before we start!🦸🏻♀️ If this helps you ship better AI systems:
👏 Clap 50 times (yes, you can!). Medium's algorithm favors this, which increases visibility to others who then discover the article.
🔔 Follow me on Medium, LinkedIn and subscribe to get my latest article.
Here is the table that led every writeup today. Read the middle columns and Opus 4.8 is a tidy model upgrade. Read the last column and it is something else: a map of which harness layers Anthropic just reached into.
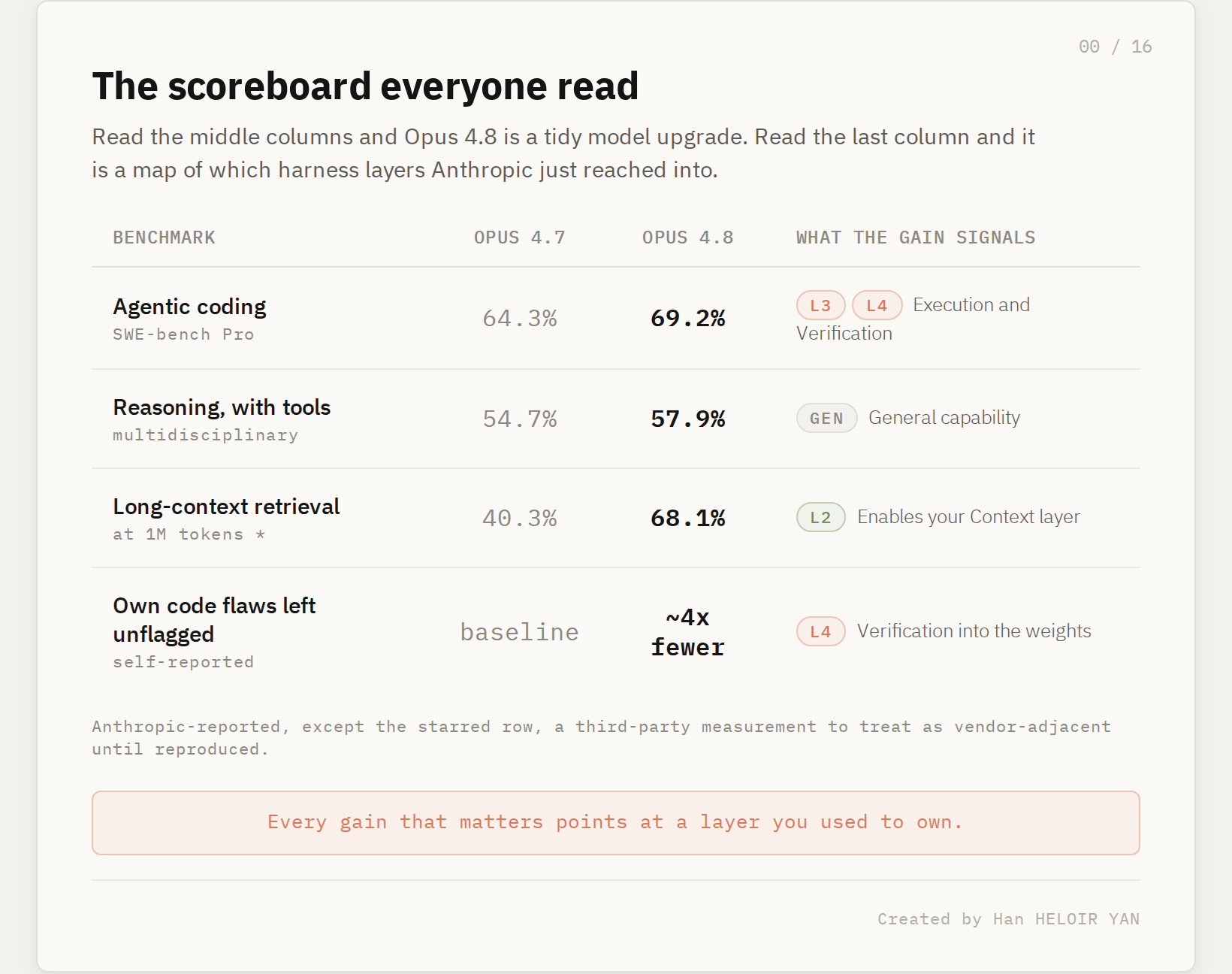
Every gain that matters points at a layer you used to own. The coding jump is your execution and checking work. The honesty gain is your critic. The wider context window is the room your retrieval fills. That last column is the whole article. The rest of this piece walks it, layer by layer.
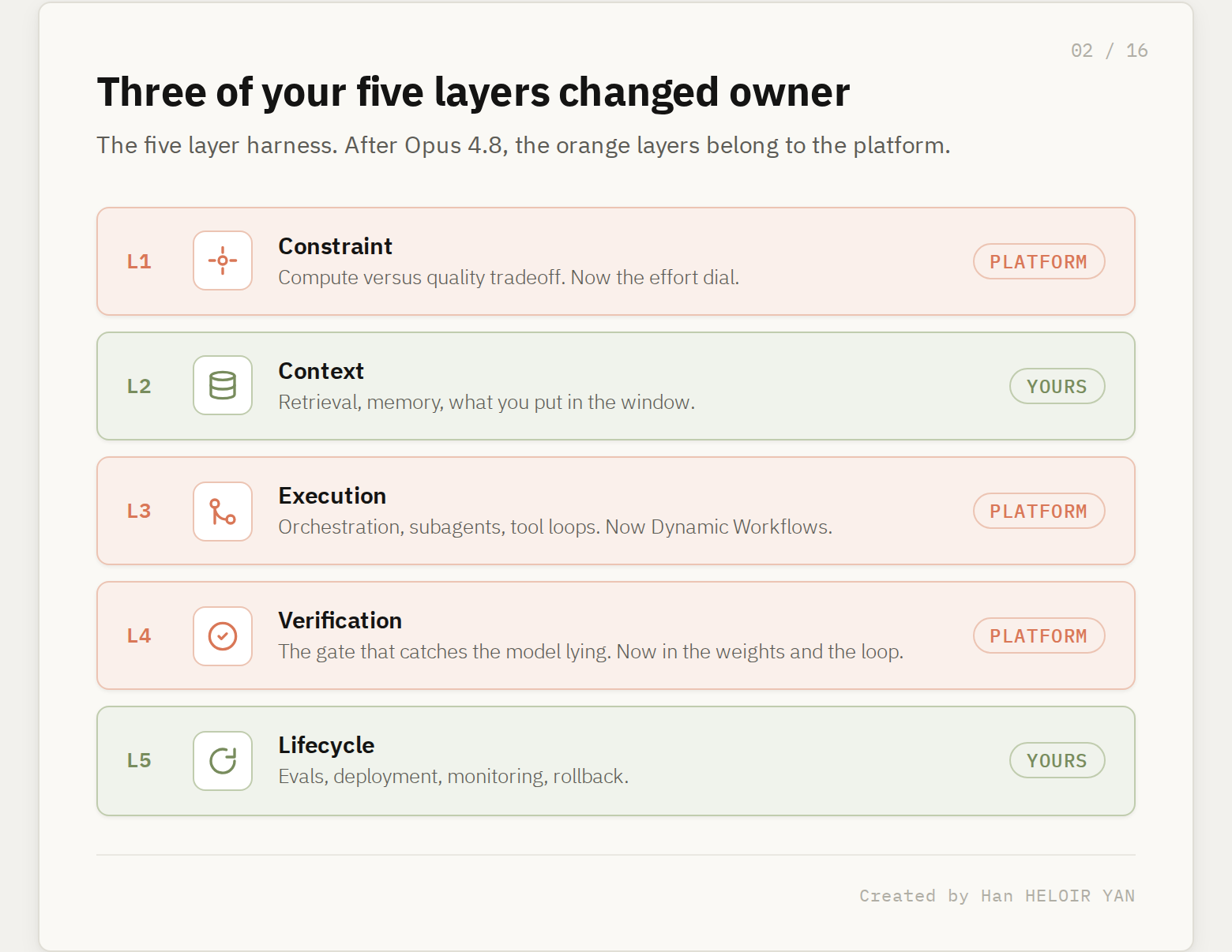
If you have read my earlier pieces you already know the frame. A frontier model is not a product. The product is the harness you wrap around it: the scaffolding that turns a raw next-token predictor into something you can trust in production. I break that harness into five layers.
Constraint (L1) is how you bound the model: routing, token budgets, the compute-versus-quality tradeoff you tune per task. Context (L2) is what you feed it: retrieval, memory, the engineering of what goes into the window. Execution (L3) is how work actually runs: orchestration, subagents, tool loops, retries. Verification (L4) is how you check the output before you trust it: tests, judges, the gate that catches the model lying about its own progress. Lifecycle (L5) is everything around the run: evals, deployment, monitoring, rollback.
For two years the model vendors sold you the engine and left all five layers to you. That gap was your moat. Opus 4.8 is the release where Anthropic stopped leaving three of those layers alone. It reached into Constraint, Execution, and Verification in a single drop, and it reached into Verification twice. The release notes call this honesty, dynamic workflows, and effort control. Read structurally, it is a land grab.
Start with the headline number, because it is the one every competitor repeated without noticing what it means. Anthropic reports that Opus 4.8 is roughly four times less likely than Opus 4.7 to let a flaw in code it wrote pass without flagging it. The company frames this as honesty: the model tells you when it is unsure and catches its own bugs instead of declaring victory early.
What it means: a behavior you used to buy with an external verification layer is now partly resident in the weights. The classic L4 harness is a second pass. You generate, then you run a linter, a test suite, a critic model, a human reviewer, anything that catches the confident-but-wrong output before it ships. The whole reason that layer exists is that models jump to conclusions. A model that is four times less likely to wave its own broken code through has, in effect, internalized a slice of your critic.
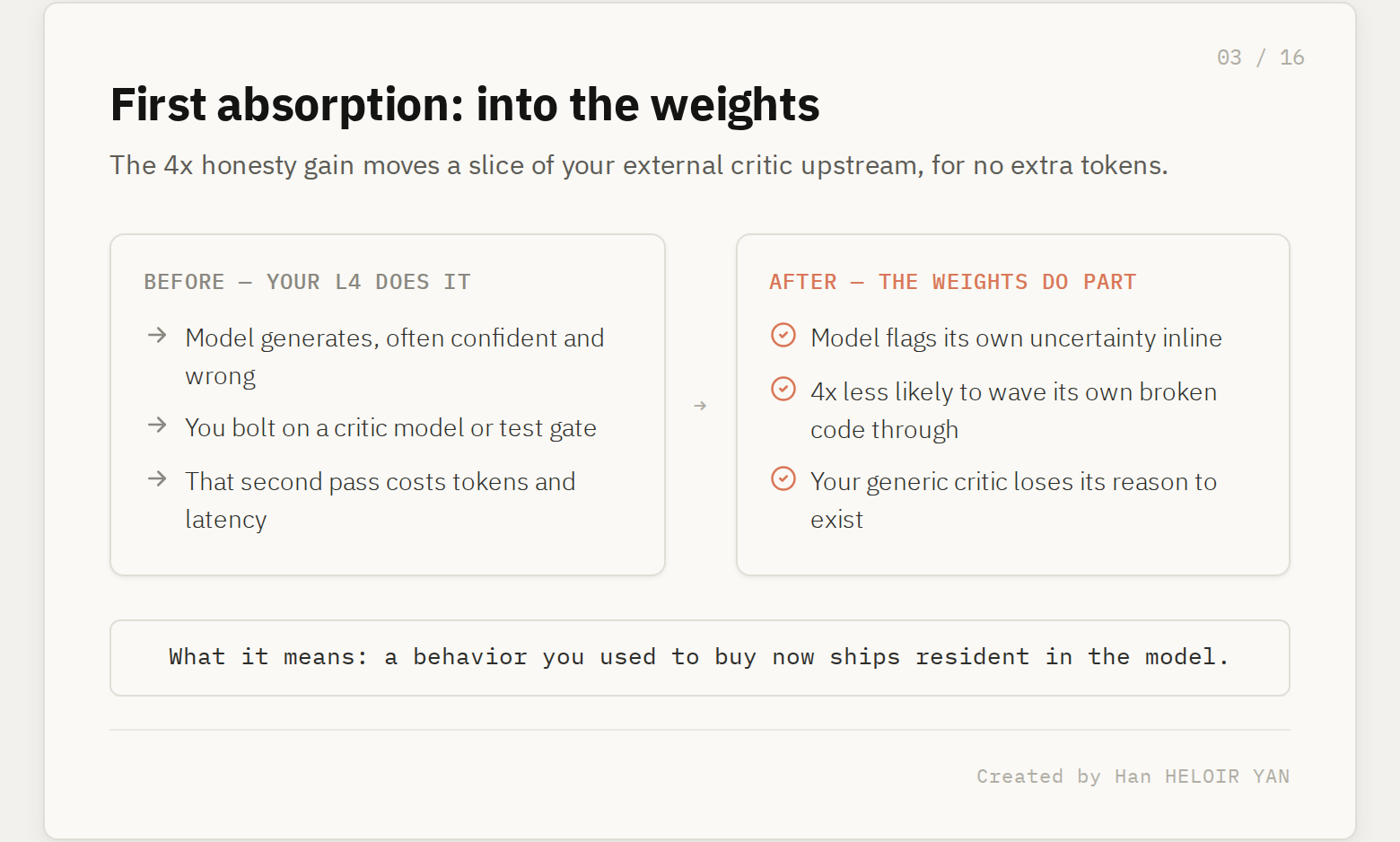
Why it matters: the marginal value of your bolt-on verification drops by exactly the amount the model now does for free. If you built a critic-model gate to catch silent failures during long agentic runs, part of its job just got done upstream, for no extra tokens. That is not nothing. A Bridgewater tester told Anthropic the biggest difference was the model proactively flagging issues with the inputs and outputs of an analysis, the exact thing other models leave for the user to catch. That is L4 work, happening inside the model.
Then Anthropic absorbed the same layer a second time, in a different place. Dynamic Workflows, the new Claude Code feature, does not just spawn parallel subagents. According to Anthropic's own description, Claude plans the work, runs hundreds of parallel subagents, and then verifies its outputs before reporting back. Verification is now a built-in stage of the execution loop, not a gate you bolt on after it.
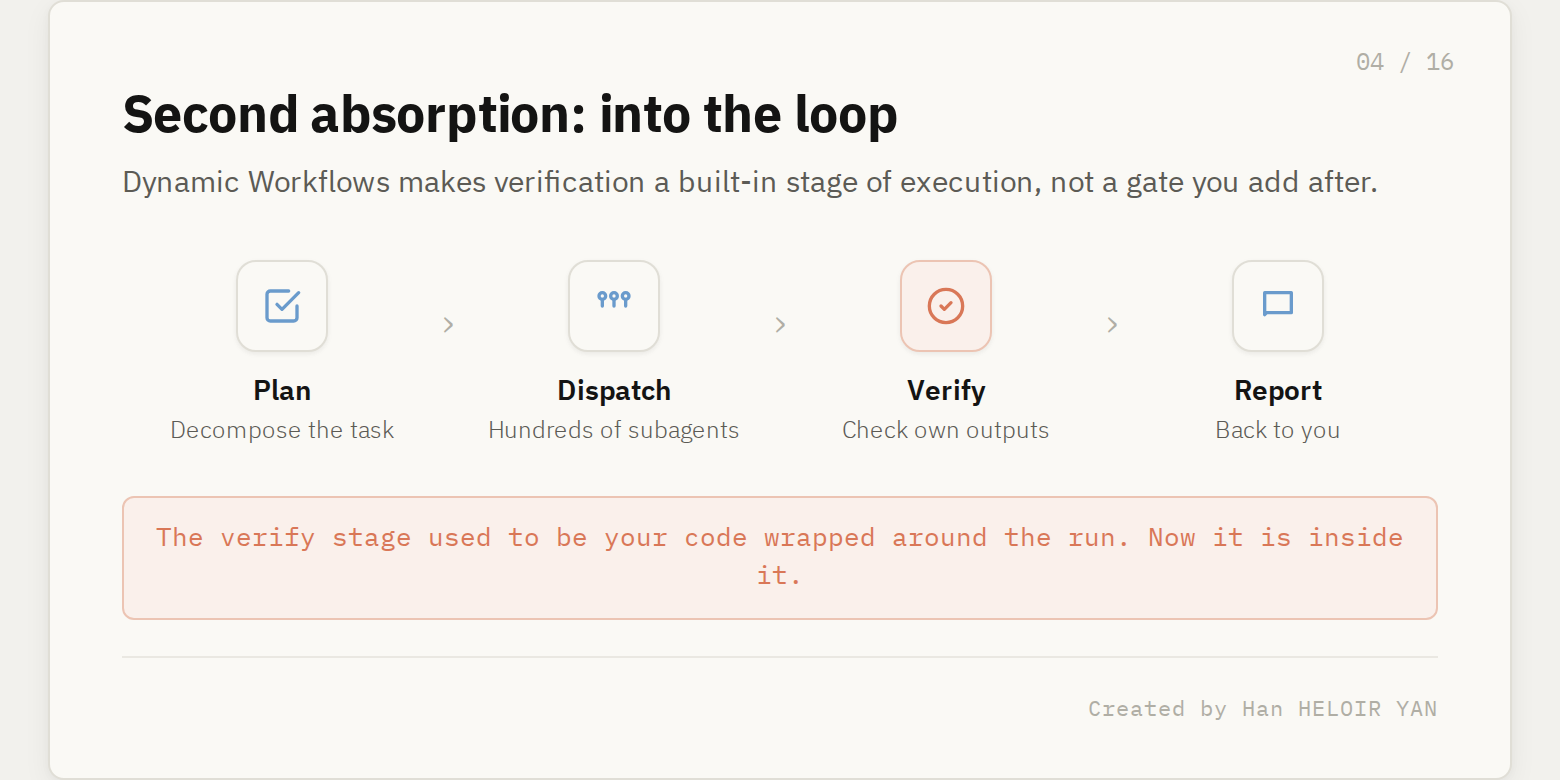
Sit with that. Verification got absorbed into the weights and into the orchestration loop in the same release. If your harness's defensibility leaned on owning the checking step, Opus 4.8 is the release that came for it from two directions at once.

Execution is the second layer Anthropic took. The version everyone reported is the impressive one: Claude Code with Opus 4.8 can carry a codebase-scale migration across hundreds of thousands of lines from kickoff to merge, with the existing test suite as the bar. One early account describes a port of roughly 750,000 lines of Rust at 99.8 percent test-suite passing in eleven days. Treat the specific figure as a vendor-adjacent claim until you reproduce it, but the shape is real.
What it means: the orchestration you used to assemble by hand is now a platform primitive. Before this, running a hard problem across many agents meant you owned the hard parts. You wrote the planner that decomposed the task. You managed the fan-out to parallel workers. You handled partial failure, retries, and state across a multi-day job. You either built that or you adopted a multi-agent framework and inherited its opinions. That assembly was L3, and it was yours.
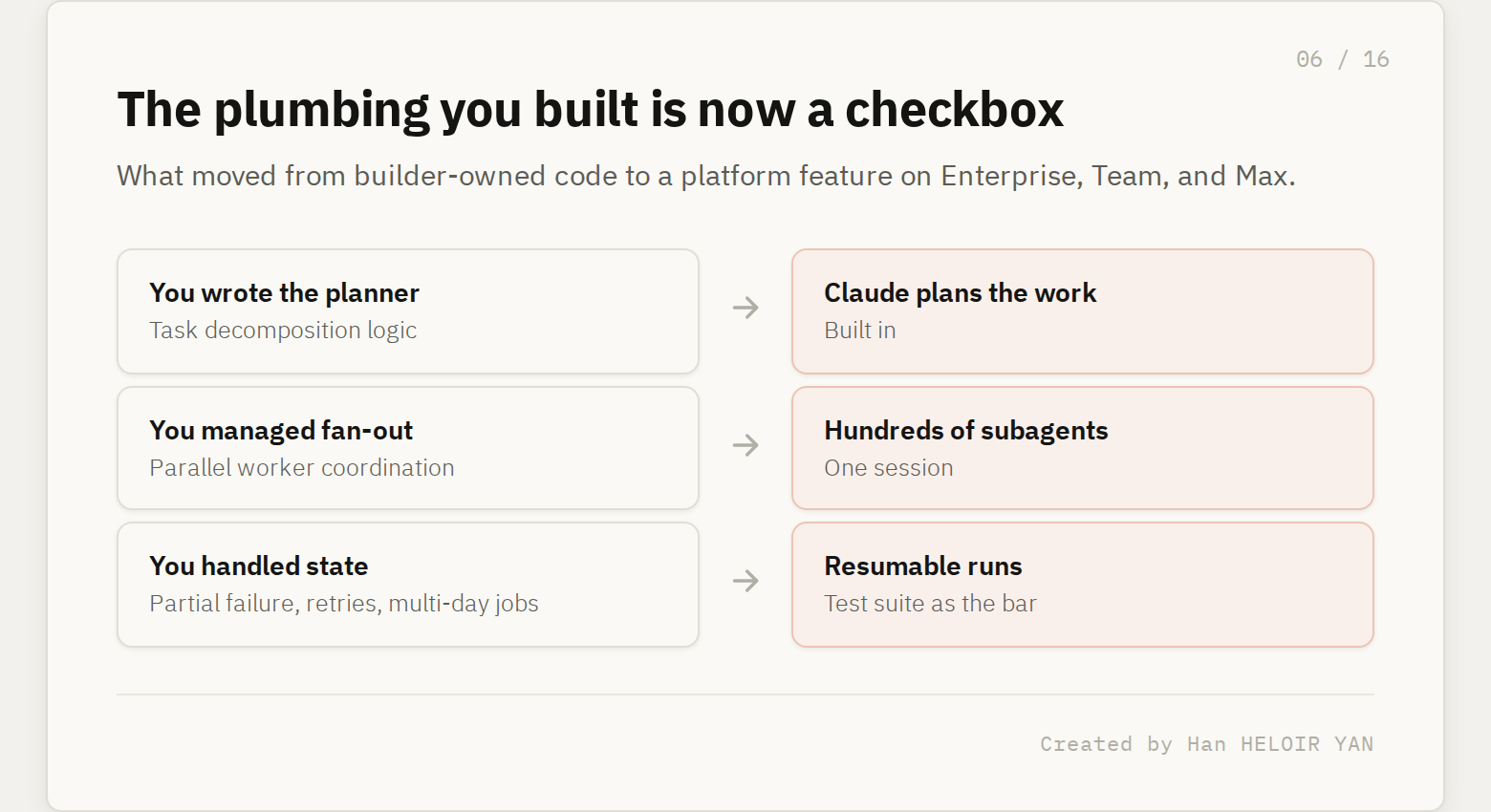
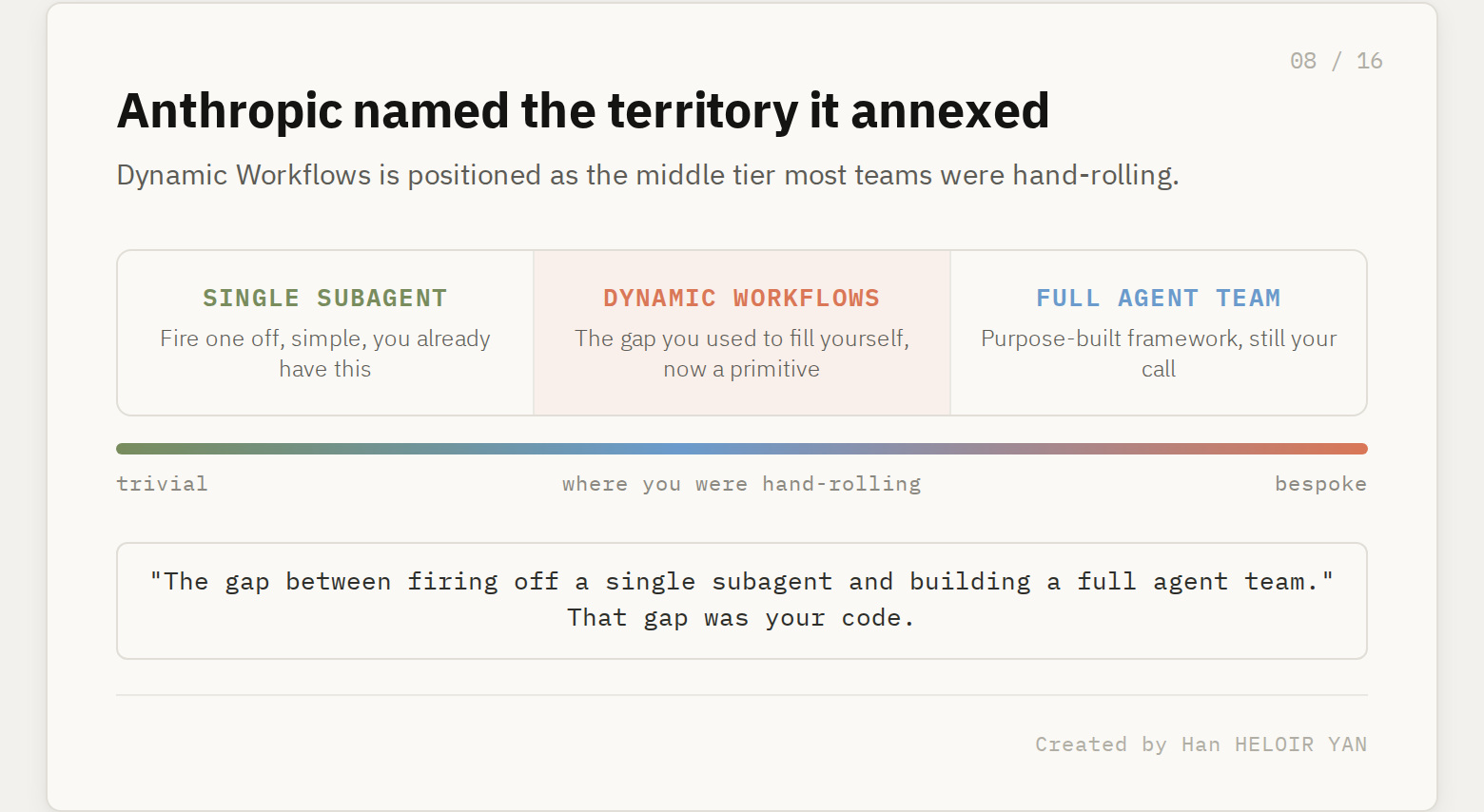
Dynamic Workflows collapses it into a feature. Plan, dispatch hundreds of subagents that attack the problem from independent angles, verify, report. The positioning is the tell. An engineer at CyberAgent described it as filling the gap between firing off a single subagent and building out a full agent team. That is Anthropic naming the exact territory it is annexing: the middle tier of orchestration, the part most teams were hand-rolling because nothing off the shelf fit.

Why it matters: if your differentiation was orchestration plumbing, that moat is now a checkbox on Enterprise, Team, and Max plans. The teams who win here are the ones who treated orchestration as undifferentiated heavy lifting all along and spent their effort elsewhere. A Klarna engineer noted the feature is most valuable for discovery and review across large codebases, surfacing dead code that static analysis missed. Notice what that is: high value, but not proprietary. It is exactly the kind of work you are happy to let the platform own.
The quietest absorption is the one that looks like a convenience feature. Opus 4.8 ships effort control. On claude.ai and Cowork you pick how hard Claude works on a response. In Claude Code the levels run low, high, extra, and max, and the default dropped to high, where the model spends roughly the same tokens as Opus 4.7's old default but scores higher.
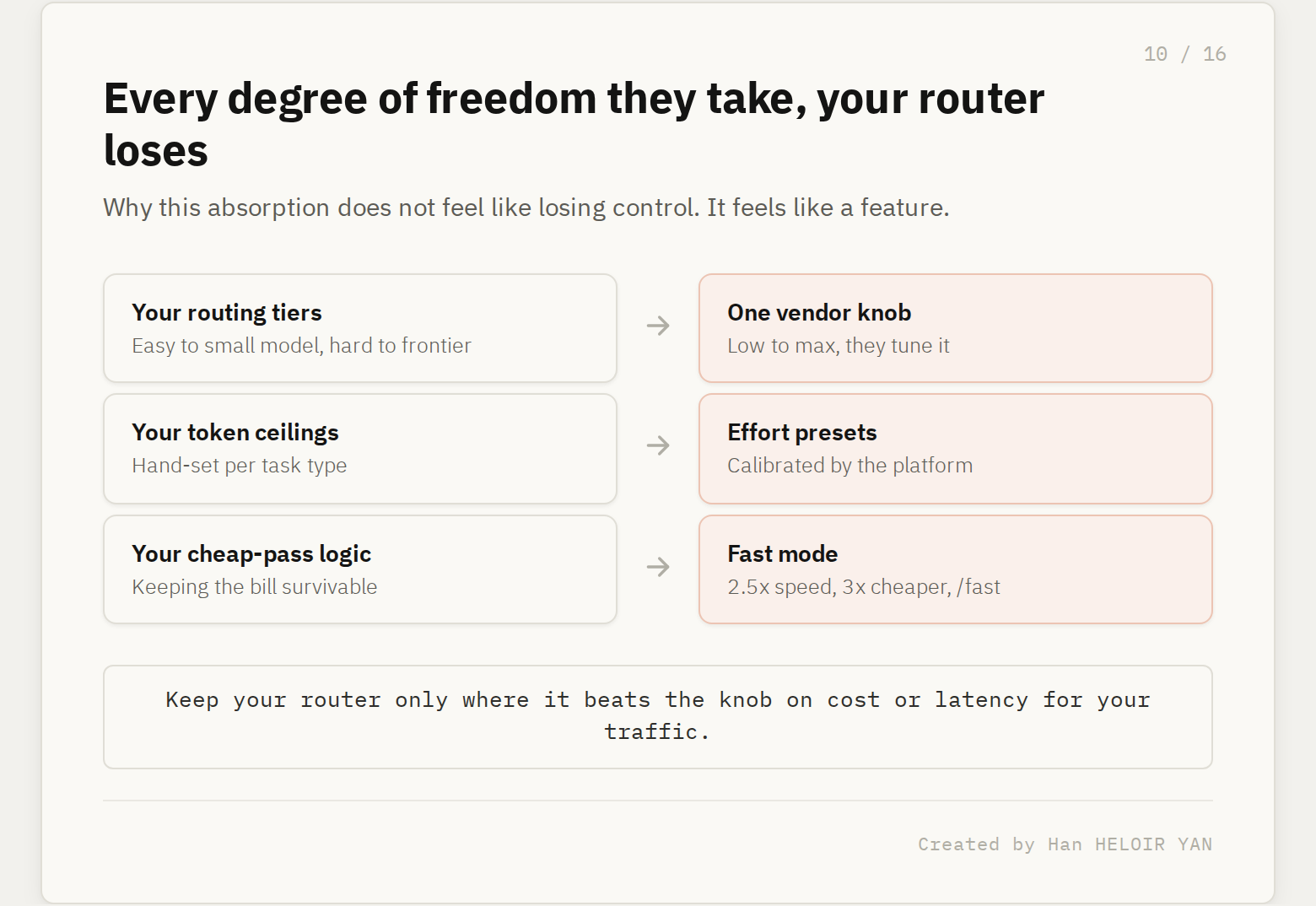
What it means: the compute-versus-quality tradeoff is L1, the Constraint layer, and it used to be your code. You were the one deciding when a task deserved the expensive model and when a cheap pass would do. You built routing tiers. You set token ceilings. You wrote the logic that sent easy requests to a small model and hard ones to the frontier, because that logic was how you kept the bill survivable. Effort control turns that decision into a knob the vendor exposes and the vendor tunes.
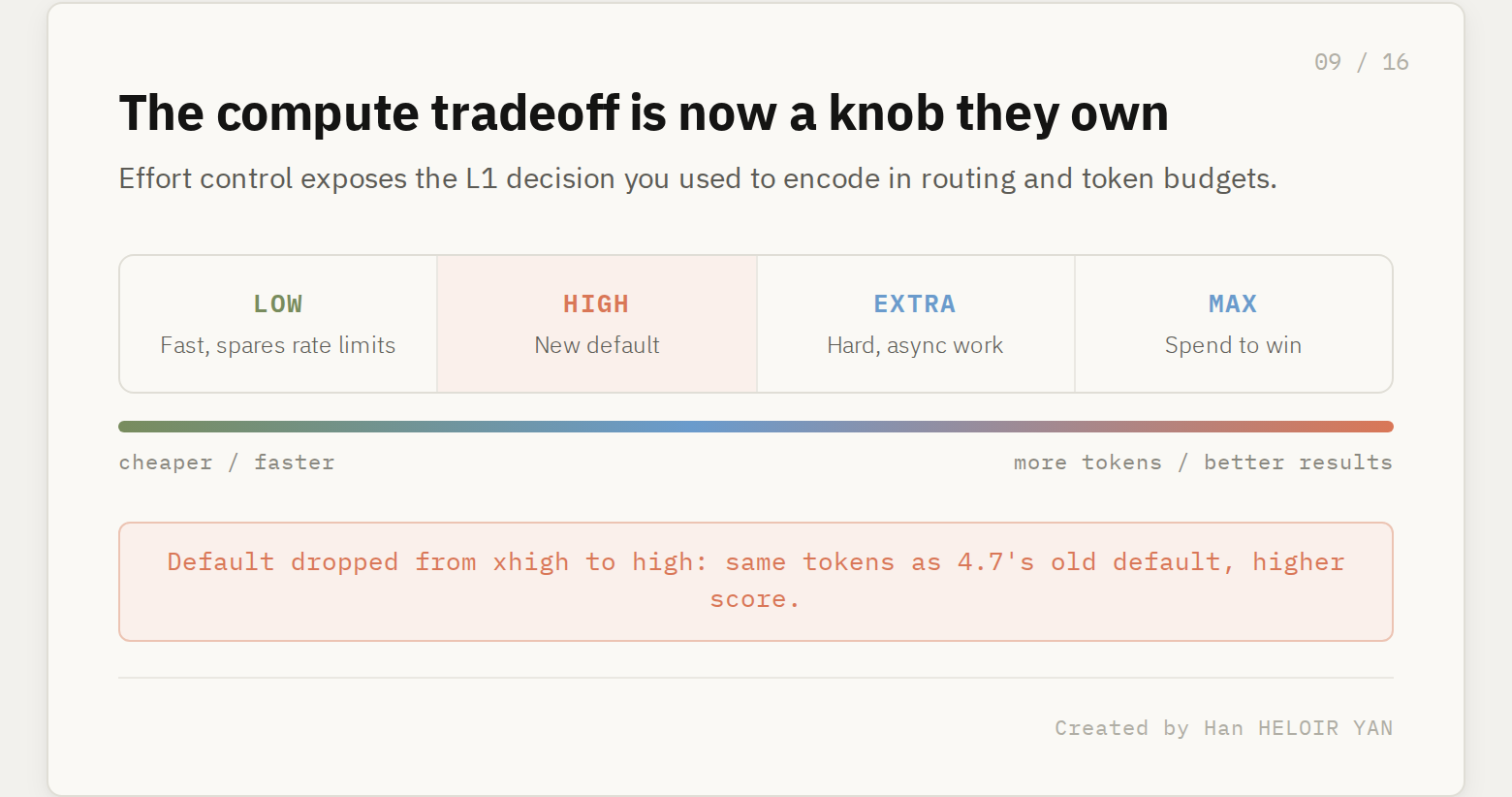
Why it matters: every degree of freedom the platform absorbs is surface area your routing layer loses. This is not automatically bad. A well-calibrated effort dial can beat a crude home-grown router, and the cheaper, faster mode reinforces the point. Fast mode now runs at about 2.5 times the speed of standard Opus 4.8 and costs three times less than the previous generation's fast tier, toggled with /fast. The vendor is making it genuinely attractive to hand over the tradeoff. That is how absorption works. It does not feel like losing control. It feels like a feature you would be silly not to use.
Here is the part the doom reading misses. Anthropic absorbed Constraint, Execution, and Verification. It did not touch Context (L2) or Lifecycle (L5), and that is not an accident. Those are the two layers the vendor structurally cannot own, because they depend on things Anthropic cannot see.
Context is what you put in the window, and the high-value version of it lives in your data, your retrieval strategy, your memory design, and your domain. Opus 4.8 supports a one-million-token context window by default, and one report puts long-context retrieval at 68.1 percent at a million tokens against 40.3 percent for Opus 4.7. That is a bigger, sharper room to furnish. It does not decide what furniture goes in. Deciding that is still your engineering, and it is now more valuable, not less, because the room got bigger.

Lifecycle is everything around the run that encodes your judgment about whether the system is actually working. Your eval suite is your definition of correct for your problem, which is not a thing the model ships with. Your deployment gates, your monitoring, your rollback plan, your acceptance criteria: all of that is the institutional knowledge of what good looks like in your context. A more honest model that flags its own uncertainty makes your monitoring better. It does not replace the decision about what to monitor.
So the honest map is this. Three layers became commodity overnight. Two layers became the whole game. The defensible work did not disappear. It moved up the stack, toward the parts that are made of your data and your judgment rather than your plumbing.
Resist the urge to do nothing just because the swap was painless. The model change is trivial: repoint to claude-opus-4-8, or claude-opus-4-8[1m] for the large window, and your sessions keep running. The strategic change is not trivial, and it is a deletion exercise before it is a building exercise.

Walk your harness layer by layer and ask one question at each: is this still mine to own. For Verification, audit your critic and gate logic and find the parts that exist only to catch the model declaring false victory, because the model now does a meaningful share of that itself. Keep the checks that encode your domain rules; retire the generic ones. For Execution, if you are maintaining bespoke planner-and-fan-out plumbing, pilot Dynamic Workflows against it on a real migration and measure whether your code is still earning its keep. For Constraint, run your router against the effort dial and keep your routing only where it beats the knob on cost or latency for your traffic.
Then spend everything you freed up on the two layers that are now your moat. Make your context engineering sharper: better retrieval, better memory, better use of the million-token room. Make your lifecycle deeper: harder evals that encode what correct means for your problem, tighter monitoring, faster rollback. That is where the differentiation lives now, and it is where the next release cannot reach, because Anthropic does not have your data and does not know your definition of done.

Step back from the single release and the pattern is the real story. Each Opus point release has reached a little further into the harness. Effort control, Dynamic Workflows, and the honesty gain are this release's three steps up the stack, and they will not be the last. Anthropic has already signaled Mythos-class models in the coming weeks. Assume the next drop absorbs another layer, and build as if the plumbing you own today is on loan.
The durable position is the one made of what the vendor cannot see. Your data. Your domain. Your eval criteria. Your judgment about what good looks like. Opus 4.8 did not weaken that position. It cleared away the layers that were never your real advantage and pushed everyone toward the layers that are. The moat is still the harness. The harness is just smaller, sharper, and harder to copy than it was on Wednesday.
Credits and further reading