Every time you ask an LLM a question about your documents, it starts from scratch. It retrieves chunks, pieces together fragments, generates an answer, and forgets everything the moment the session ends. Ask the same question tomorrow and it repeats the entire process. Nothing compounds. Nothing accumulates. Your knowledge stays raw.
Karpathy proposed a fix. Instead of retrieving from raw documents at query time, have the LLM build a persistent wiki: structured markdown pages that get richer with every source you add. He called it LLM Wiki. 5,000 stars in eight days. Fifteen implementations in the first week.
Every one of them built the wiki layer. Almost none of them built the layer that actually matters.
If this helps you ship better AI systems:
👏 Clap 50 times (yes, you can!) Medium's algorithm favors this, increasing visibility to others who then discover the article.
🔔 Follow me on Medium, LinkedIn and subscribe to get my latest article.
The April 4, 2026 GitHub Gist is not a framework, not a library, not a product. It is an "idea file" designed to be copy-pasted into an LLM agent. The core claim: most people's experience with LLMs and documents looks like RAG, and RAG has a fundamental flaw.
With RAG, you upload documents, the LLM retrieves relevant chunks at query time, and generates an answer. It works. But the LLM is rediscovering knowledge from scratch on every question. Ask a subtle question that requires synthesizing five documents, and the system has to find and piece together the relevant fragments every time. Nothing is built up. NotebookLM, ChatGPT file uploads, and most RAG systems work this way.
Karpathy's alternative: instead of retrieving from raw documents, the LLM incrementally builds and maintains a persistent wiki. Structured markdown pages, interlinked, with cross-references and synthesis that reflect everything you have ever read. The knowledge is compiled once and kept current, not re-derived on every query.
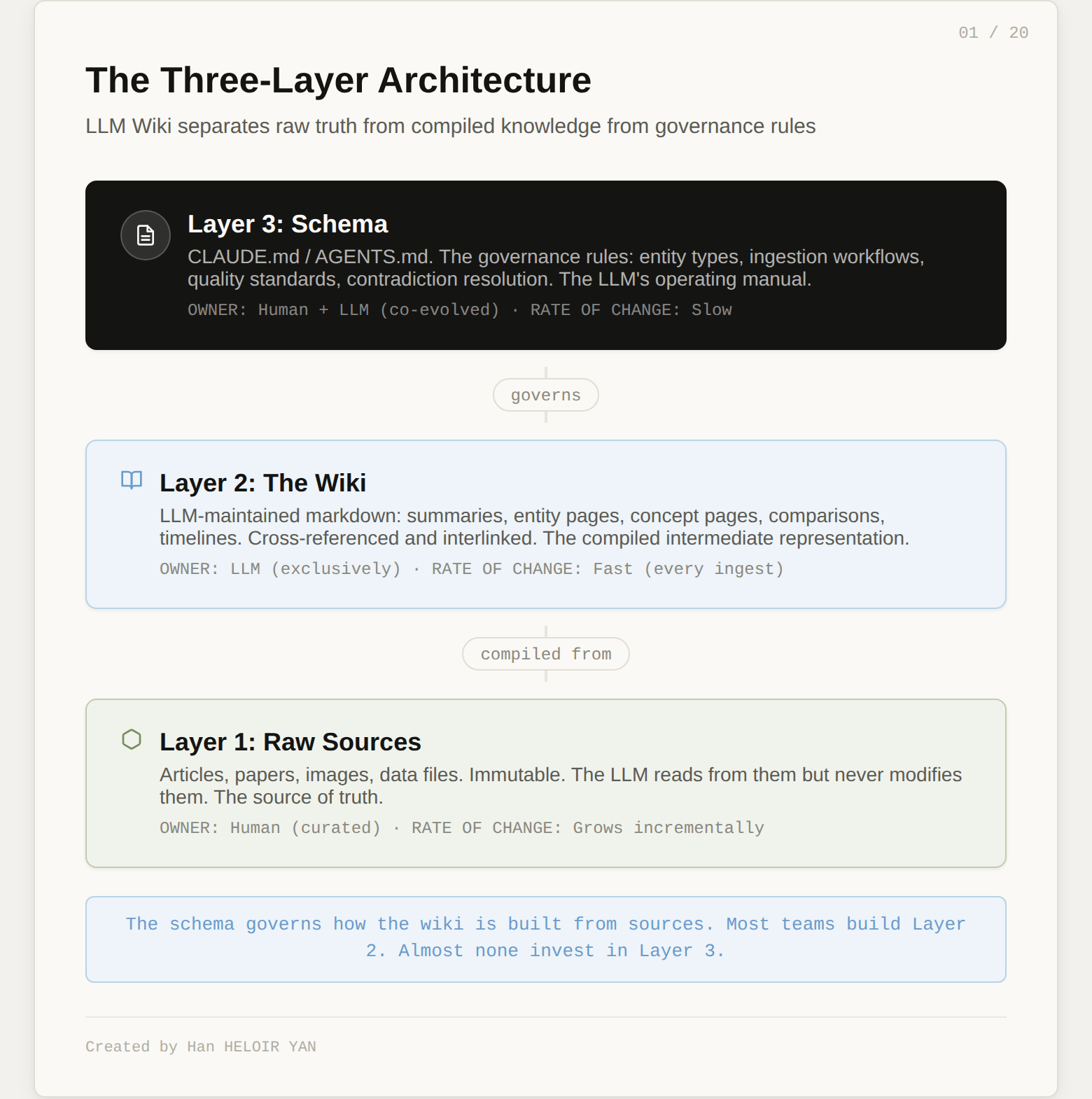
The architecture has three layers.
Raw sources. Your curated collection of documents: articles, papers, images, data files. These are immutable. The LLM reads from them but never modifies them. This is your source of truth.
The wiki. A directory of LLM-generated markdown files: summaries, entity pages, concept pages, comparisons, timelines. The LLM owns this layer entirely. It creates pages, updates them when new sources arrive, maintains cross-references, and keeps everything consistent. You read it. The LLM writes it.
The schema. A governance document (CLAUDE.md for Claude Code, AGENTS.md for Codex) that tells the LLM how the wiki is structured, what conventions to follow, and what workflows to execute when ingesting sources, answering questions, or maintaining the wiki. This is the configuration file that turns a generic chatbot into a disciplined wiki maintainer. You and the LLM co-evolve it over time.
Three operations keep the system alive.
Ingest. You drop a new source into the raw collection. The LLM reads it, writes a summary page, updates the index, updates relevant entity and concept pages across the wiki, and appends an entry to the log. A single source might touch 10 to 15 wiki pages.
Query. You ask questions against the wiki. The LLM searches for relevant pages, reads them, and synthesizes an answer with citations. Good answers can be filed back into the wiki as new pages. Your explorations compound in the knowledge base just like ingested sources do.
Lint. Periodically, the LLM health-checks the wiki. It looks for contradictions between pages, stale claims, orphan pages with no inbound links, important concepts mentioned but lacking their own page, and missing cross-references.

Two special files help navigate the growing wiki. index.md is a catalog of every page with one-line summaries. log.md is an append-only chronological record of operations. The LLM reads the index first to find relevant pages, then drills into them. Karpathy reports this works surprisingly well at moderate scale: roughly 100 sources, a few hundred pages, around 400,000 words.

Before going further, the pattern deserves its credit. It solves a real problem that knowledge workers hit every day.
The first shift is from stateless to stateful. RAG systems treat every query as independent. The LLM Wiki accumulates. Every source you add makes the wiki richer. Every question you ask can feed back into the base. After fifty ingested articles, the synthesis already reflects connections across all of them. With RAG, the fiftieth query is just as expensive as the first. With a wiki, it is cheaper and more informed.

The second shift is the role inversion. In traditional knowledge management, the human organizes and the tool stores. In LLM Wiki, the human directs and the LLM organizes. Karpathy's framing is precise: "Obsidian is the IDE, the LLM is the programmer, the wiki is the codebase." You never (or rarely) write the wiki yourself. You source, you explore, you ask good questions. The LLM does the summarizing, cross-referencing, filing, and bookkeeping.
This matters because bookkeeping is why knowledge bases die. Not lack of knowledge. Not lack of good intentions. The maintenance burden grows faster than the value. LLMs do not get bored. They do not forget to update a cross-reference. They can touch fifteen files in a single pass. The wiki stays maintained because the cost of maintenance drops to near zero.

The third shift is knowledge as artifact. Chat conversations are ephemeral. Search results are transient. The wiki is a persistent, versioned, browsable artifact. It lives in a git repo. You can branch it. You can share it. You can open it in Obsidian and see the shape of your knowledge in graph view: what connects to what, which pages are hubs, which are orphans.
The community response was not hype. It was recognition. 5,000 stars in eight days because this names a pain that thousands of knowledge workers feel but had no vocabulary for.
Karpathy says: "Obsidian is the IDE, the LLM is the programmer, the wiki is the codebase." Take that metaphor one step further and the real architecture reveals itself.
This is a compiler.
Raw sources are source code. Human-authored, in various formats, representing the ground truth. Ingest is the compilation pass. The LLM reads the source, parses it, extracts structured information, and emits it in a new representation. The wiki is the intermediate representation (IR). Structured, optimized for machine reading, with cross-references that serve as the equivalent of symbol tables. Query is linking and code generation. The LLM reads the IR, resolves references, and produces an executable output (the answer). Lint is the optimization pass. Dead code detection (orphan pages), constant propagation (consolidating redundant claims), and type checking (contradiction detection).

This is not a decorative analogy. It is architecturally precise. And once you see LLM Wiki as a compiler, compiler theory tells you exactly what is missing.
A compiler without optimization passes produces bloated output. A compiler without type checking produces output that looks correct but fails at runtime. A compiler without incremental compilation forces you to rebuild from scratch every time a source changes.
The LLM Wiki, as Karpathy published it, has the front end (parsing), the IR (the wiki), and a basic linker (query). It has a rudimentary optimization pass (lint). What it does not have is the machinery that separates a toy compiler from a production one: lifecycle management, quality verification, and incremental update semantics.

That machinery exists. rohitg00 published it four days after Karpathy's gist.
The original LLM Wiki treats every claim in the wiki as equally valid forever. The summary you wrote on day one carries the same weight as the summary you wrote yesterday. There is no mechanism for claims to weaken with time. No formal process for new information to supersede old. No distinction between "I saw this once in a single source" and "this is confirmed across twelve documents over three months."
This creates predictable failure modes that map directly to compiler defects.
No dead code elimination. The wiki never forgets. Pages accumulate. Old summaries sit alongside new ones. Claims that were accurate three months ago but have been superseded by newer sources remain in the wiki, unmarked, indistinguishable from current knowledge. In a compiler, this is dead code: unreachable instructions that bloat the binary and confuse the developer. In a wiki, it is stale knowledge that misleads the reader.
No type checking. When the LLM integrates a new source, it writes prose that fits naturally with the surrounding context. If the source contains an error, or if the LLM misinterprets something, that error gets woven into the wiki seamlessly. It looks coherent. It reads well. It is wrong. This is false coherence: errors that compound through integration and become internally consistent. You cannot detect them by reading the wiki because they fit the surrounding context. In a compiler, this is a type error that passes compilation but fails at runtime.
No incremental compilation semantics. The gist describes ingesting sources one at a time. But what happens when you ingest source 47 and it contradicts something from source 12? The wiki needs to update every page that source 12 touched. Without a dependency graph tracking which claims came from which sources, the system cannot propagate updates. Empirical evidence supports this concern. In a head-to-head test on a 50,000-line production codebase, a partially compiled wiki performed 17% worse than a fully compiled one. A "mostly finished" compilation is not almost as good. It is significantly worse.
No linking warnings. Orphan pages with no inbound links are invisible. Concepts mentioned in prose but never given their own page create dead references. Cross-references break silently as pages get rewritten. The lint operation in the original gist detects some of these, but only when you remember to run it. There is no continuous integration for knowledge.
No compilation provenance. When the wiki says "Project X uses Redis for caching," you have no way to know where that claim originated. Was it extracted from a primary source? Was it inferred by the LLM during synthesis? Was it accurate when written but superseded by a newer source? Without provenance tracking, every claim is equally trustworthy, which means none of them are.

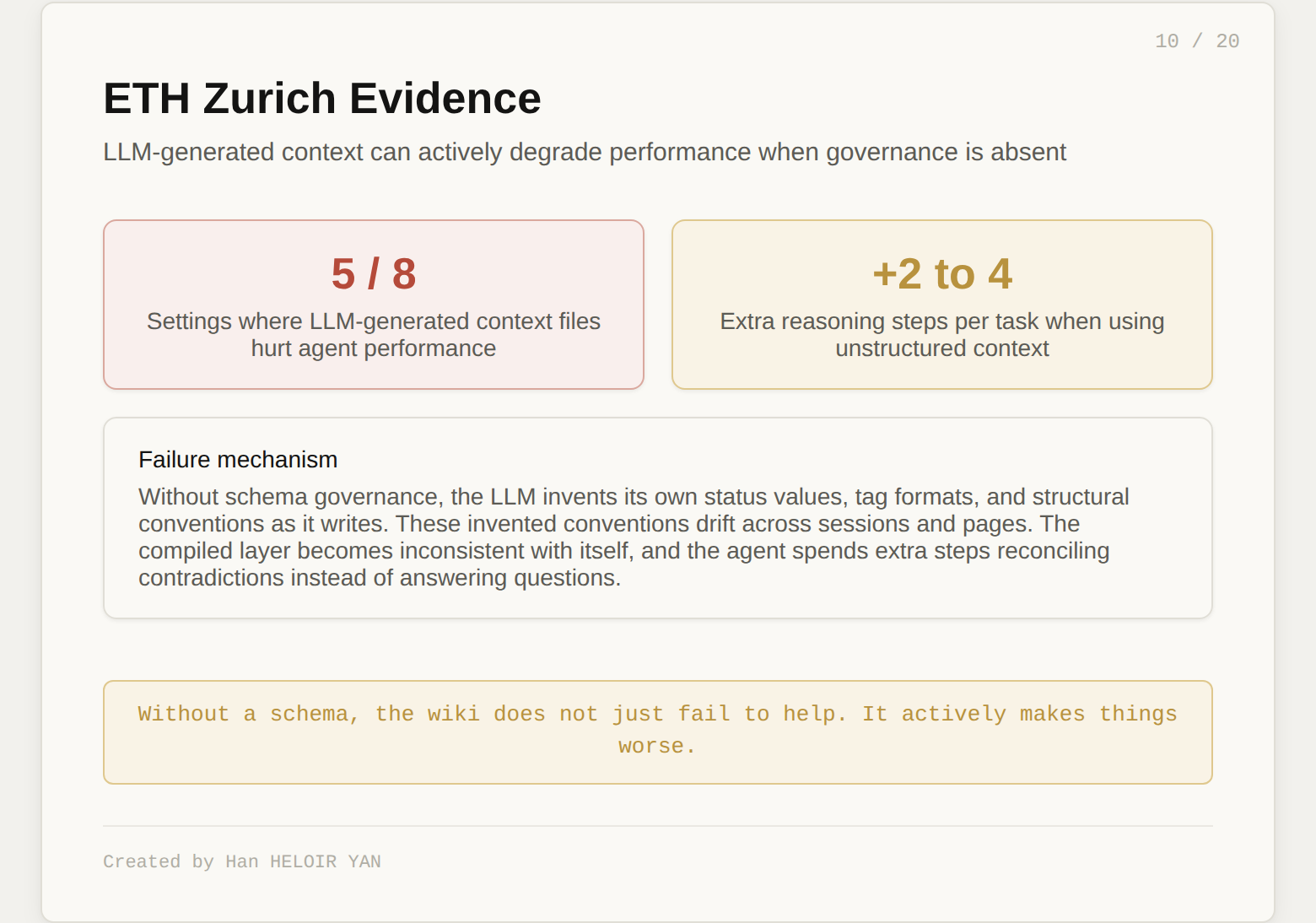
These are not theoretical risks. ETH Zurich found that LLM-generated context files actually hurt agent performance in 5 out of 8 tested settings, adding 2 to 4 extra reasoning steps per task. The failure mechanism: the LLM invents its own schema, status values, and tag formats as it writes. Without governance, the compiled layer actively degrades the system it was meant to improve.
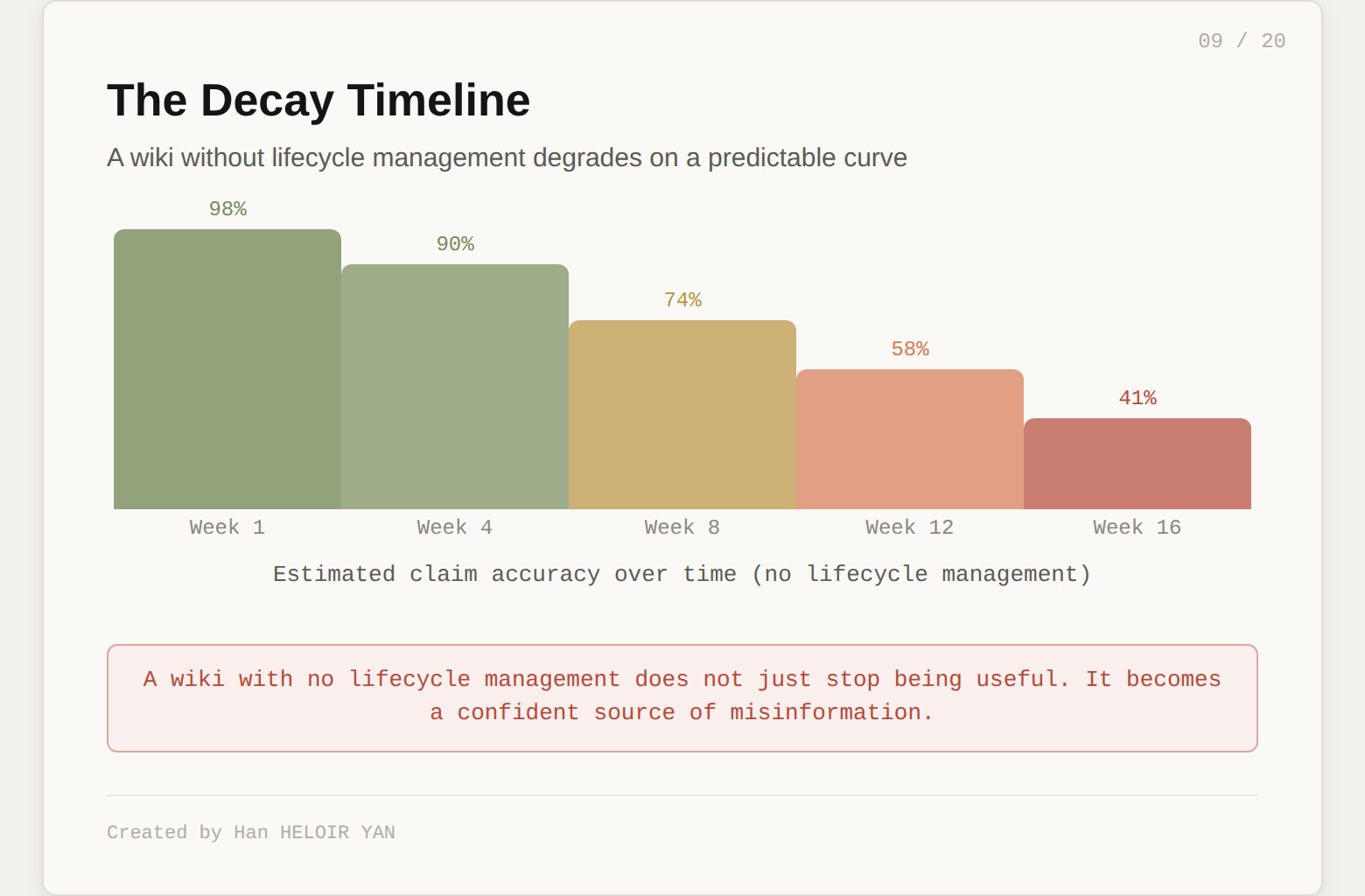
A wiki with no lifecycle management does not just stop being useful. It becomes a confident source of misinformation.
Four days after Karpathy's gist, rohitg00 published an extension titled "LLM Wiki v2" with a direct opening: "Everything in the original still applies. This document adds what we learned running the pattern in production: what breaks at scale, what's missing, and what separates a wiki that stays useful from one that rots."
The v2 addresses every failure mode identified above with concrete lifecycle mechanisms.
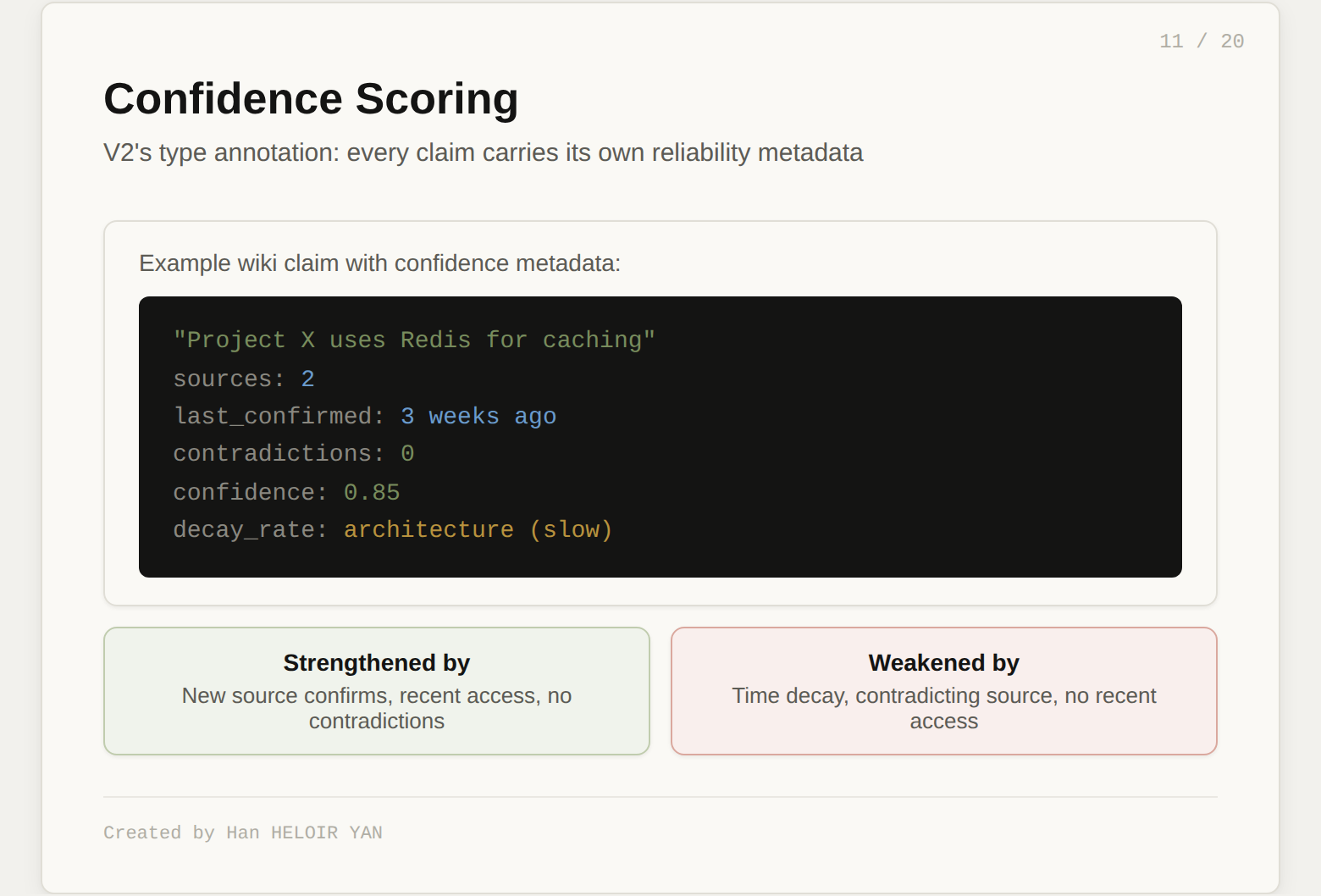
Confidence scoring. Every fact in the wiki carries a confidence score: how many sources support it, how recently it was confirmed, whether anything contradicts it. When the wiki says "Project X uses Redis for caching," that claim knows it came from two sources, was last confirmed three weeks ago, and sits at confidence 0.85. Confidence decays with time and strengthens with reinforcement. The wiki becomes a model where the LLM can say "I am fairly sure about X but less sure about Y." In compiler terms, this is type annotation: every expression carries its type, and the type checker can warn you when types weaken or conflict.
Supersession. When new information contradicts an existing claim, the old claim does not just sit there with a note. The new one explicitly supersedes it. Linked, timestamped, old version preserved but marked stale. This is version control for knowledge, not just for files. In compiler terms, this is constant folding: when a newer, more precise value is available, the old one gets replaced and the replacement is tracked.
Forgetting curves. Not everything should live forever. A wiki that never forgets becomes noisy. The v2 implements a retention curve modeled on Ebbinghaus's forgetting research: retention decays exponentially with time, but each reinforcement (access, confirmation from a new source) resets the curve. Architecture decisions decay slowly. Transient bugs decay fast. Facts that were important once but have not been accessed or reinforced in months gradually fade. Not deleted, but deprioritized. In compiler terms, this is dead code elimination with a grace period.
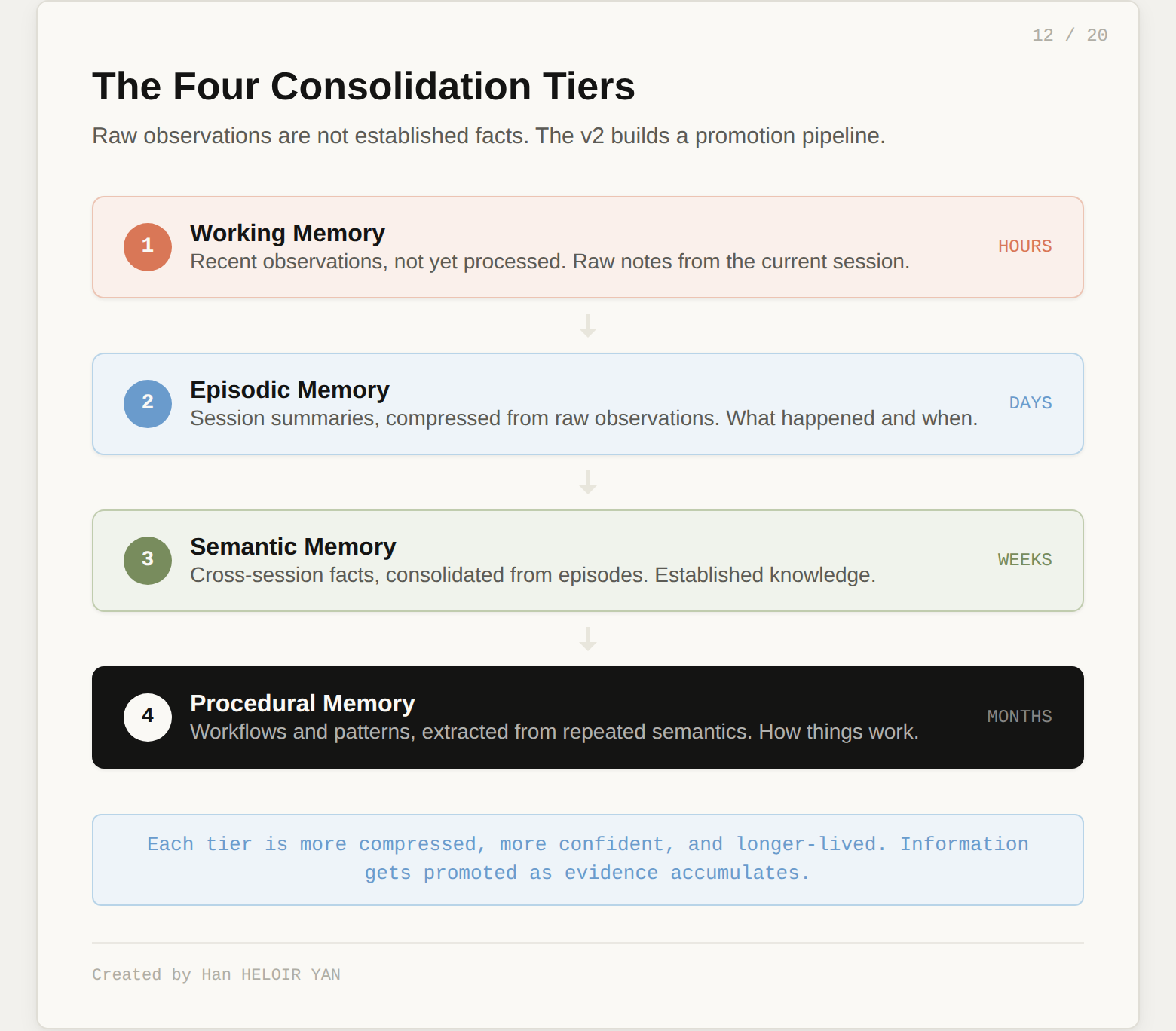
Consolidation tiers. Raw observations are not the same as established facts. The v2 builds a four-stage pipeline. Working memory holds recent observations, not yet processed. Episodic memory compresses them into session summaries. Semantic memory consolidates cross-session facts. Procedural memory extracts workflows and patterns from repeated semantics. Each tier is more compressed, more confident, and longer-lived than the one below it. The LLM promotes information up the tiers as evidence accumulates. In compiler terms, this is an optimization pipeline: each pass produces a more refined representation.

Quality scoring and self-healing. Every piece of content the LLM writes gets a quality score. Is it well-structured? Does it cite sources? Is it consistent with the rest of the wiki? Content below a threshold gets flagged for review or rewritten. The lint operation becomes automatic, not manual. Orphan pages get linked or flagged. Stale claims get marked. Broken cross-references get repaired. The wiki tends toward health on its own.
Contradiction resolution. The original mentions flagging contradictions. The v2 resolves them. The LLM proposes which claim is more likely correct based on source recency, source authority, and the number of supporting observations. The human can override, but the default behavior should handle most cases correctly.
The v2 also adds event-driven automation. On new source: auto-ingest. On session start: load relevant context. On session end: compress and file insights. On query: check if the answer is worth filing back. On memory write: check for contradictions. On schedule: periodic lint and retention decay. The human stays in the loop for curation and direction. The bookkeeping is fully automated.

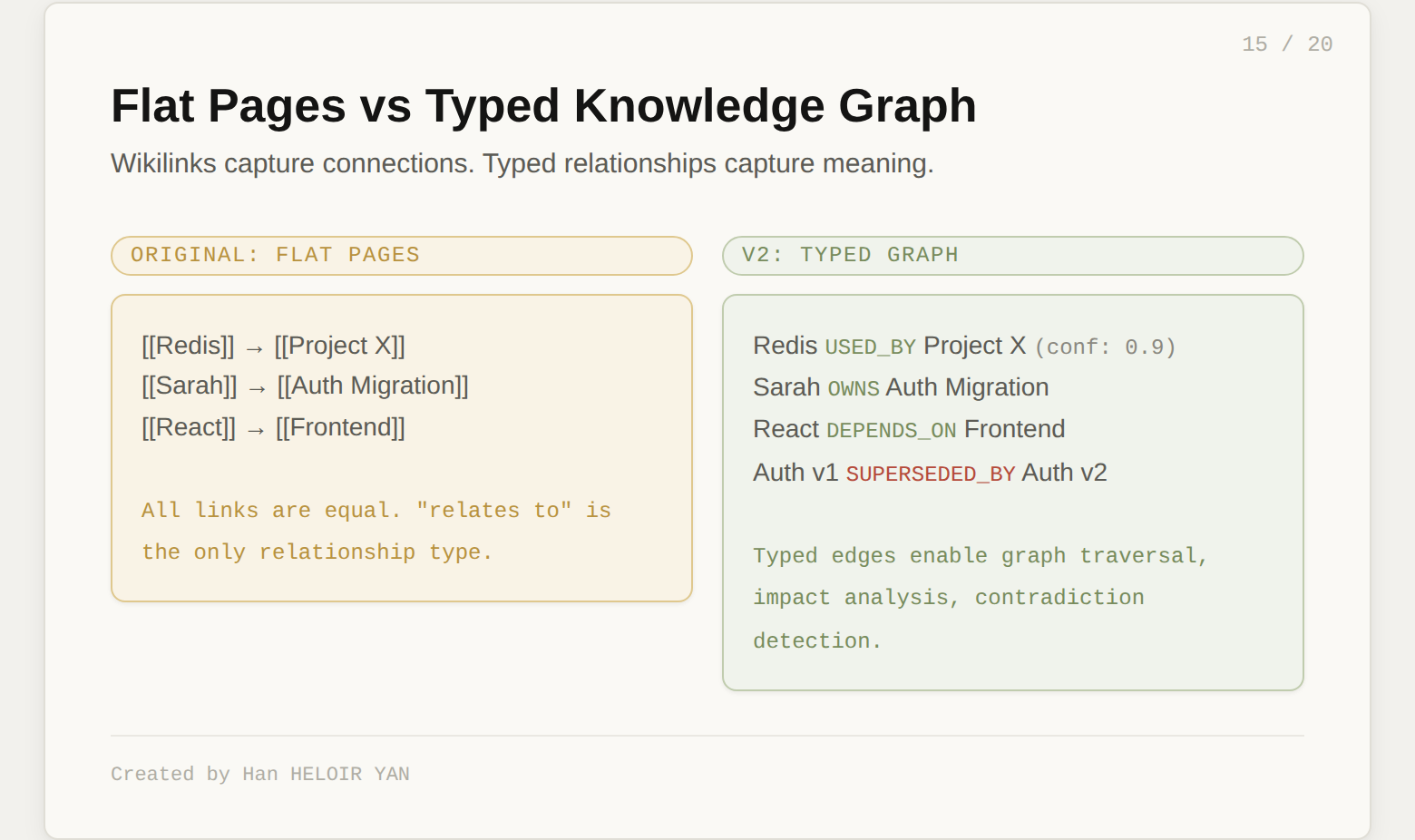
The original wiki is pages with wikilinks. That works, but leaves structure on the table. The v2 proposes a typed knowledge graph layered on top of the pages.
During ingest, the LLM does not just write prose. It extracts structured entities: people, projects, libraries, concepts, files, decisions. Each entity gets a type, attributes, and relationships to other entities. "React" is a library. "Auth migration" is a project. "Sarah" is a person who owns the auth migration and has opinions about React.
The relationships are typed. Not all connections are equal. "Uses," "depends on," "contradicts," "caused," "fixed," "supersedes" carry different semantic weight. A link that says "A relates to B" is less useful than "A caused B, confirmed by 3 sources, confidence 0.9."
This enables graph traversal for queries. When someone asks "what is the impact of upgrading Redis?", the LLM does not keyword-search. It starts at the Redis node, walks outward through "depends on" and "uses" edges, and finds everything downstream. This catches connections that keyword search misses entirely.
The graph also transforms the lint operation. Orphan detection becomes a graph connectivity check. Contradiction detection walks "contradicts" edges. Impact analysis for a superseding claim propagates through dependency edges. The wiki stops being a collection of pages and becomes a navigable knowledge topology.
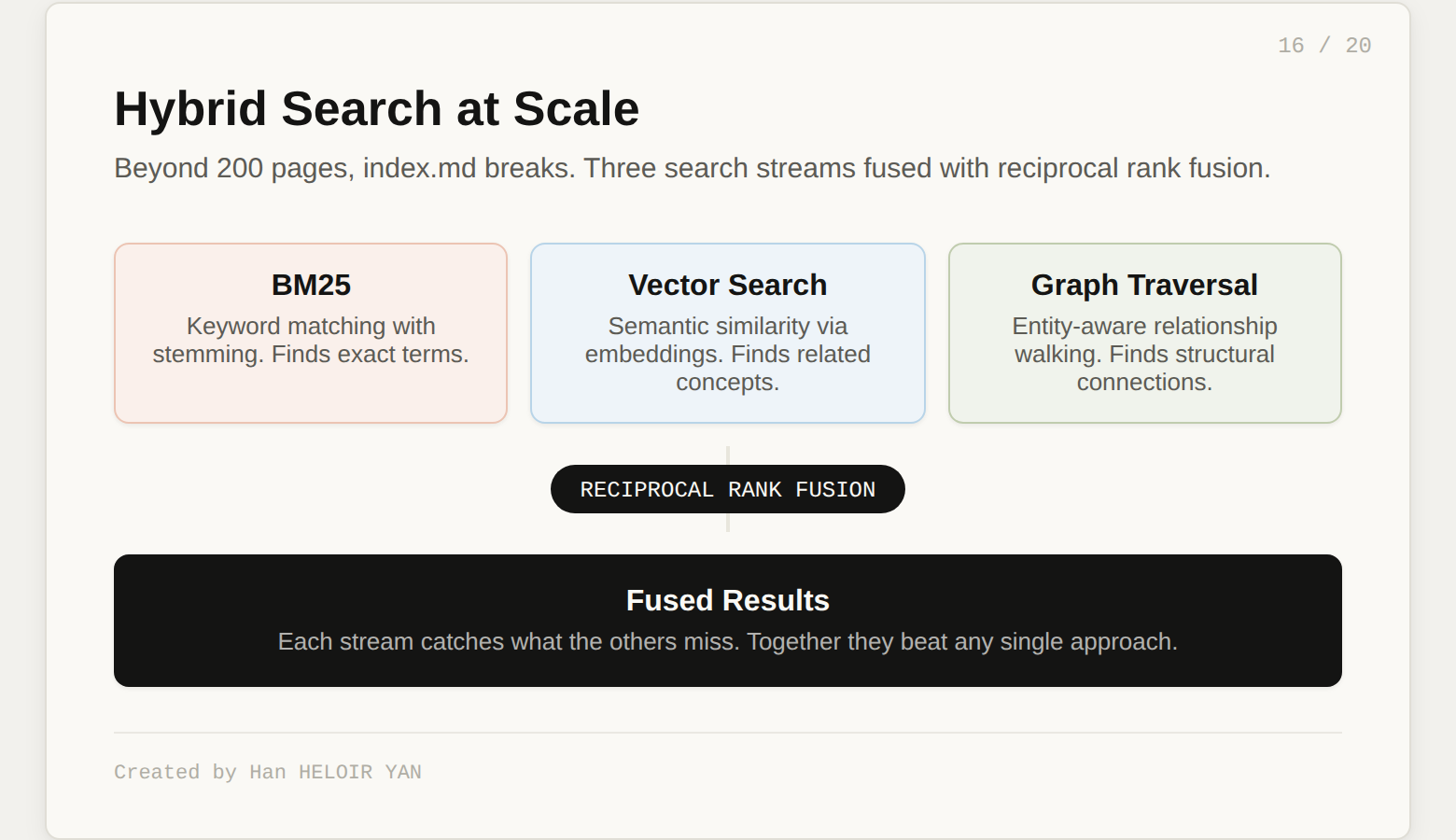
At scale (beyond 200 pages), this graph layer becomes essential. The index.md trick stops working because the index itself is too long for the LLM to read in one pass. The v2 recommends hybrid search: BM25 for keyword matching, vector search for semantic similarity, and graph traversal for structural connections. Fused with reciprocal rank fusion, these three streams together beat any single approach.
The graph does not replace the wiki pages. Pages are for reading. The graph is for navigation, discovery, and automated maintenance.
Now the title's claim.
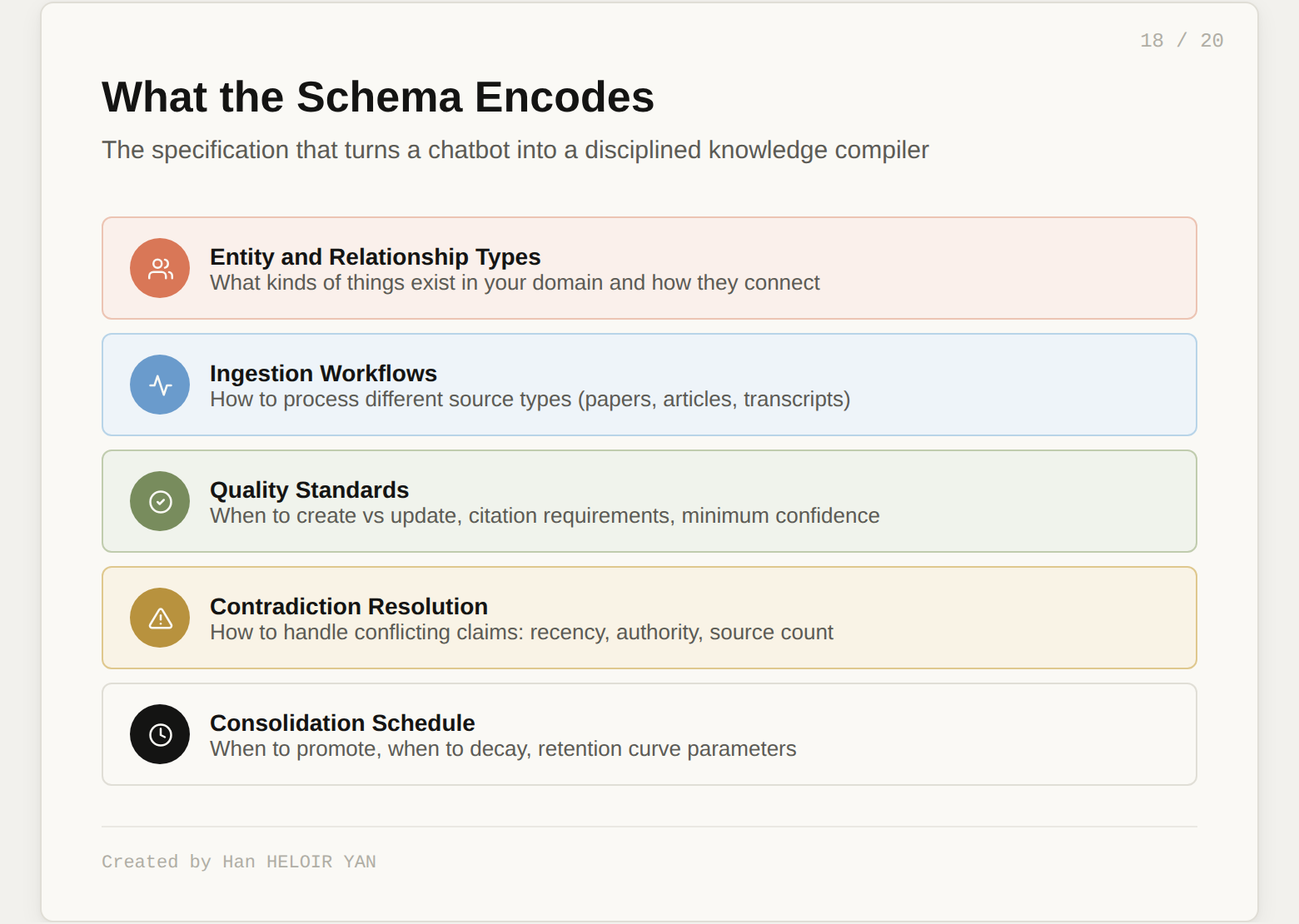
The schema (CLAUDE.md, AGENTS.md) is the most important file in the system. The v2 says this explicitly. It is what turns a generic LLM into a disciplined knowledge worker. It encodes:
What types of entities and relationships exist in your domain. How to ingest different kinds of sources. When to create a new page versus update an existing one. What quality standards to apply. How to handle contradictions. What the consolidation schedule looks like. What is private versus shared.
Without the schema, you have a chatbot writing markdown files. With the schema, you have a compiler specification that produces structured, interlinked, confidence-scored, self-healing knowledge.
The fifteen teams that forked LLM Wiki in the first week all built wiki layers. They built ingestion scripts and Obsidian integrations and search tools. Almost none of them invested in the schema. This is like building a compiler's code generator while leaving the language specification as a TODO.
The schema is also the only transferable artifact. Your wiki content is personal. Your raw sources are personal. But your schema encodes a domain model: what entities matter, how they relate, what quality means, how contradictions resolve. Share it with someone in the same field and they get a running start. They bring their own sources, and the schema produces a wiki with the same structural quality.
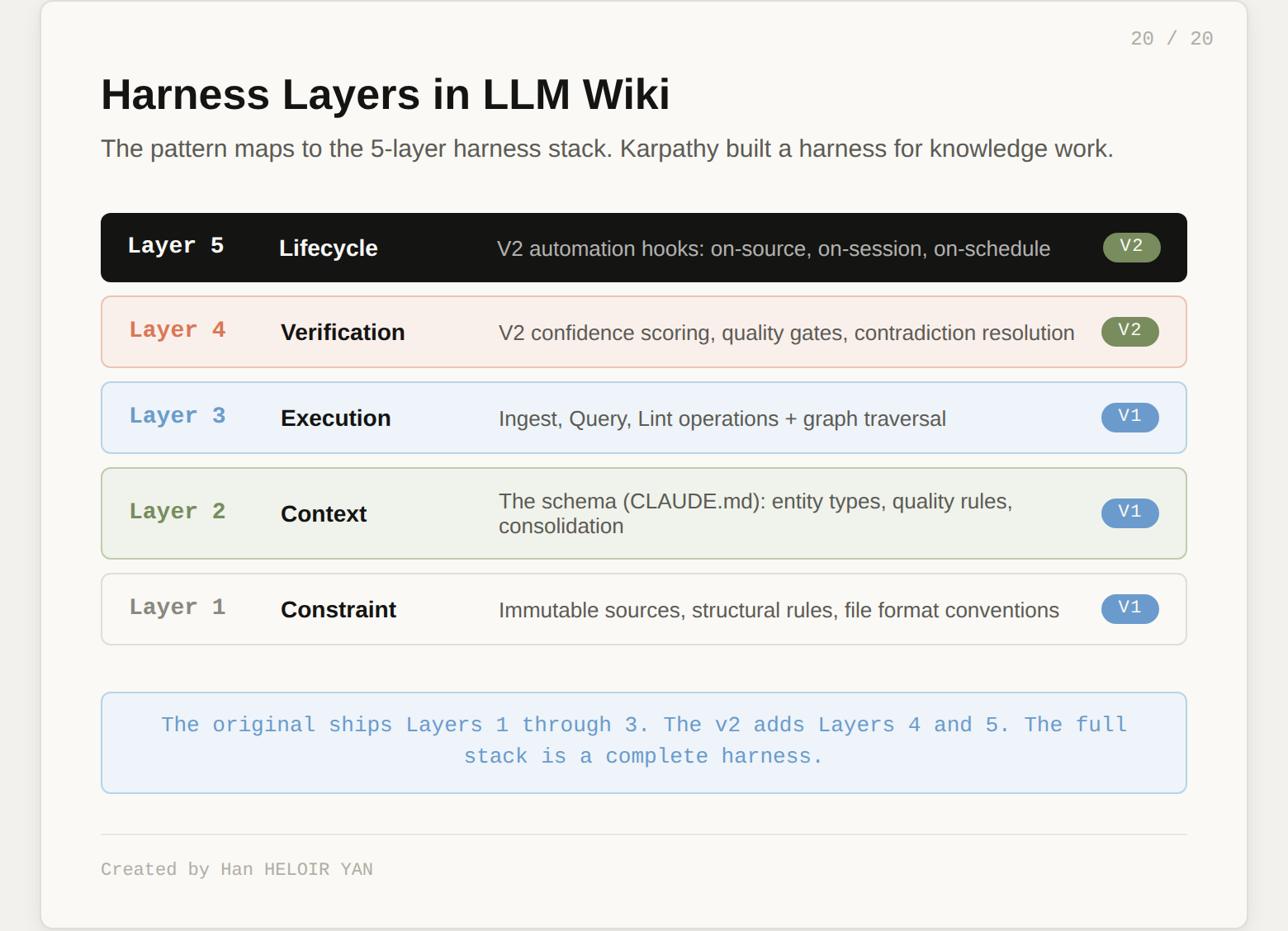
For readers following the harness engineering conversation: the schema is a Context layer governance document. The three operations (Ingest, Query, Lint) are control loops. The v2's confidence scoring is a Verification layer. The automation hooks are a Lifecycle layer. Karpathy built a harness for knowledge work. He just did not call it that.
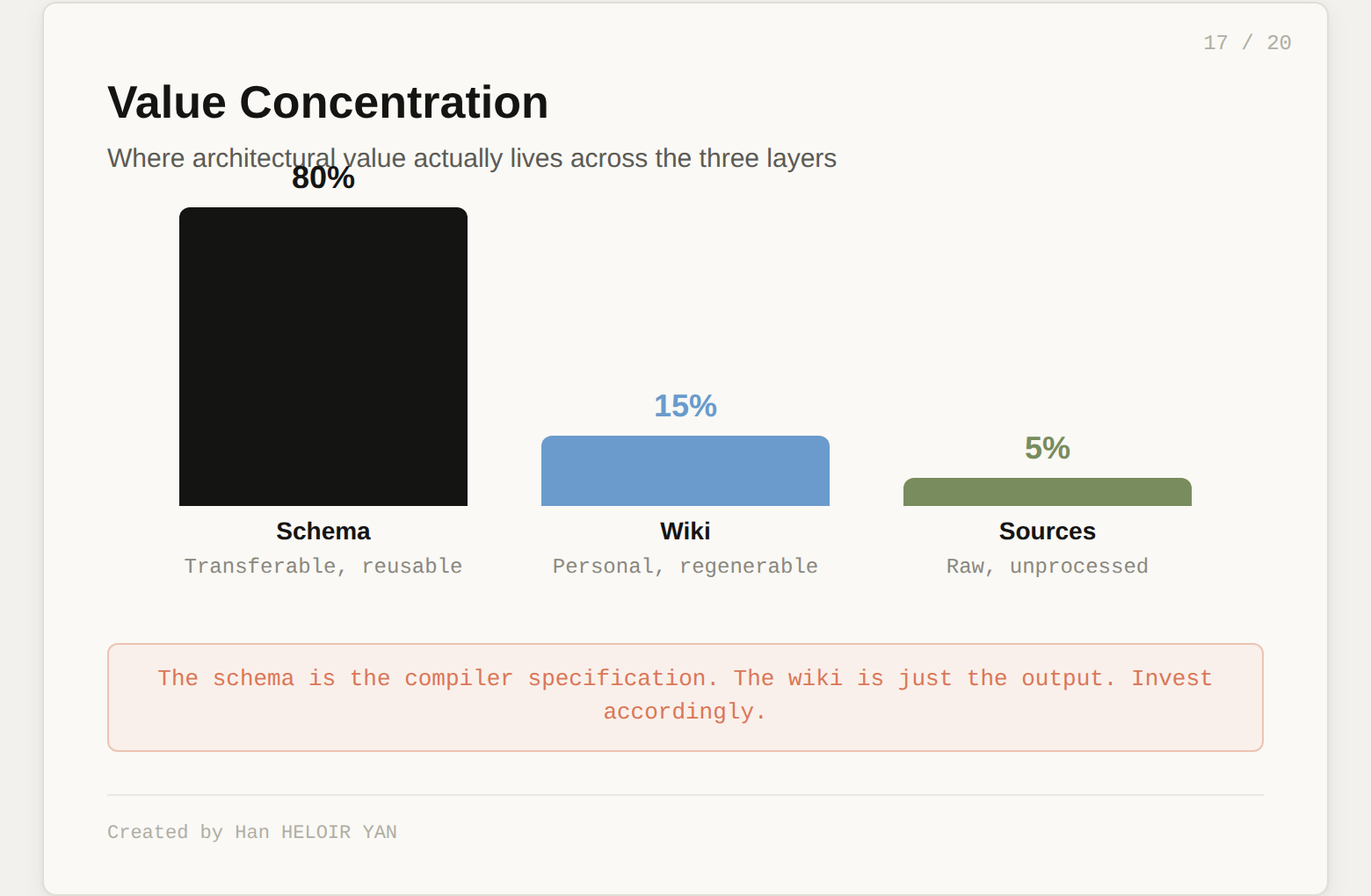
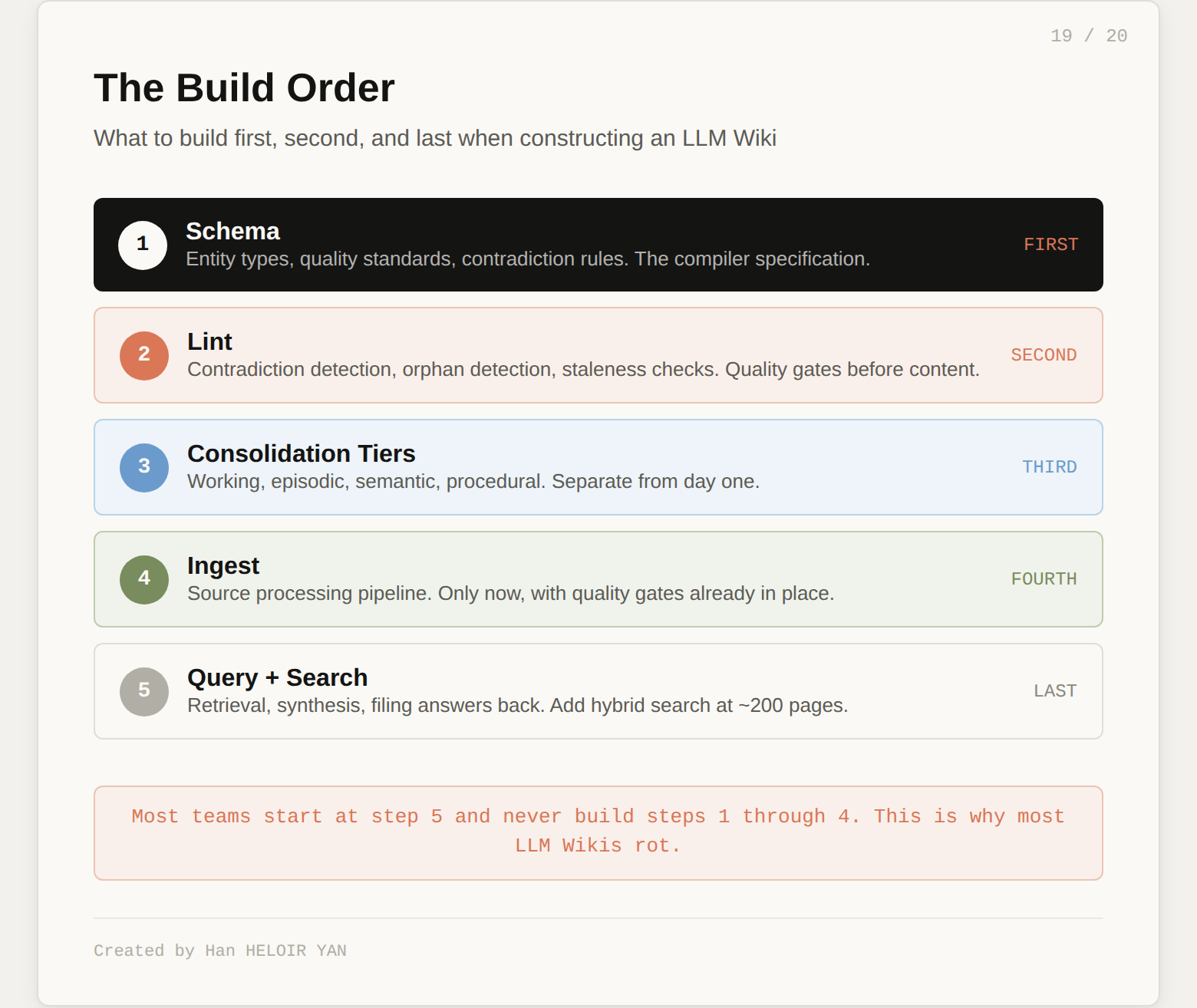
Invest in the schema first. Spend 80% of your effort on the governance document: entity types, relationship types, ingestion rules, quality standards, contradiction resolution. The wiki will generate itself. The schema is what determines whether the output is useful or noise.
Build the lint pass before the ingest pass. A compiler without quality gates produces confident garbage. Get contradiction detection, orphan detection, and staleness checks working before you start feeding sources in.
Start with consolidation tiers from day one. Do not build a flat wiki and plan to add tiers later. The flat wiki will be too messy to restructure by the time you realize you need tiers. Separate working memory (raw observations) from semantic memory (established facts) from the start.
Version control the schema separately from the wiki. The schema evolves slowly and intentionally: you change it when your understanding of the domain changes. The wiki evolves fast and automatically: every ingest modifies dozens of pages. They belong in the same repo but should be treated as different rates of change.
Beyond roughly 200 pages, invest in hybrid search. The index.md approach works at small scale. Past that threshold, you need BM25 plus vector search plus graph traversal. The v2's recommendation of reciprocal rank fusion across all three streams is the right starting point.
Track provenance from the first ingest. Every claim should know which source it came from and when it was last confirmed. You will not go back and add provenance tracking later. If it is not there from day one, you will never trust the wiki enough to rely on it for anything that matters.
Andrej Karpathy, "LLM Wiki" (April 4, 2026) The original gist that started it all. A pattern document for building personal knowledge bases where the LLM maintains the wiki and the human directs the exploration. GitHub Gist
rohitg00, "LLM Wiki v2" (April 8, 2026) The production-tested extension that adds lifecycle management: confidence scoring, supersession, forgetting curves, consolidation tiers, quality controls, and multi-agent coordination. Built on lessons from agentmemory. GitHub Gist
Eyaldavid7, "Why Your AI Agent Needs a Wiki" Head-to-head benchmark comparing LLM Wiki against standard RAG on a 50,000-line production codebase. Key finding: partial compilation performs 17% worse than full compilation, and the combined approach (wiki plus RAG) never lost a single round.
ETH Zurich agent context study Found that LLM-generated context files hurt agent performance in 5 of 8 tested settings. The failure mode: without schema governance, the LLM invents its own formats and the compiled layer degrades performance.
Scribelet, "Karpathy LLM Wiki Reaction" The sharpest critical response. Key distinction: if the LLM authors the wiki, you have built a personalized research index, not a second brain. The act of writing is load-bearing in personal knowledge management. scribelet.app
Han HELOIR YAN, "Anthropic Just Shipped Three of the Five Harness Layers" The five-layer harness stack model (Constraint, Context, Execution, Verification, Lifecycle) referenced in this article's architectural analysis. Medium
Created by Han HELOIR YAN.