Han HELOIR YAN, Ph.D. ☕️
Anthropic just shipped Claude Opus 4.7. The announcement blog post mentions, four times, that the model is less capable than another model they refuse to release. Read that again. A company ran a launch event for a product and kept pointing at a better product they are keeping in a vault.
That is not a product announcement. That is a strategic signal.
Opus 4.7 is excellent at what it does. The benchmarks are real, the partner quotes are glowing, the capability gains are measurable. But the story around the model matters more than the benchmarks inside it. Two shifts land with this release, and they have the same underlying shape: decisions that used to live in your harness code are moving into the model's weights, and decisions that used to be yours to make are moving into the model company's training pipeline.
Before we start! 🦸🏻♀️ If this helps you ship better AI systems: 👏 Clap 50 times (yes, you can!) : Medium's algorithm favors this, increasing visibility to others who then discover the article. 🔔 Follow me on Medium, LinkedIn and subscribe to get my latest article.
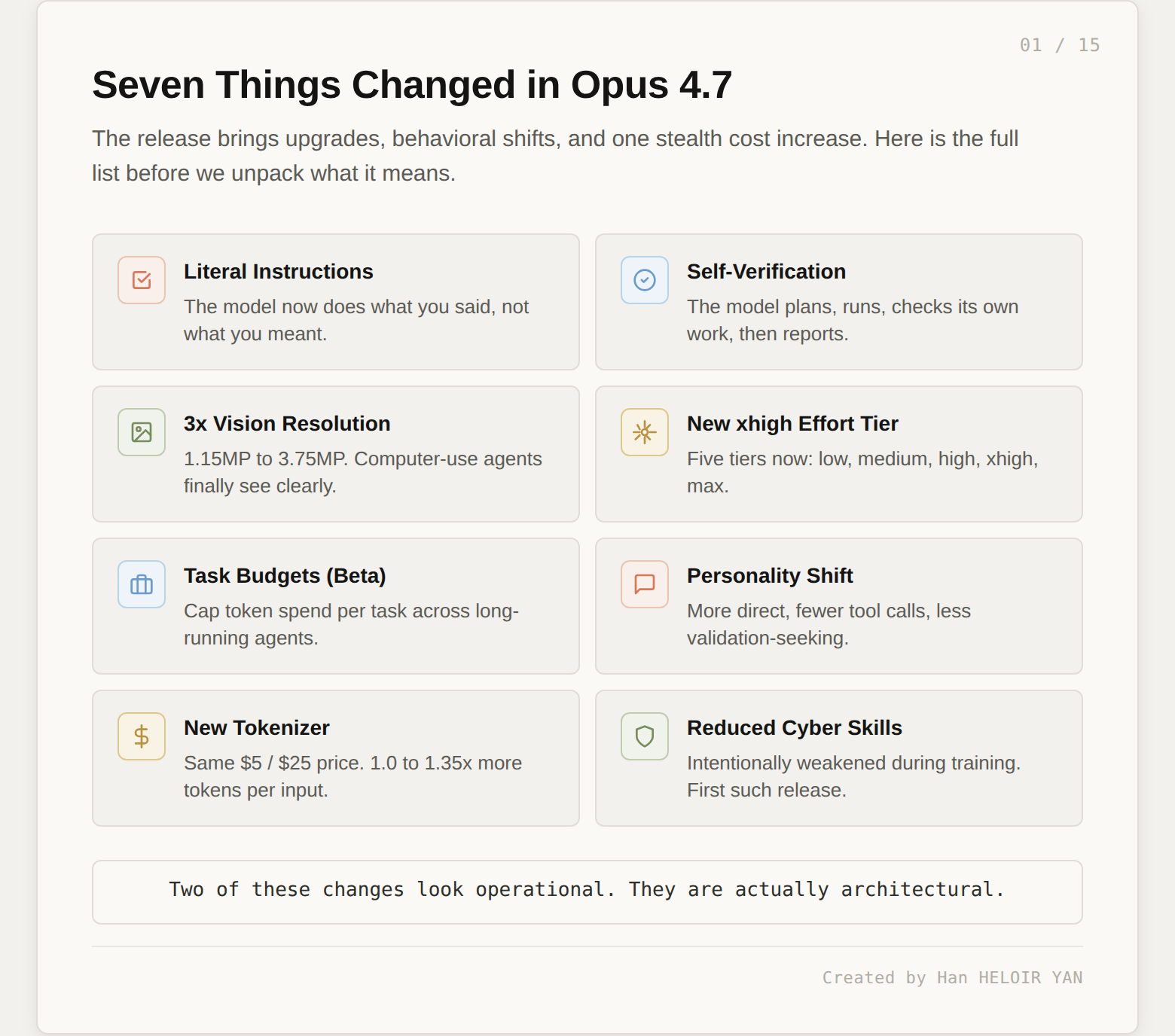
xhigh effort tier, task budgets in beta, a behavioral personality shift, and a new tokenizer that raises token counts by 1.0 to 1.35x at the same sticker price.
Opus 4.7 shipped on April 16, 2026, two months after Opus 4.6. Anthropic kept their roughly two-month release cadence. Pricing held steady at $5 per million input tokens and $25 per million output tokens. The model is a direct upgrade, not a new tier, and it replaces Opus 4.6 as the default Opus. That much is routine.
The seven changes below are not routine. Two of them look operational. They are actually architectural.
Opus 4.7 interprets prompts literally. Where Opus 4.6 would read between the lines and infer what you probably meant, Opus 4.7 does what you said. If you wrote "format the output nicely," and you had three items to format, Opus 4.6 would apply the formatting to all three. Opus 4.7 might format the first one, leave the second underspecified, and treat the third as a different case entirely. The model will not silently generalize an instruction from one item to another, and it will not infer requests you did not make.

This is simultaneously the biggest upgrade and the biggest migration headache. Upgrade: your carefully tuned prompts produce more predictable output. Headache: the prompts that relied on the model's old habit of filling in implied intent will now produce results that feel broken until you realize the model is just doing exactly what you asked.
The fix, when something goes wrong, is to state scope explicitly. "Apply this formatting to every section, not just the first one." Treat the model less like a colleague who reads between the lines and more like a contract that enforces every clause.
The most architecturally interesting change. Opus 4.7 plans, executes, checks its own output, and then reports back. The verification step is new. Vercel's engineering team noted the model "does proofs on systems code before starting work, which is new behavior we haven't seen from earlier Claude models." Hex observed that Opus 4.7 "correctly reports when data is missing instead of providing plausible-but-incorrect fallbacks." Cognition, the team behind Devin, reports the model "works coherently for hours, pushes through hard problems rather than giving up."
Each of those observations describes behavior that used to require external harness code to simulate. Retry loops, output validators, completeness checks, these are components I have written about as the Verification Layer in the Five Layers framework. In Opus 4.7, a version of them now lives inside the model.
Section 5 goes deep on what this means. For now, log the observation.
The maximum image resolution jumped from 1,568 pixels on the long edge (about 1.15 megapixels) to 2,576 pixels (about 3.75 megapixels). That is roughly three times the visual capacity. The practical implications are concrete: computer-use agents can now read dense screenshots, data extraction from complex diagrams is reliable, and the coordinate system maps one-to-one with actual pixels, eliminating the scale-factor math that used to be required.
XBOW, whose autonomous penetration testing work depends heavily on visual acuity, reports going from 54.5% to 98.5% on their internal visual benchmark. That is not an incremental gain. That is a capability that was previously unusable for production becoming production-ready.
The effort parameter now has five tiers: low, medium, high, xhigh, and max. The new tier, xhigh, sits between high and max. Claude Code defaults to xhigh for all plans. Anthropic recommends starting there for coding and agentic use cases.

Hex's CTO reports that "low-effort Opus 4.7 is roughly equivalent to medium-effort Opus 4.6." The floor has risen. For intelligence-sensitive work, Anthropic recommends a minimum of high. The xhigh tier exists because agentic workloads need deeper reasoning than high provides but not the full latency and token cost of max.
A new API feature lets you set a maximum token count per task. The model then prioritizes its work within that budget across long-running agent runs. This is a direct response to the cost control problem that agentic workloads introduced: when a model can run for hours, you need a way to cap spend before you find out the hard way.
Opus 4.7 is more direct than Opus 4.6. Less validation-seeking phrasing. Fewer emoji. More willingness to push back on user suggestions. Replit's president noted, "I love how it pushes back during technical discussions to help me make better decisions. It really feels like a better coworker." Opus 4.7 also calls tools less often by default, reasoning through problems internally rather than reaching for external capabilities.
If you built client-facing chat on Opus 4.6's warmer, validation-friendly style, Opus 4.7 will feel different. That is a system prompt re-tune, not a bug.
Opus 4.7 uses an updated tokenizer. The pricing sheet did not change: $5 per million input tokens, $25 per million output tokens. But the same input now maps to roughly 1.0 to 1.35 times as many tokens depending on content type. Combine that with the model's tendency to reason more deeply at higher effort levels, and you have a stealth cost increase. Anthropic's own migration guide says the net effect is favorable on their internal coding evaluation, but they explicitly recommend measuring the difference on real traffic before committing to a cutover.
This is the change that matters most for where this article is going. Opus 4.7 scored 73.1% on CyberGym, a vulnerability reproduction benchmark. Opus 4.6 scored 73.8%. The new model is slightly worse at cybersecurity tasks than its predecessor. Anthropic states, plainly, that "during its training we experimented with efforts to differentially reduce these capabilities."
Read that sentence carefully. A frontier lab, shipping its flagship model, tells you on launch day that they deliberately made the model worse at a specific skill, and that this was a training-time intervention, not a runtime filter. That is new. We will come back to it.
The benchmarks are real. Here they are, quickly, because they are not the point of this article.
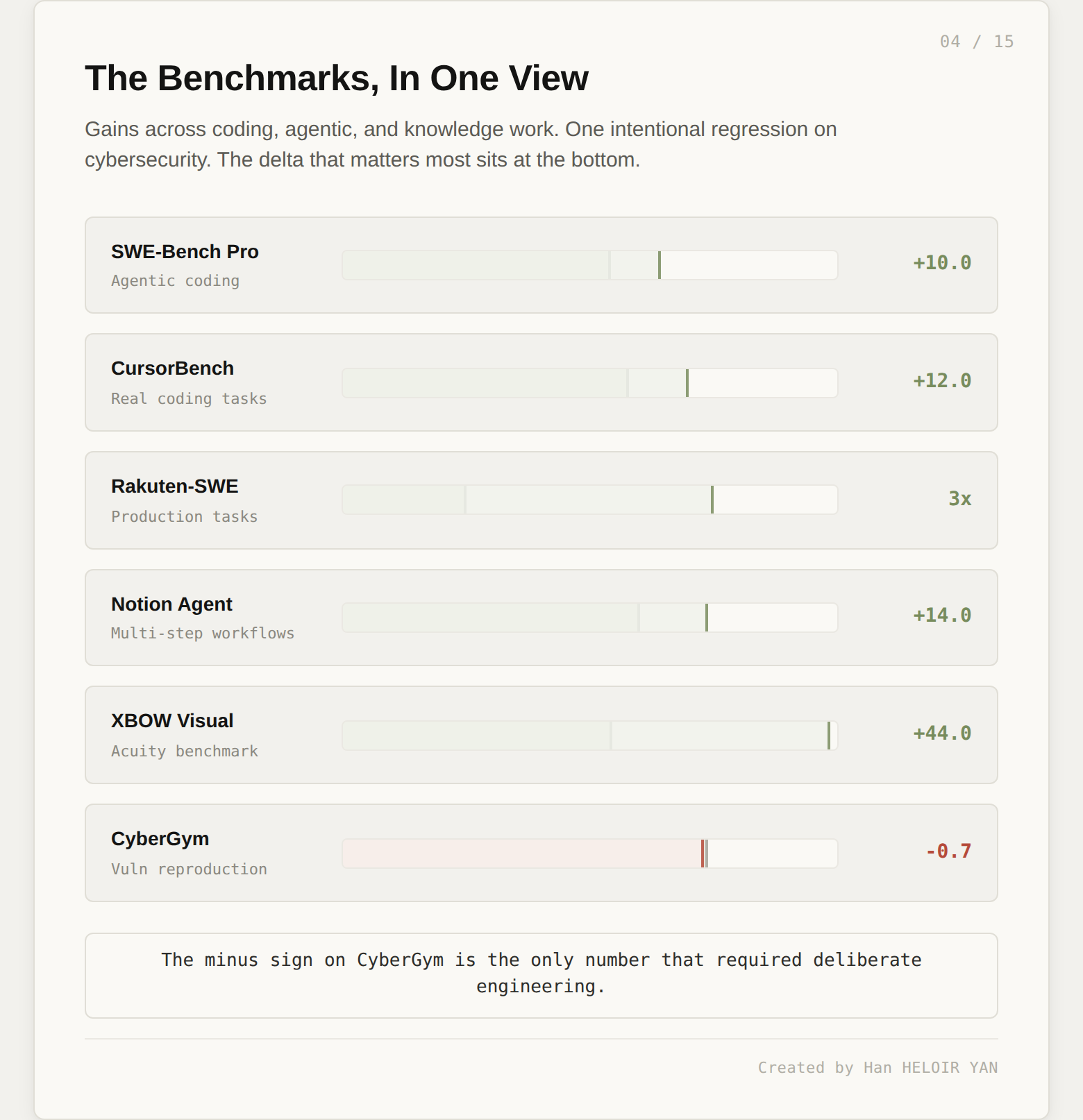
Opus 4.7 scored 64.3% on SWE-Bench Pro, roughly 10 points above Opus 4.6. On CursorBench, it cleared 70% versus 58% for its predecessor. On Rakuten's production-task benchmark, it resolved three times more tasks than Opus 4.6. Notion reports a 14% gain on complex multi-step workflows while using fewer tokens and a third of the tool errors. XBOW's visual acuity benchmark lifted from 54.5% to 98.5%. On GDPval-AA, a third-party evaluation of economically valuable knowledge work across finance and legal domains, Opus 4.7 is state-of-the-art.
These numbers are the headline partner testimonials that populate launch-day coverage. They are also exactly what you would expect from a model upgrade: better coding, better vision, better multi-step execution, better knowledge work.
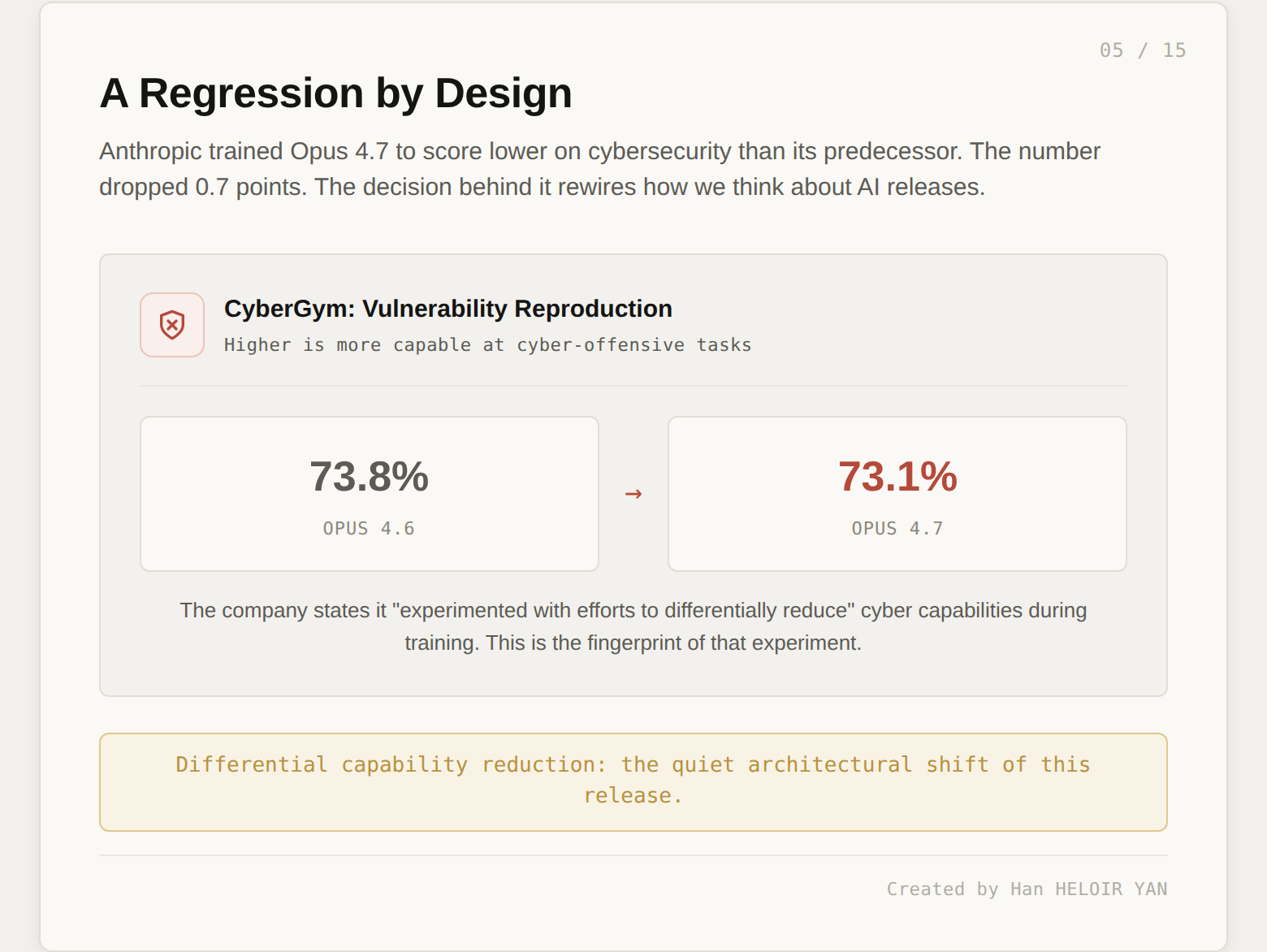
The interesting number is the one that went down. CyberGym: 73.8% on Opus 4.6, 73.1% on Opus 4.7. A 0.7 point regression. That looks like noise. It is not. It is the fingerprint of a deliberate training intervention, and the delta it represents is small precisely because Anthropic only suppressed one specific family of capabilities while the rest of the model lifted around it.
Every other benchmark says "the model got better." One benchmark, singled out by the training process, says "the model got intentionally worse." The rest of this article is about why that matters.
Two shifts arrived with Opus 4.7 that look unrelated. Self-verification: the model now checks its own outputs before reporting back. Differential capability reduction: the model was trained to be worse at a specific skill. These read like independent features. They are the same architectural decision wearing two different outfits.

The pattern is this: behavioral decisions are moving from runtime, where builders control them, into training, where the model company controls them. Self-verification used to live in your harness code. If you wanted the model's output checked, you wrote the check. You decided what counted as valid. You versioned the logic, you tested it, you could turn it off. In Opus 4.7, a version of that check now lives in the weights. Same goes for capability limits. Historically, if you wanted to prevent a model from helping with cybersecurity attacks, you wrote a classifier, a prompt filter, a policy check. Runtime control. In Opus 4.7, a version of that constraint lives in the weights too.
Both migrations have the same shape. The model company is expanding the set of behavioral decisions it makes on your behalf, and shrinking the set of decisions you make in your own code. That is the absorption.
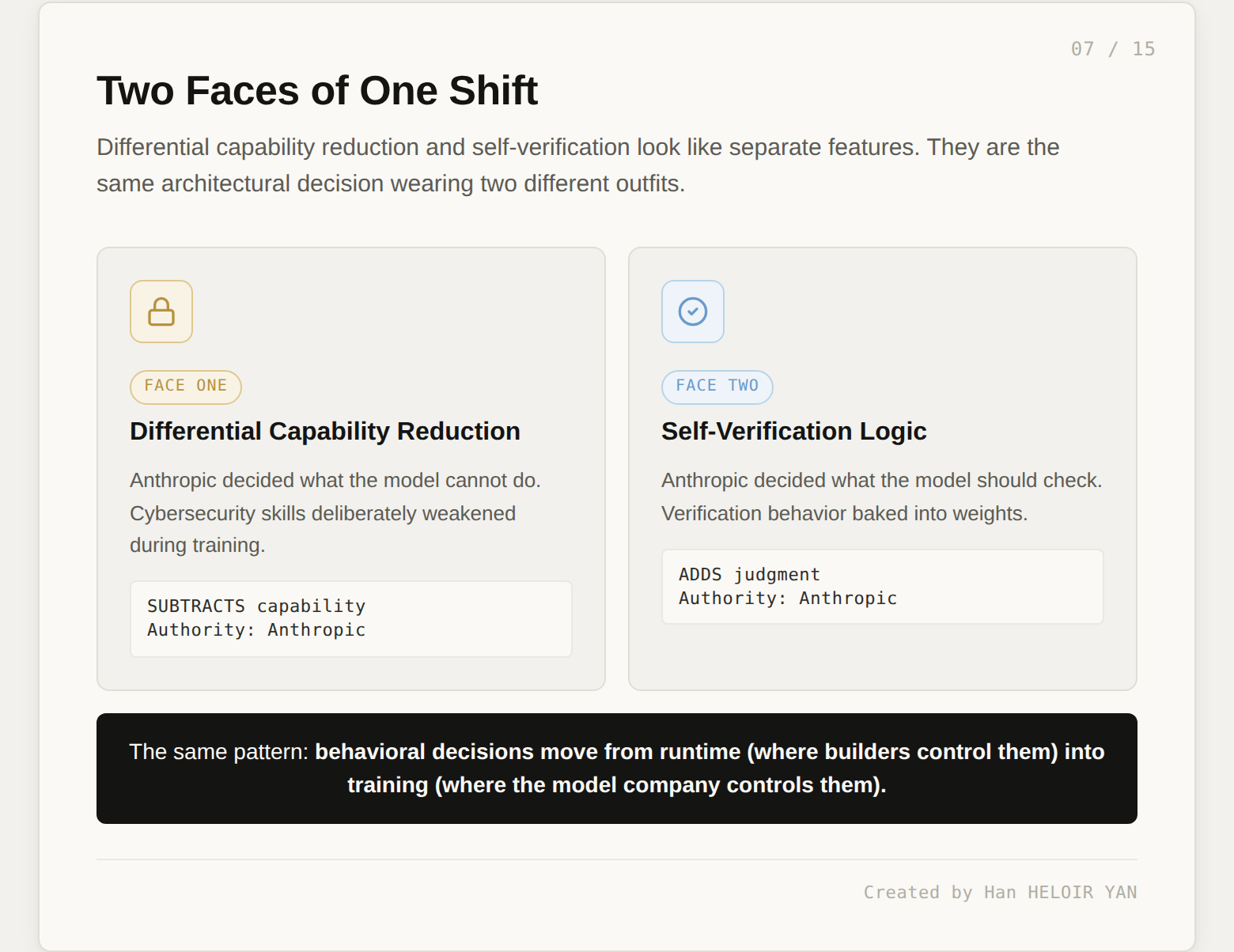
The thesis of this article, stated plainly: differential capability reduction and self-verification are two faces of the same shift. One subtracts capability. The other adds judgment. Both reduce your authority over what the model does.
The rest of the article examines each face in turn. Section 4 looks at the capability reduction face and what it signals about deployment strategy. Section 5 looks at the self-verification face and asks the harder question: if the model is offering to handle verification for you, should you let it? Section 6 translates both into practical guidance for teams shipping with Opus 4.7 today.
The conclusion will not be a clean "accept all absorption" or "reject all absorption." Some absorptions are genuinely useful. Others are the wrong people making decisions on your behalf. The work is telling them apart.
To understand why Opus 4.7's cybersecurity capability was deliberately weakened, you need to know about the model that was not released.
Claude Mythos Preview is, per Anthropic, their most capable model. A week before Opus 4.7 shipped, Anthropic announced Project Glasswing: a cybersecurity initiative built around Mythos, with twelve launch partners (Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, the Linux Foundation, Microsoft, Nvidia, Palo Alto Networks) and over forty additional organizations that build or maintain critical software infrastructure. Anthropic committed up to $100 million in usage credits and $4 million in donations to open-source security work.
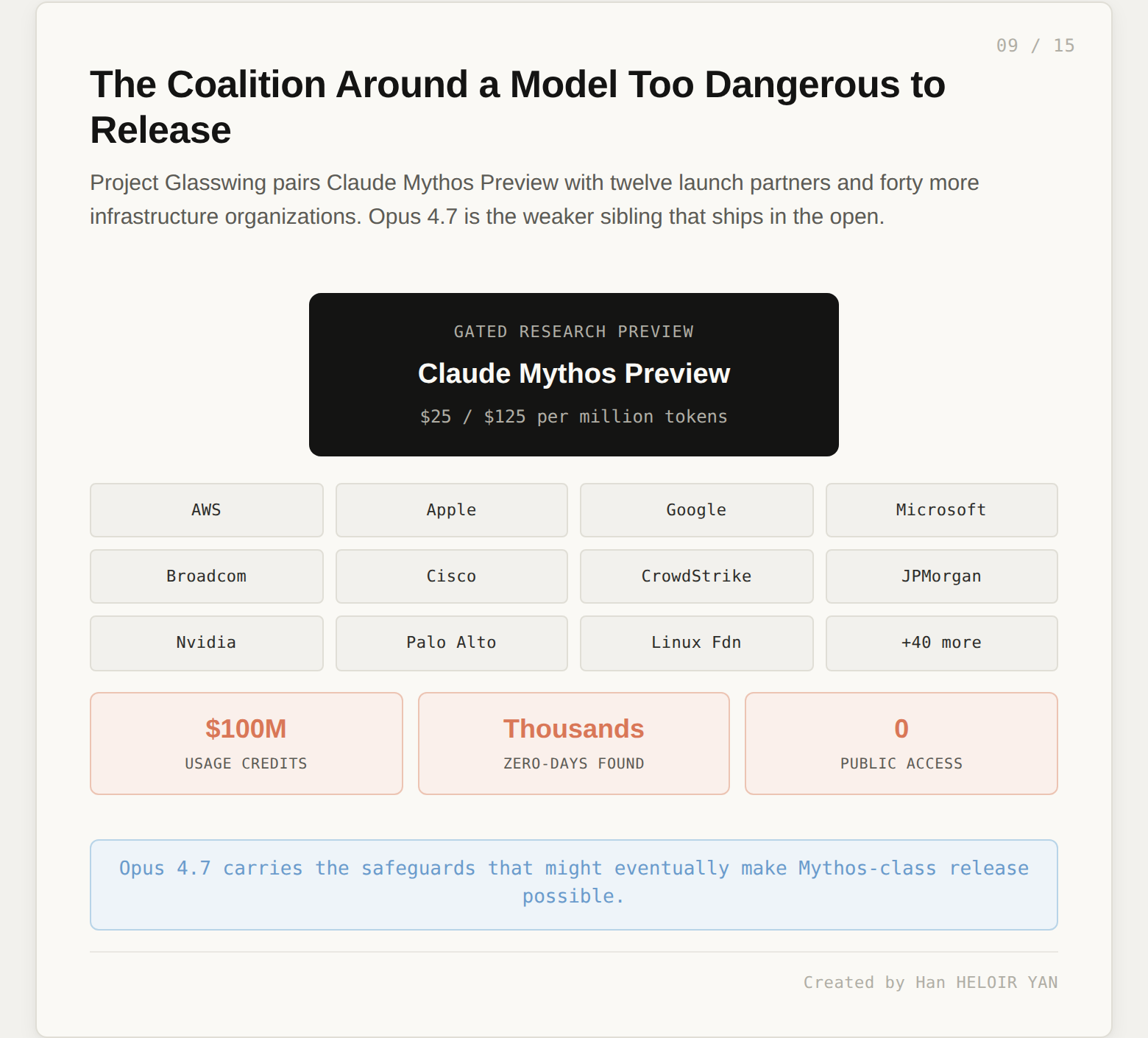
The stated reason for the coalition: Mythos has already found thousands of zero-day vulnerabilities across every major operating system, every major web browser, and a range of other critical software. Anthropic decided this capability was too dangerous to release broadly. So: a gated research preview, available to partners at $25 per million input tokens and $125 per million output tokens, with commitments to share findings industry-wide as zero-days are patched.
Opus 4.7 exists in the shadow of that decision. Anthropic needed to ship something, and Mythos was locked. So they shipped Opus 4.7 with safeguards layered on top, plus a deliberate training-time reduction in the cyber capabilities that made Mythos too risky to release. The launch post is explicit: "We are releasing Opus 4.7 with safeguards that automatically detect and block requests that indicate prohibited or high-risk cybersecurity uses. What we learn from the real-world deployment of these safeguards will help us work towards our eventual goal of a broad release of Mythos-class models."
That is a rehearsal. Opus 4.7 is the dress rehearsal for whatever comes next.
The technical novelty is the training intervention. Anthropic experimented with training signal modifications that preserve general intelligence while degrading specific dangerous skills. The 0.7 point CyberGym regression is the measurable outcome. Everything else in the model lifted. Coding got better. Vision got dramatically better. Knowledge work got better. Only the targeted capability went down.
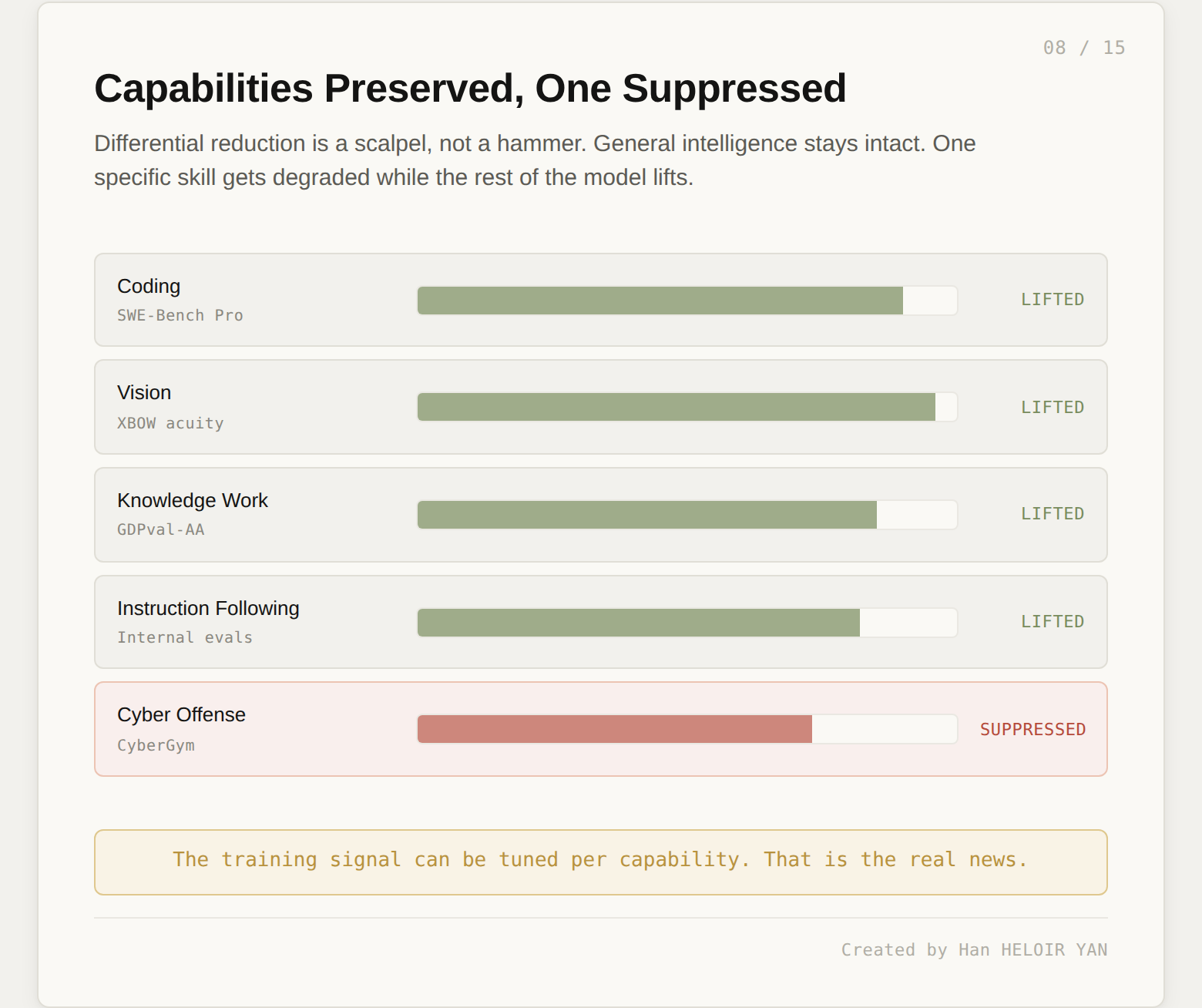
This is a scalpel, not a hammer. You cannot turn it off. You cannot inspect which capabilities were reduced or by how much. You cannot restore the capability for legitimate use without applying to Anthropic's Cyber Verification Program, which gates access to Opus 4.7's cyber capabilities for vulnerability research, penetration testing, and red-teaming work. You have to ask permission to use the model at the capability level it could have shipped with.
For the specific case of cybersecurity at frontier capability levels, this is probably correct policy. Frontier cyber capabilities in the wrong hands are genuinely dangerous. Mythos can chain vulnerabilities together in ways that would enable previously impossible attacks. The case for not releasing Mythos, and for suppressing Mythos-class capabilities in Opus 4.7, has real weight. Bruce Schneier, writing on his blog, called the surrounding Glasswing announcement "a PR play," but even he accepted the underlying security risks as credible.
The harder question is whether the pattern generalizes well. Anthropic decided which capability to reduce. They decided by how much. They decided who gets to apply for restoration. They decided what counts as a legitimate use case. All of those decisions are inside a black box that ships with the model. You cannot see the reduction, you cannot reason about its edges, you cannot test what it might miss.
This is fine when the reduction is clearly aligned with the public interest. What happens when the next reduction is aligned with a commercial interest instead? Or a political one? Or a contract the model company signed that you never saw? The mechanism is the same. Only the target changes.
The question to hold in mind: if Anthropic can selectively reduce capabilities you might need, the mechanism that lets them do that is the same mechanism that lets them selectively shape behavior you might disagree with. Differential capability reduction is a technical capability. The question of what it should be used for is a governance question, and right now there is no governance, just the model company's own judgment.
If capability reduction is absorption from above, self-verification is absorption from below. Something the builder used to own is now handled by the model, and the convenience is genuine enough that you have to think carefully about what you are giving up.
Opus 4.7 inserts a verification step inside its own reasoning loop. Plan, execute, verify, report. The verify step is new.
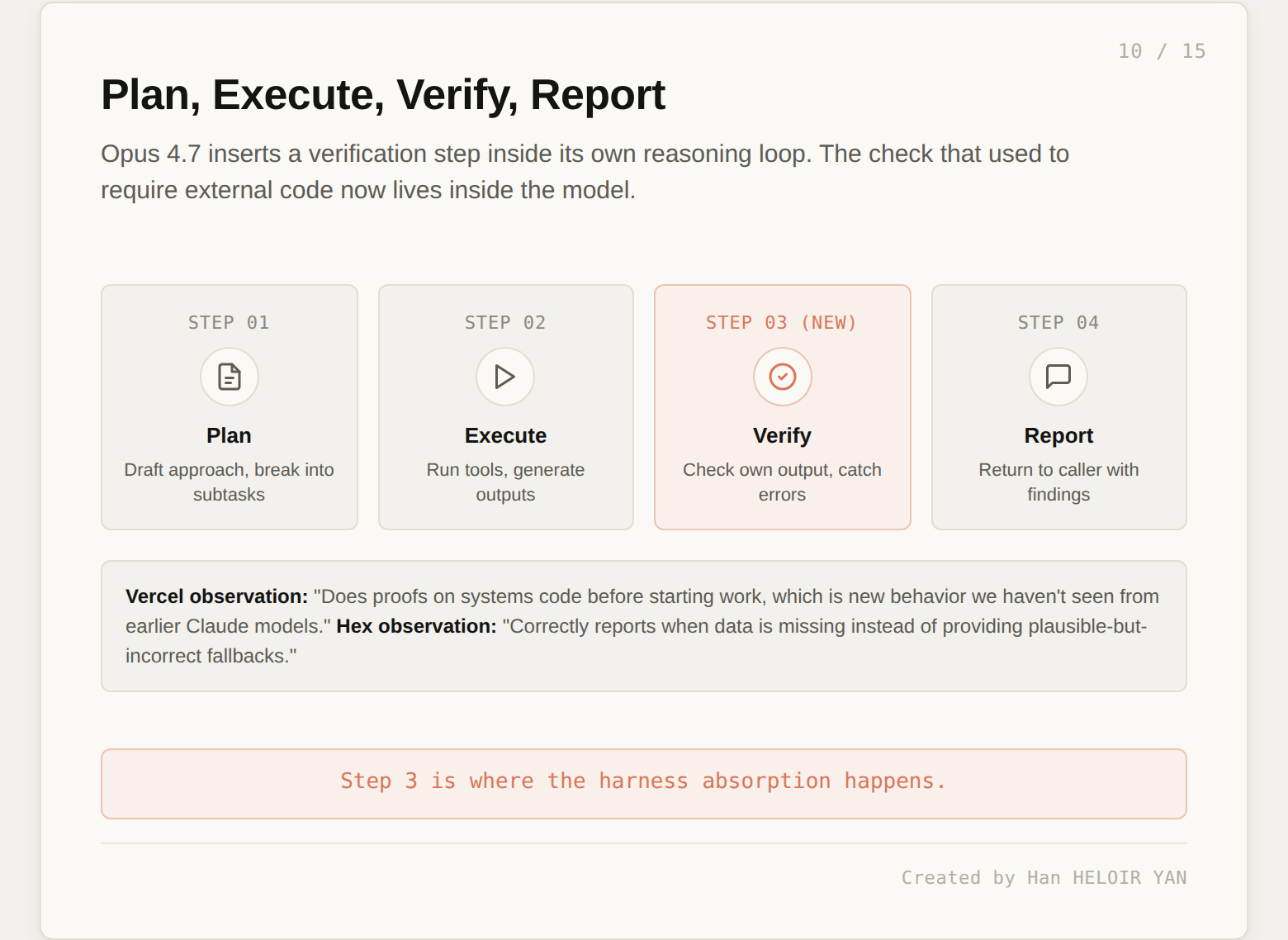
The partner testimonials tell you what the behavior looks like in practice. Vercel: "It does proofs on systems code before starting work, which is new behavior we haven't seen from earlier Claude models." Hex: "It correctly reports when data is missing instead of providing plausible-but-incorrect fallbacks, and it resists dissonant-data traps that even Opus 4.6 falls for." Cognition (Devin): "It works coherently for hours, pushes through hard problems rather than giving up, and unlocks a class of deep investigation work we couldn't reliably run before." Genspark: "The highest quality-per-tool-call ratio we've measured."
Taken together, these are descriptions of a model that catches its own mistakes before committing to them. A fair amount of what external validation code used to do is now happening inside the reasoning loop.
Self-verification is genuinely useful. Let's start there, honestly.
If the model catches an error before producing output, you save a round trip. No retry, no rerun, no downstream correction. That is lower latency. It is also lower token cost: catching an error at step three is cheaper than generating a bad output, having your validator reject it, and regenerating. The harness code gets simpler too. Fewer retry loops, fewer output validators for the easy cases, fewer boilerplate checks that were really just guarding against predictable hallucinations.
For the easy errors, the arithmetic is clear. Let the model catch them cheaply. That is the correct default, and the convenience is not marketing, it is real operational relief.
Now the hard part. A model verifying itself uses the same weights for both the generating step and the checking step. Same training signal. Same probability distribution. Same blind spots.
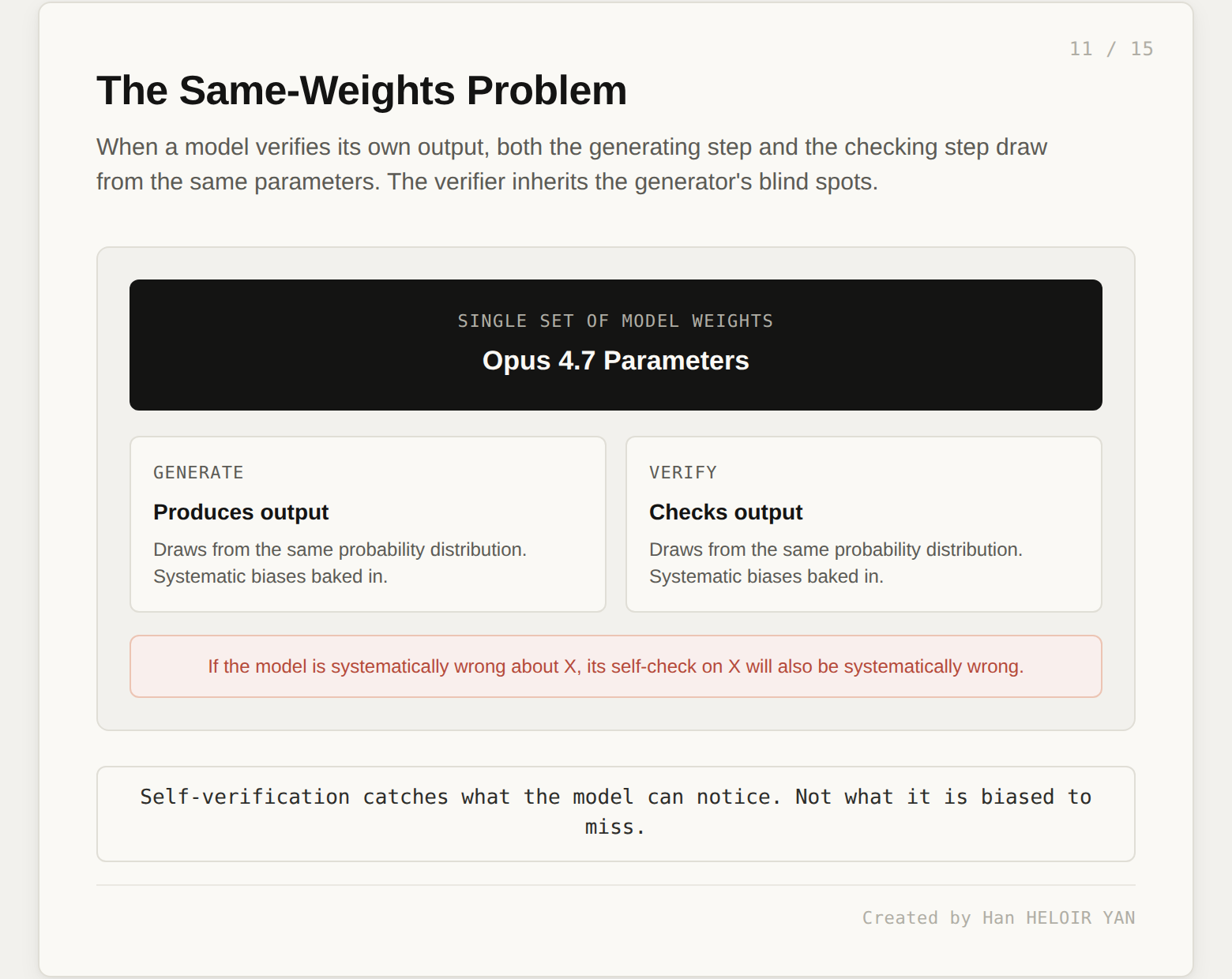
If the model has a systematic bias (a tendency to hallucinate a particular kind of API response, a habit of underestimating a particular risk, a training-data gap around a particular domain), its self-verification step inherits that bias. The generator produces a plausible-but-wrong output, the verifier looks at it, and both operations draw from the same probability distribution. The verifier is exactly as likely to accept the wrong output as the generator was to produce it in the first place.
This is not a bug you can prompt-engineer around. It is a structural property. You can prompt the model to "check your work carefully," and it will, within the limits of what the weights can notice. What the weights cannot notice is exactly what the weights are systematically wrong about, and no amount of self-checking will fix that, because the self-check uses the same weights.
Self-verification catches what the model is capable of noticing. It cannot catch the class of errors the model is systematically biased to miss. That is the class of errors that hurts you in production, because they are the ones that slip through without being flagged.
Set the same-weights problem aside for a moment. Suppose the model's self-check is genuinely capable. There is still a second question: when the model says "I have verified this," what does that mean?
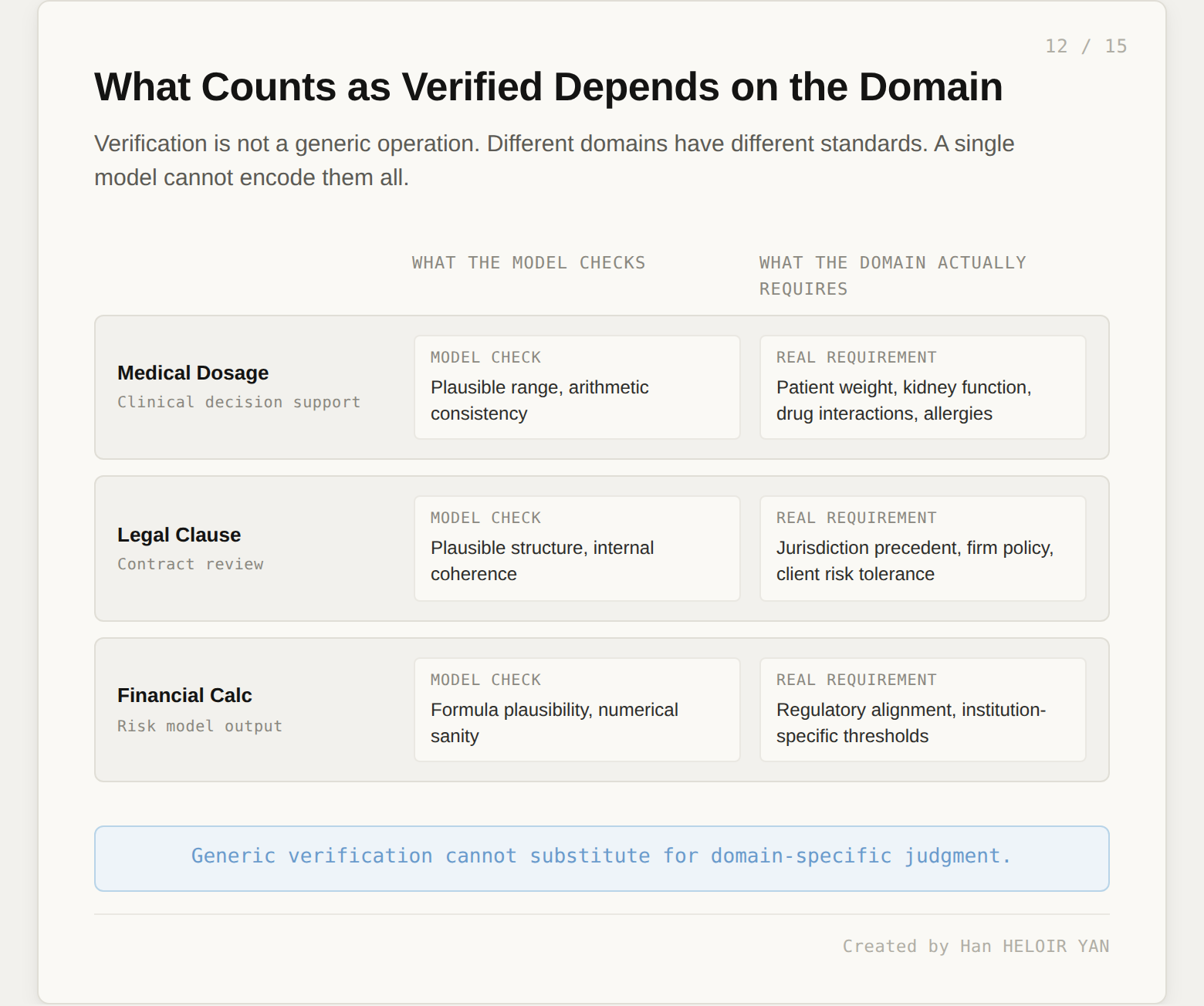
Verification is not a generic operation. It is a domain-specific operation. A medical platform checking a dosage recommendation needs to verify against patient weight, kidney function, drug interactions, and allergies. The model's self-check validates plausible range and arithmetic consistency, nothing more, because nothing more is in the weights. A legal platform reviewing a contract clause needs to verify against jurisdiction precedent, firm policy, and client risk tolerance. The model's self-check validates structural plausibility and internal coherence. A financial platform validating a risk model output needs to verify against regulatory alignment and institution-specific thresholds. The model's self-check validates numerical sanity.
In every case, the model's self-verification is necessary but not sufficient. The domain-specific verification the user actually needs cannot possibly be encoded into a general-purpose model that serves millions of customers across every industry. That is not a failure of the model. It is the nature of general intelligence versus domain expertise.
When verification logic lives in your harness code, you decide what "verified" means for your domain. You can audit the rules, you can version them, you can swap them when regulations change, you can turn them off for testing. When verification logic lives in model weights, Anthropic makes editorial choices about what counts as valid output. Those choices reflect their values, their training data, their commercial incentives, and the distribution of their customer base. For most cases, those choices are reasonable. For your specific domain, they may not be aligned, and you have no way to inspect them.
This is the same pattern as differential capability reduction, wearing different clothes. In Section 4, Anthropic decided what the model cannot do, and the decision was baked into weights you cannot inspect. Here, Anthropic has decided what the model should check about its own outputs, and that decision is also baked into weights you cannot inspect. Both are editorial choices made by the model company, during training, affecting every runtime interaction, without a runtime override.
Face one subtracts capability. Face two adds judgment. Both centralize authority.
The balanced answer is not to reject model self-verification. It is to understand what layer it belongs to.
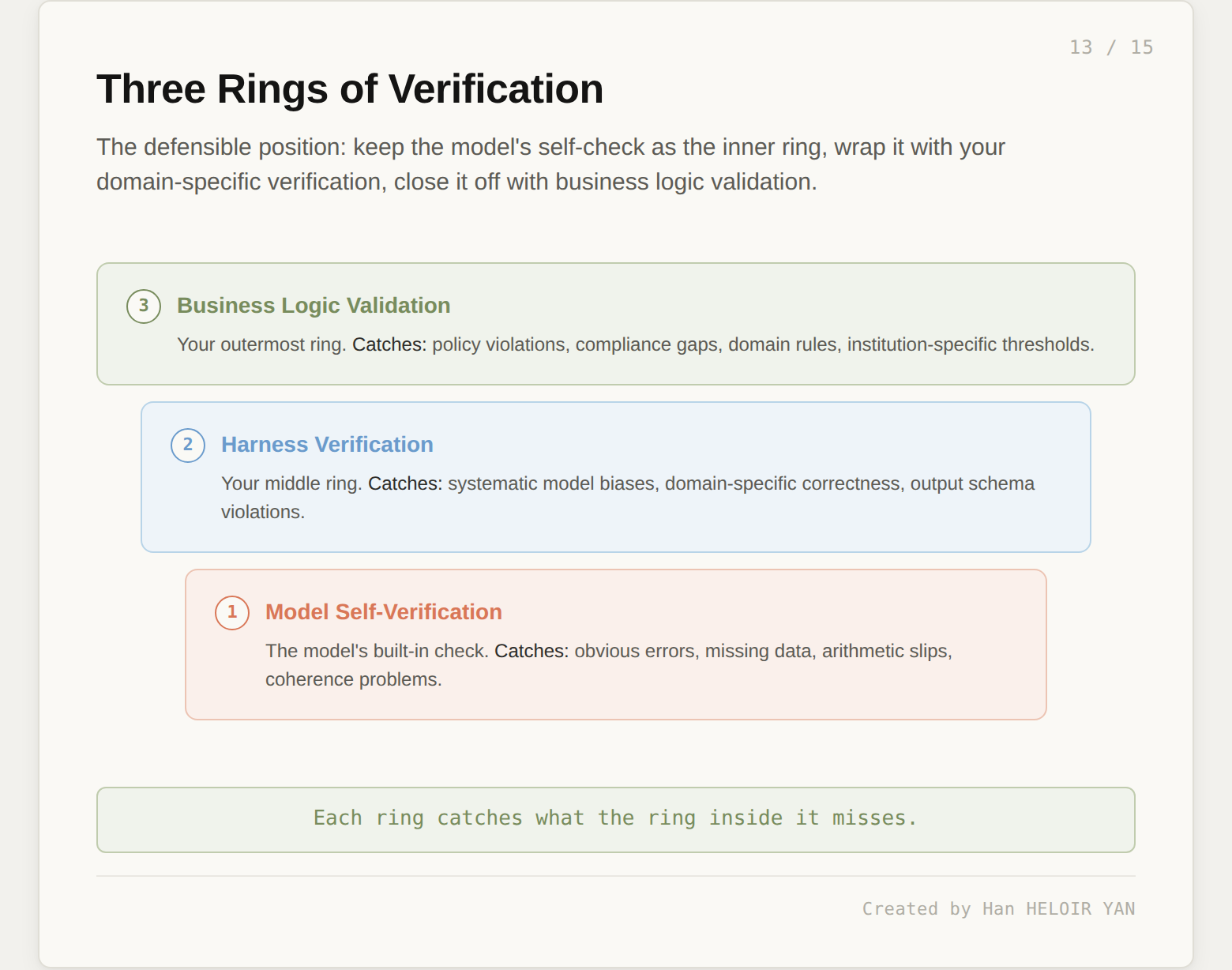
Treat model self-verification as the innermost ring. It catches obvious errors, arithmetic slips, missing data, coherence problems. It is cheap, fast, and closely coupled to the generation step. This is a real upgrade over what Opus 4.6 offered, and you should use it.
Wrap that ring with harness verification. Your code checks the model's output for the systematic errors you have seen in production, the domain-specific correctness rules that matter for your use case, and the output schema violations that are easy to detect deterministically. This is the ring that catches what the model's self-check cannot catch, because it is written by someone who knows your domain and has seen your traffic.
Wrap that ring with business logic validation. Policy violations, compliance gaps, regulatory thresholds, institution-specific rules. The outermost ring enforces the rules that were never going to fit in a general-purpose model anyway.
Each ring catches what the ring inside it misses. The model's self-check is now part of the system, not a replacement for it. That is the defensible position. Let the model do what it can do. Keep authority over the things that matter for your domain where it belongs: in your code, under your control.
Now the practical part. If you are shipping with Claude today, or planning to migrate from Opus 4.6, here is how to think about the move.

For coding and agentic work, start with xhigh. That is Claude Code's default, it is where most of the self-verification behavior kicks in, and it is where the partner testimonials you read in Section 1 were generated. Anthropic recommends a large max output token budget, at least 64,000, so the model has room to think and act across its reasoning and tool calls.
For classification, extraction, routing, and other structured work, high is the minimum for intelligence-sensitive tasks. Dropping below high disables a substantial portion of the reasoning depth you paid for, including much of the self-verification behavior. The low and medium tiers save tokens. They also produce a different agent, one closer to Opus 4.6 at comparable effort than to Opus 4.7 at its best.
Reserve max for tasks where you have already tried xhigh and the output is still insufficient. The cost jump is real, the latency jump is real, and most of the time xhigh is enough.
Pricing did not change. Effective cost probably did. The new tokenizer maps the same input to 1.0 to 1.35 times as many tokens depending on content type. Combined with the model's tendency to think more deeply at higher effort levels, you should budget for 15 to 35 percent more tokens on equivalent work. Anthropic's own data suggests the net effect may be favorable on complex workloads because the model produces better output with fewer wasted tool calls, but that is a workload-dependent claim. Measure it on your traffic before you trust it.
Task budgets, now in beta, are your friend here. Set a cap per task and let the model prioritize. This is especially important for long-running agents where a single run could otherwise consume an unbounded number of tokens. Without a budget, you only find out about the cost after the bill arrives.

Five concrete risks, each with a fix.
Loose prompts break. Anything that said "format this nicely" or "handle the edge cases" or "make sure the output is good" relied on Opus 4.6's loose interpretation. Opus 4.7 needs explicit scope: "apply this to every item in the list, not just the first." Re-read your prompt library with fresh eyes and assume any instruction that a literal contractor could interpret three different ways will be interpreted in whichever way causes you the most trouble.
Warmer tone is gone. If your client-facing chat depended on Opus 4.6's friendlier style, Opus 4.7 will feel colder. This is a system prompt re-tune. Specify the emoji policy, the validation style, and the willingness to agree with user framing you want. The model has the range, it just defaults to a different place.
Fewer tool calls can look like stalling. If your orchestration monitors tool call frequency as a liveness signal, you may misread reasoning as stalling. The model is deliberately calling tools less and reasoning more. Update your liveness checks to read reasoning output, not just tool-call telemetry.
Tokenizer cost creep. Track token usage on real workloads. Do not assume the price per task is comparable between Opus 4.6 and Opus 4.7 just because the per-token price is identical. Run a week of parallel traffic on both models if you can, and make the migration decision with numbers, not vibes.
Prefill is still blocked. Assistant message prefill still returns a 400 error (this was introduced in Opus 4.6 and carries forward). Use structured outputs, system prompt instructions, or output_config.format if you were relying on prefill.
Longer runs need longer timeouts. Opus 4.7 at xhigh and max thinks longer. If your infrastructure has tight request timeouts, raise them. Start with 64,000 max output tokens and tune from there based on real traffic.
Whichever effort level you choose, whichever migration path you take, keep your verification layer. The model's self-check is now part of the system, not a replacement for your controls. Treat it as an inner ring that catches the easy errors cheaply, wrapped in your harness verification, wrapped in your business logic validation. Three rings, each catching what the ring inside it misses.
A specific test worth running: take your hardest workload, run it through Opus 4.7 at xhigh with your existing verification layer in place. Log every error the model self-catches, every error that makes it past the self-check but is caught by your harness, and every error that makes it all the way through. The first number tells you what the absorption is buying you. The second tells you what your harness is still worth. The third tells you where you still need to add defense.
Three things to take with you.
Opus 4.7's real significance is not its benchmarks. It is architectural. The model is absorbing responsibilities that used to live in your code (self-verification), and the model company is absorbing decisions that used to live with you (differential capability reduction). Both shifts are in the same direction: authority moving from runtime into training, from the builder into the model company.
The absorption has two faces. One subtracts capability (what the model cannot do). One adds judgment (what the model decides is correct). The thesis of this article is that they are the same pattern, and the question they pose to builders is the same: what behavioral decisions should live inside the model, and what should live with the people deploying it?
Your defensible position is not to reject absorption, but to layer it. Accept the convenience of self-verification as a first filter. Keep authoritative verification in your harness. Extend that principle broadly: every capability the model absorbs, ask who loses authority and whether that trade is acceptable for your domain. Some absorptions are genuinely useful. Others are the wrong people making decisions on your behalf. The work is telling them apart.
A specific experiment for this week: run Opus 4.7 at xhigh on your hardest current workload, alongside your existing verification layer. Measure which errors the model self-catches, which slip through, and which your harness catches. That ratio tells you where the absorption helps and where it masks risk that still belongs to you. That is the number to report to your team, not the benchmarks.
The bigger question is harder and worth sitting with. When Mythos-class capabilities eventually reach open models, differential capability reduction will not be an option for the open-source community. The safeguards Anthropic is testing on Opus 4.7 are a rehearsal for a moment that is coming whether or not the major labs are ready. The model that ships next year will make the governance questions this release raises feel overdue.