What the Sequoia recap articles missed, and what you should build differently this week
Andrej Karpathy sat down with Sequoia's Stephanie Zhan three days ago. Within 48 hours, twelve articles summarized the conversation. Every one of them landed on the same three takeaways: vibe coding is dead, agentic engineering is the real discipline, and taste still matters.
All true. All useless.
Useless because none of them translate Karpathy's observations into design decisions. If you're an architect shipping agentic systems, "taste matters" tells you nothing about what to change in your next pull request. This article pulls out five signals from the talk that nobody is discussing, and turns each one into something you can actually act on.
Every lesson follows the same structure: what Karpathy said, what the market reduced it to, and what it means for system design.
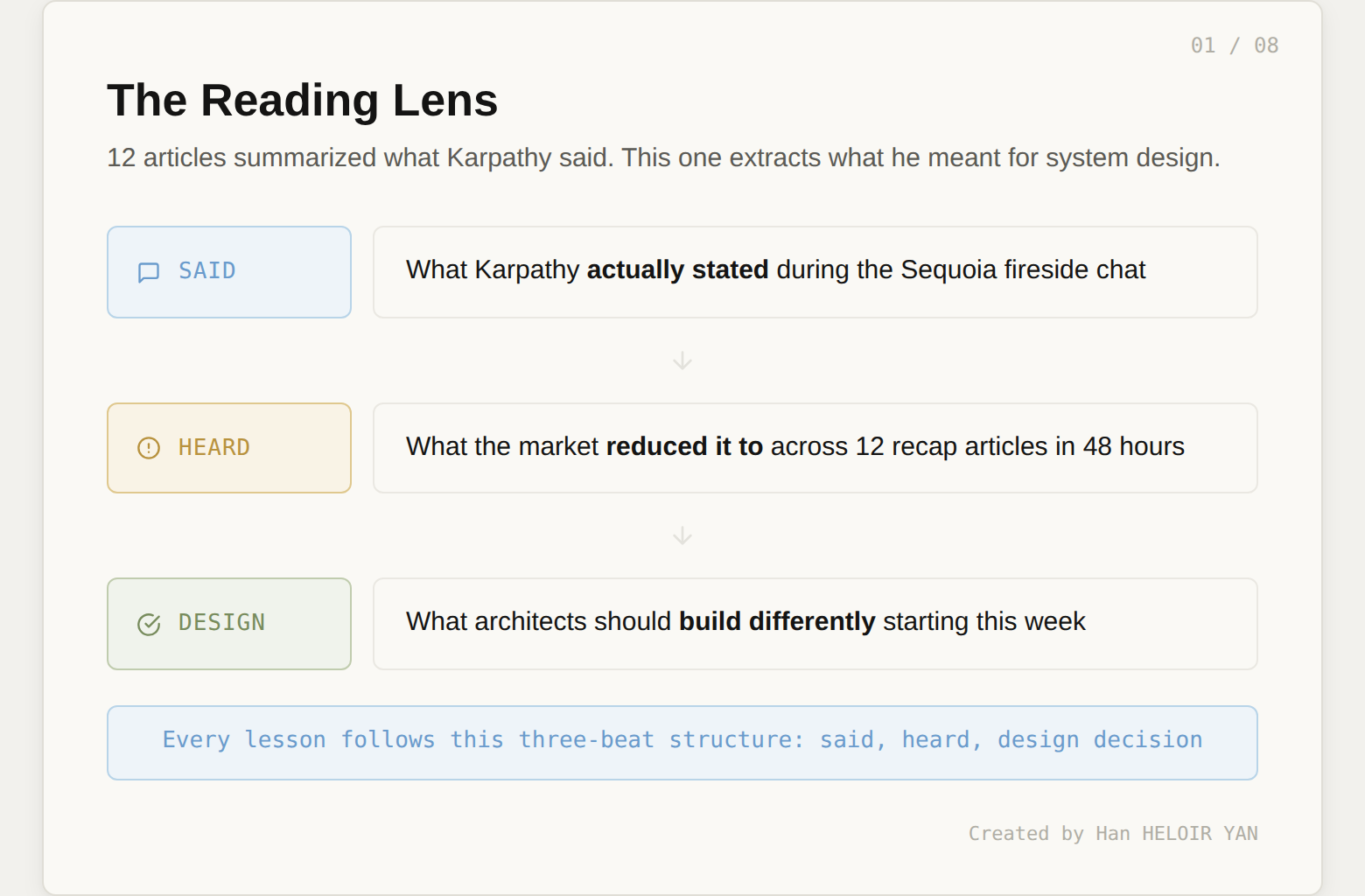
Image by Author
🦸🏻♀️ If this helps you ship better AI systems:
Frontier labs train LLMs inside reinforcement learning environments with verification rewards. The models spike in verifiable domains (code, math, puzzles) and remain rough everywhere else. Chess improved dramatically from GPT-3.5 to GPT-4 not because of general capability gains, but because someone at OpenAI added a large volume of chess data to the pre-training set. Meanwhile, state-of-the-art models still tell you to walk 50 meters to a car wash instead of driving.
His framing: "We are at the mercy of whatever the labs put into the mix."
"Models are imperfect. Stay in the loop. Treat them as tools."
This is technically correct and architecturally empty. It tells you nothing about where to invest your oversight budget.
Jaggedness is not random. It follows the RL training distribution. That distribution is knowable (not precisely, but directionally). Code generation, mathematical reasoning, and structured problem-solving sit inside heavy RL circuits. Spatial reasoning, aesthetic judgment, and cross-system identity management do not.
The design decision: before you delegate a task to an agent, classify it against a coverage map. Tasks inside strong RL circuits get high autonomy and light verification. Tasks outside them get constrained autonomy and heavy verification. The coverage map becomes a first-class artifact in your system design, right alongside your architecture diagram.

Image by Author
The practical implication: stop treating all agent outputs with the same level of scrutiny. That's expensive and teaches your team nothing about where the real risk lives. Build a coverage map for your specific domain. Update it as models change. Route your verification investment toward the gaps.
"Traditional computers can easily automate what you can specify in code. LLMs can easily automate what you can verify." He stressed the generation-verification cycle as the core loop and emphasized that the faster this loop runs, the better the outcome.
"Add output checks. Use LLM judges. Implement a review step."
Most teams interpreted verification as a quality gate you bolt onto the end of a pipeline: generate, then check. If the check fails, regenerate. This is the prompt-level interpretation, and it creates a bottleneck wherever a human needs to evaluate the output.
Verification is an infrastructure investment, not a prompt pattern. The speed of your generation-verification loop is your actual throughput ceiling. If that loop requires a human reading output, you haven't automated anything. You've added a review step to a manual process.

Image by Author
The infrastructure version looks different. Automated test harnesses run against generated code. Behavioral contracts validate that outputs satisfy structural invariants (not just "does it look right" but "does it conform to the schema, respect the constraints, and pass the regression suite"). Environment probes check whether the system state matches expectations after the agent acts.
The design decision: audit your current verification loops. For each one, ask: does this loop run without a human in it? If not, that's your throughput bottleneck. Invest in making verification automated, fast, and cheap. The generation side will improve on its own as models get better. The verification side only improves if you build it.
"Why are people still telling me what to do? I don't want to do anything. What is the thing I should copy-paste to my agent?" He described the frustration of deploying MenuGen: the code was easy, but configuring DNS, stitching together services, and navigating settings pages across Vercel, Stripe, and Google took most of the effort. All of that infrastructure was designed for humans navigating GUIs.
"Rewrite your docs for agents. Add copy-pasteable instructions."
This is the surface interpretation. Several articles already recommend "make your documentation agent-friendly." That's a start, but it stops at the outermost layer.
Agent-native infrastructure is not a documentation format. It is a system surface redesign. The question is not "can an agent read this?" The question is "can an agent reason about this without hallucinating context that doesn't exist?"

Image by Author
Human-legible systems rely on implicit state (browser sessions, GUI context, multi-step workflows where the human remembers what happened three clicks ago). Agent-legible systems make state explicit: typed APIs with structured error codes, idempotent operations, machine-parseable config schemas, and recovery hints attached to every failure mode.
The design decision: for every system surface your agents interact with, ask one question. If the agent encounters an error, can it recover without inventing context? If the answer is no, you have a legibility gap. That gap will manifest as hallucinated fixes, silent failures, and debugging sessions where the human has to reconstruct what the agent "thought" was happening.
"You're in charge of the aesthetics, the judgment, the taste, and a little bit of oversight." He gave a concrete example: in MenuGen, users sign up with Google but purchase credits through Stripe. His agent tried to match users by cross-referencing email addresses between the two systems. The bug: users can have different emails for Google and Stripe. The agent had no concept of a persistent user ID and reached for the nearest heuristic.
"Hire people with good taste. Stay in the loop. Review what agents produce."
This scales linearly with headcount and doesn't survive the person going on vacation.
Taste is the bottleneck, but you can't scale a bottleneck by hiring more of it. You scale it by encoding taste into system-level constraints that agents can't violate.

Image by Author
Karpathy's Stripe/Google email bug is a perfect case study. "Use persistent user IDs, not email" is a taste decision. If it lives in someone's head, the agent will never know about it. If it lives in a design doc, the agent might not read it. If it lives in the schema (the database rejects email as a foreign key) and in the test suite (a behavioral contract fails when the agent generates email-based identity lookup), then the constraint is enforced regardless of who writes the code or which agent generates it.
The design decision: inventory your team's unwritten taste decisions. Every "we just know not to do that" is a constraint waiting to be encoded. The more of these you push from human memory into system-level enforcement, the more autonomy you can safely grant your agents.
"You can outsource your thinking but you can't outsource your understanding." He described building LLM knowledge bases to process information and gain insight from different projections of data. He framed understanding as the fundamental bottleneck: the thing that directs agents, evaluates their output, and decides what's worth building.
"Stay curious. Keep learning. Humans still matter."
Inspiring. Completely non-operational.
Understanding is not personal development advice. It's competitive architecture. Every upstream decision in this article (the coverage map in Lesson 1, the verification loop in Lesson 2, the legibility redesign in Lesson 3, the constraint encoding in Lesson 4) requires deep domain understanding to execute well.
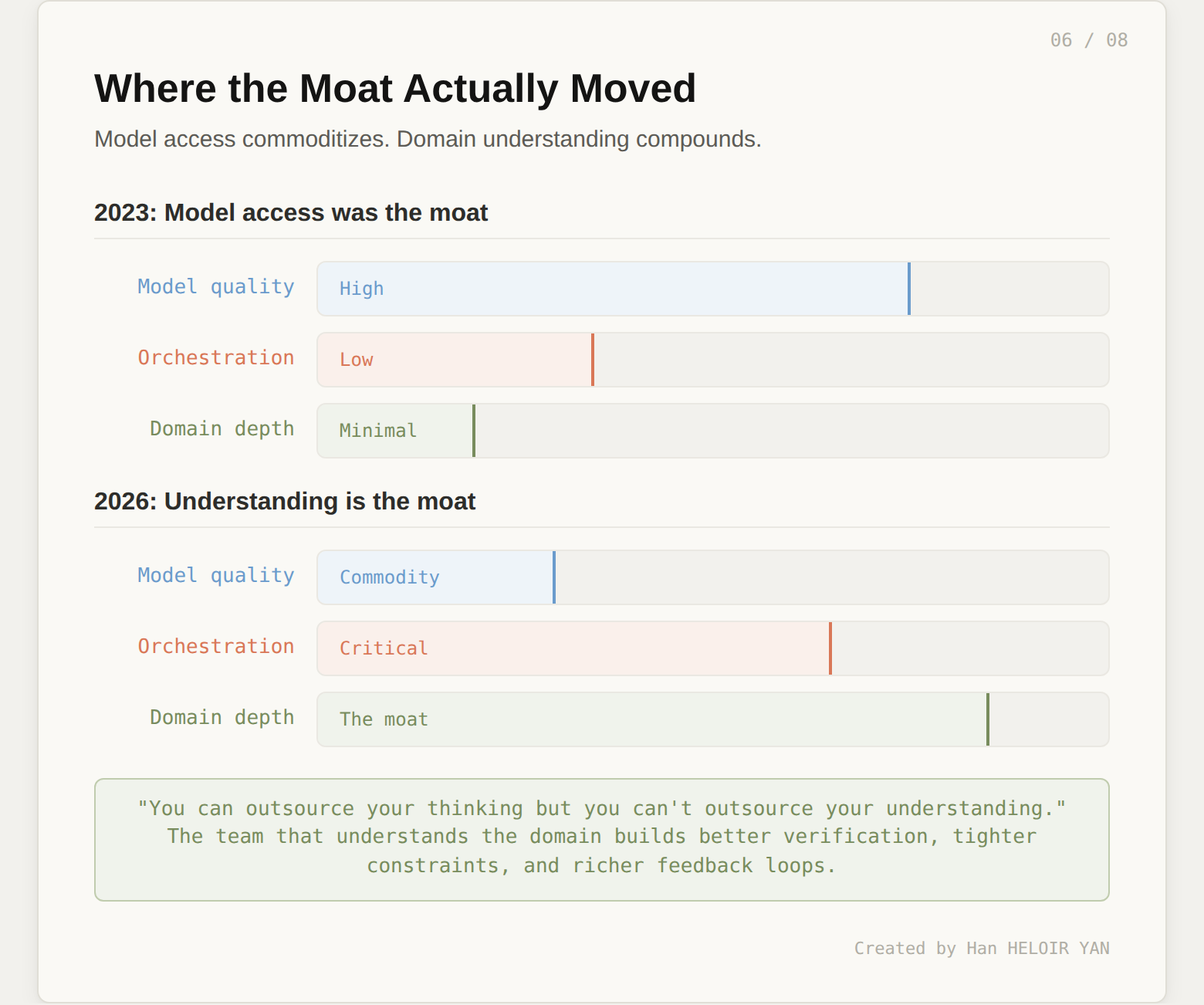
Image by Author
The team that understands its domain deeply builds better coverage maps (because they know which tasks are genuinely verifiable). They build faster verification loops (because they know what "correct" looks like in their context). They design tighter constraints (because they've internalized the failure modes). They create more legible system surfaces (because they understand what agents need to reason about).
The team that chases model access gets whatever the lab decided to put into the RL mix. When the model improves, they benefit. When it doesn't, they're stuck. That's not a moat. That's a dependency.
The design decision: measure where your team spends its learning budget. If most of it goes toward "which model is best for X" and almost none toward "what does correct look like in our domain," you're investing in the wrong layer. Model access is commoditizing. Domain understanding compounds.
These five lessons aren't independent. They form a chain where each one opens a gap that the next one closes.
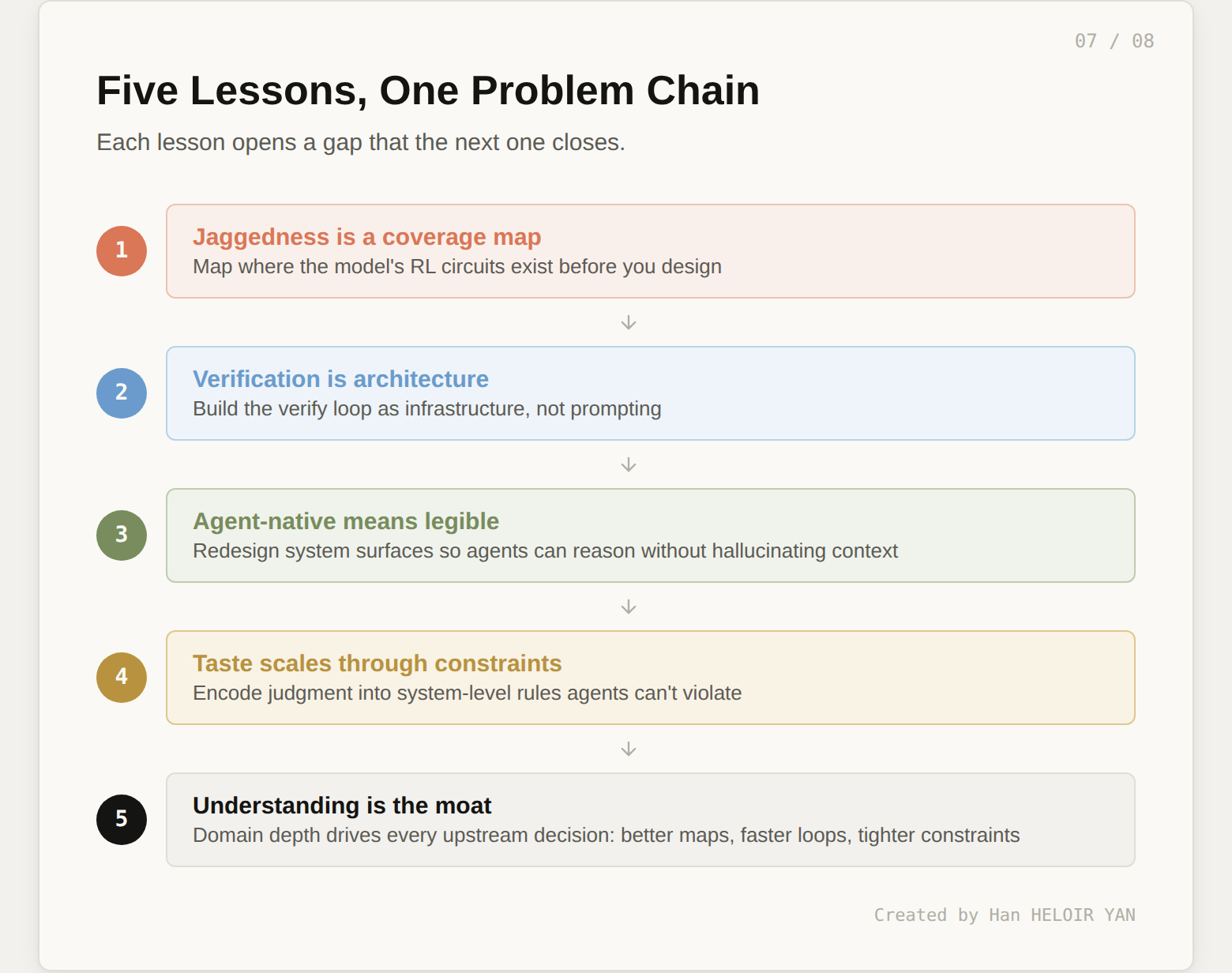
Image by Author
Recognizing jaggedness (Lesson 1) reveals the need for systematic verification (Lesson 2). Building verification infrastructure requires agent-legible system surfaces (Lesson 3). Legible systems still need encoded taste to prevent structurally valid but architecturally wrong outputs (Lesson 4). And encoding taste well requires the deep domain understanding (Lesson 5) that makes all the upstream decisions sound.
Skip any link and the chain breaks. Map jaggedness without verification, and you know where the risk is but can't catch it. Build verification without legibility, and your agents can't interact with the systems they're supposed to test. Encode constraints without understanding, and you'll constrain the wrong things.
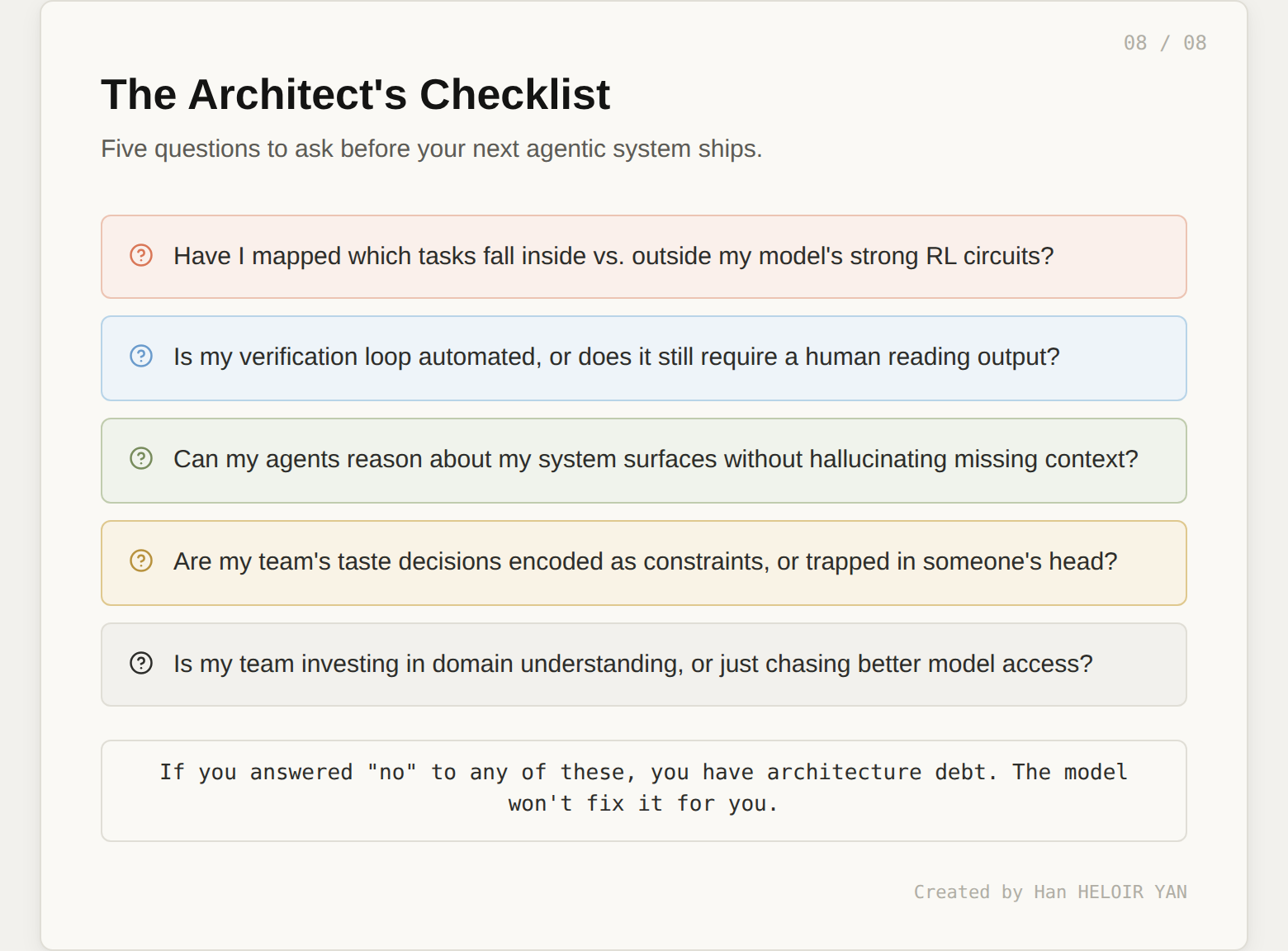
Image by Author
Pick the question where your honest answer is weakest. That's your highest-leverage investment right now. Not a new model. Not a new framework. A design decision about how your system handles the reality that agents are powerful, jagged, and incapable of understanding your domain on their own.
Karpathy gave us the diagnosis. The treatment is architecture.