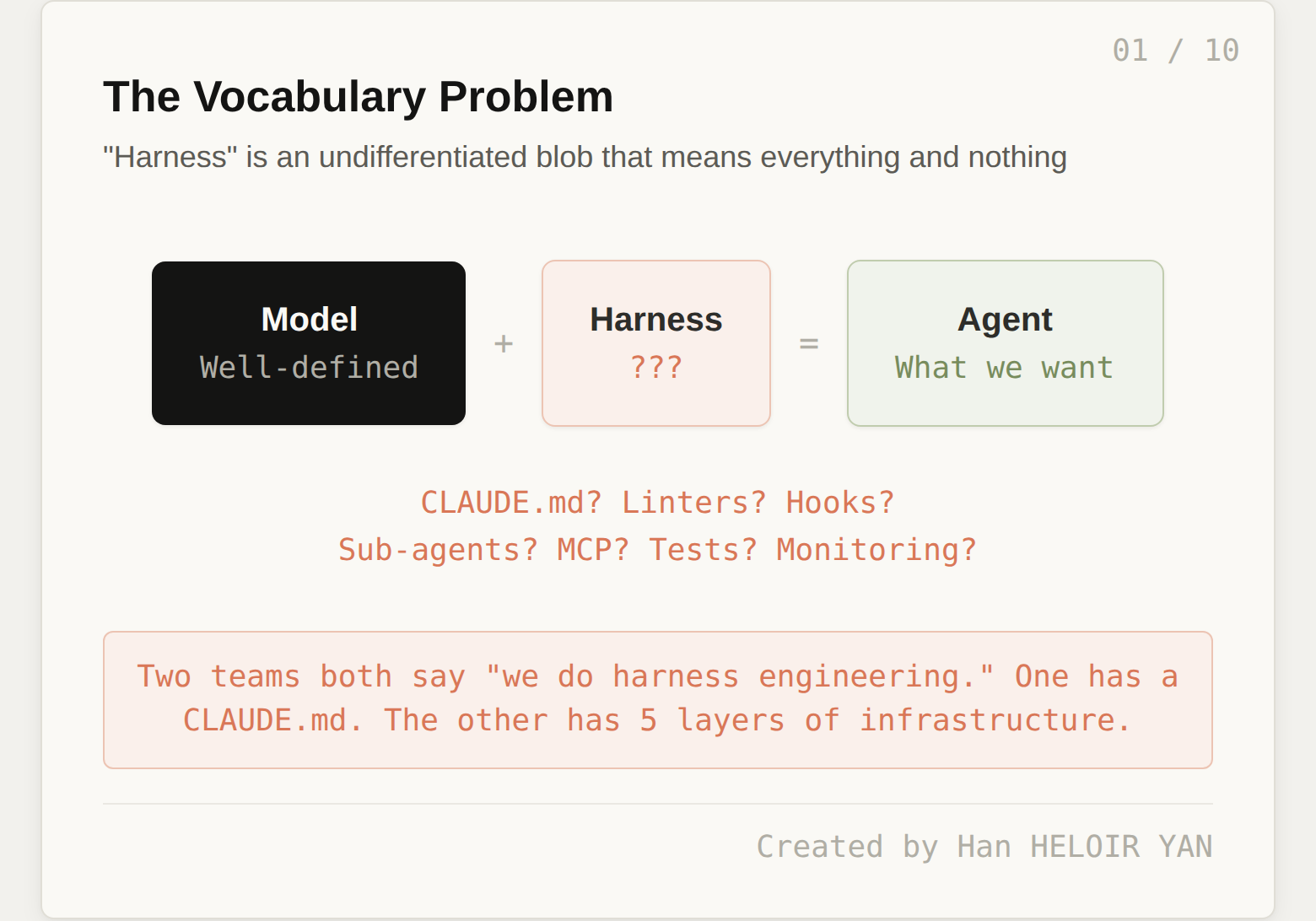
Everyone agrees on the formula. Agent = Model + Harness. Mitchell Hashimoto named the practice. OpenAI demonstrated it at scale. LangChain formalized the components. Anthropic published the patterns for long-running sessions, then shipped a managed platform that treats the harness as infrastructure. The term "harness engineering" went from obscure to unavoidable in under two months.
But here is the problem: "harness" means completely different things to different teams. One team says they do harness engineering because they have a CLAUDE.md file with 30 lines of project conventions. Another team says the same thing, but they have deterministic architectural constraints, context pipelines with progressive disclosure, sub-agent orchestration with context firewalls, automated verification hooks that run silently on success and loudly on failure, and full lifecycle management with cost tracking and crash recovery.
Both teams claim to be doing harness engineering. They are not doing the same thing.
The word "harness" today is where "networking" was before the OSI model. Everyone agreed networks mattered, but nobody could have a precise conversation about which part was broken. Was it the physical cable? The routing protocol? The application logic? The term "networking" was too broad to be useful for diagnosis, comparison, or systematic improvement.
"Harness" is suffering the same fate. When everything is harness, nothing is.
This article proposes a 5-layer model for decomposing the harness. Each layer has distinct responsibilities, different tooling, a different rate of change, and a different organizational owner. The goal: give the harness engineering community a shared vocabulary precise enough to diagnose what's missing, compare approaches, and invest where it matters most.
🦸🏻♀️ If this helps you ship better AI systems:
👏 Clap 50 times (yes, you can!) — Medium's algorithm favors this, increasing visibility to others who then discover the article.
🔔 Follow me on Medium, LinkedIn and subscribe to get my latest article.
Two teams both report "doing harness engineering." Team A has a CLAUDE.md, runs type checks before merging, and occasionally uses a sub-agent for research tasks. Team B has custom ArchUnit rules enforcing module boundaries, a curated knowledge base of machine-readable architectural constraint documents, dynamic tool scoping that reduces available MCP tools by 80% depending on the task phase, silent-on-success verification hooks that re-engage the agent on failure, loop detection middleware, checkpoint-resume with state persistence, and cost-per-task dashboards.
Team A is at maybe 15% of what a production harness requires. Team B is at 80%. But they use the same word to describe what they are doing.
This matters because without a shared vocabulary, teams cannot diagnose what is missing. They cannot compare their approach to OpenAI's or Anthropic's or LangChain's and say "we are strong on verification but have no constraint layer." They cannot make investment decisions because they cannot see the gaps.
The existing 6-component model (context engineering, tool orchestration, state management, verification, human-in-the-loop, lifecycle management) is a good start. But it presents six components on a flat list with no relationships, no dependencies, and no sense of which layers are foundational and which are optional. It does not tell you what order to build in or which gaps hurt most.
We need a stack, not a list. Layers with clear interfaces, dependencies, and an order of operations.

Here is the proposed decomposition. Each layer has a single responsibility, concrete examples from the teams building production harnesses today, a characteristic rate of change, and a natural organizational owner.
The Constraint Layer enforces structural rules about what shapes the code is allowed to take. It is fully deterministic. No LLM is involved. It answers one question: what are the boundaries the agent is not allowed to cross?
OpenAI invested more heavily in this layer than any other part of their harness. Their Codex team required the agent to parse data shapes at module boundaries, enforced fixed dependency directions between business domain layers, and ran custom linters and structural tests on every output. Code that violated structural rules was rejected before any semantic evaluation happened.
Concrete examples of Constraint Layer components include custom linter rules (ESLint, Biome, Clippy rules that encode project-specific conventions), structural test frameworks like ArchUnit that enforce dependency directions and module boundaries, naming convention enforcement, file structure validation (certain files must exist in certain locations), and API contract validation (OpenAPI schemas that constrain what endpoints the agent can create).
This is the layer most teams skip entirely. It is also the layer with the highest leverage for teams that already have basic context and verification in place. Deterministic constraints are cheap to run, produce zero false positives when well-designed, and prevent entire categories of failures without burning a single token.
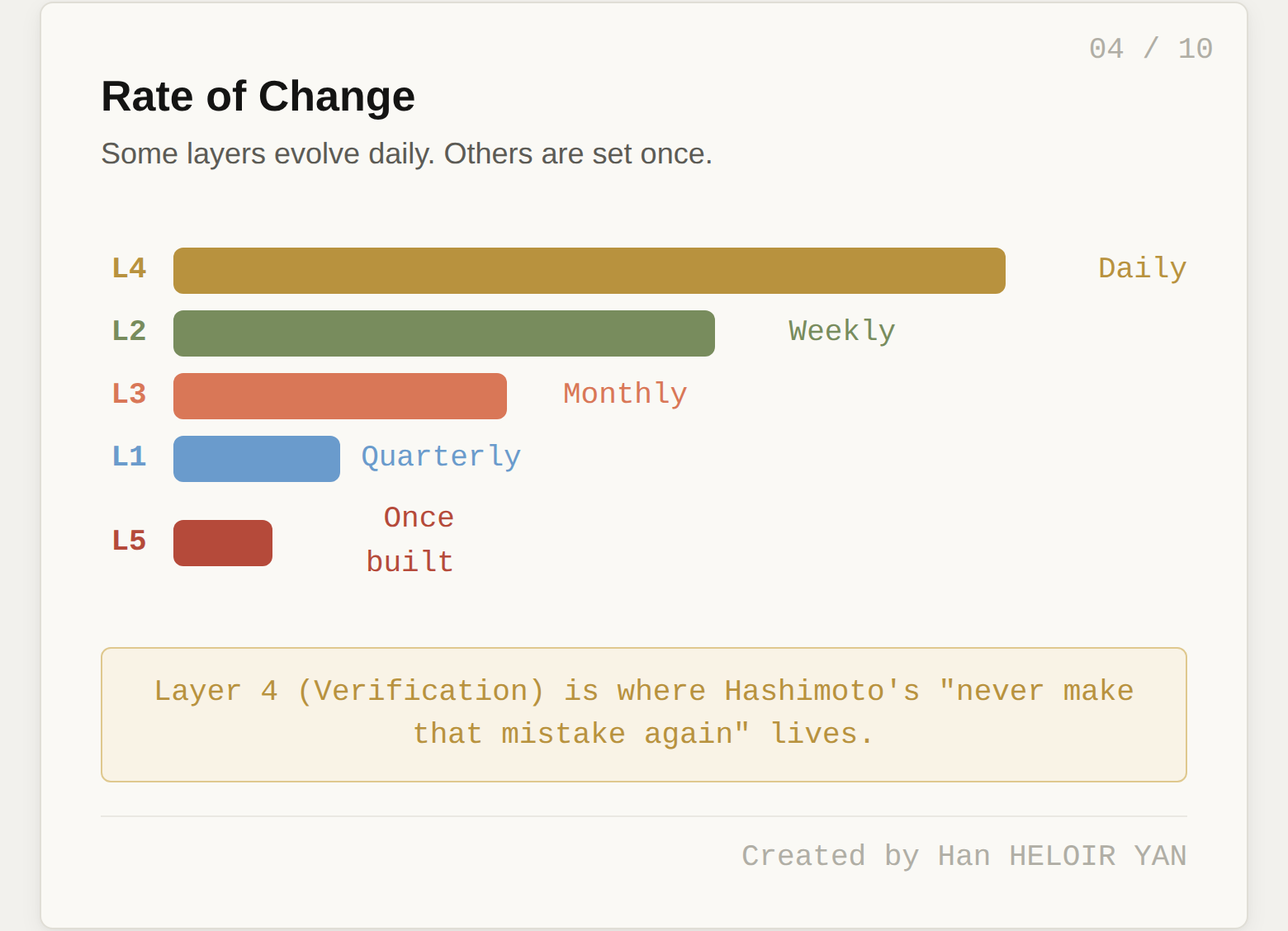
Rate of change: Slow. Constraints evolve with major architecture decisions, not with individual tasks.
Owner: Architecture team or senior engineers who own the system's structural integrity.
The Context Layer controls what the model sees at each step of execution. It answers: what does the agent know right now, and how was that knowledge selected?
This is the layer the industry understands best. It includes AGENTS.md and CLAUDE.md files injected into the system prompt, skills for progressive disclosure (the agent only loads specific instructions when it needs them), the progress file pattern Anthropic documented (a structured scratchpad recording completed steps, blockers, and next actions), and repository-local knowledge artifacts like machine-readable architectural decision records.
The ETH Zurich study of 138 agentfiles revealed important nuances at this layer. LLM-generated agentfiles actually hurt performance while costing 20%+ more in tokens. Codebase overviews and directory listings did not help because agents discover repository structure on their own just fine. The human-written agentfiles that helped were concise, universally applicable, and updated frequently. HumanLayer's CLAUDE.md is under 60 lines. More is not better at this layer. Curated and relevant beats comprehensive and stale.
Rate of change: Medium. The structure of context delivery is stable, but the content updates as the codebase evolves.
Owner: The development team working in the codebase daily.
The Execution Layer manages what the agent can do and how it does it. Tool orchestration, MCP server configuration, sub-agent dispatch, sandboxing, and permission models all live here. It answers: what actions are available, and what guardrails surround each action?
The counterintuitive insight at this layer is that more tools produce worse results. Vercel discovered this when building their v0 coding agent: removing 80% of available tools measurably improved task completion. Every tool description consumes tokens in the system prompt, and too many tools push the agent into what HumanLayer calls "the dumb zone," where the model spends more tokens reasoning about which tool to use than actually doing the work.
Production execution layers use dynamic tool scoping: a planning step does not need file system write access, and a code execution step does not need web search. HumanLayer replaced the full Linear MCP server (dozens of tools) with a custom CLI exposing six operations, saving thousands of tokens from tool definitions. Boris Cherny's "context firewall" pattern uses sub-agents to encapsulate heavy tasks so none of the intermediate tool calls pollute the parent agent's context window.
Rate of change: Medium. New tools are added as capabilities expand, but the orchestration logic is reusable.
Owner: Platform engineering, the team responsible for developer tooling and infrastructure.
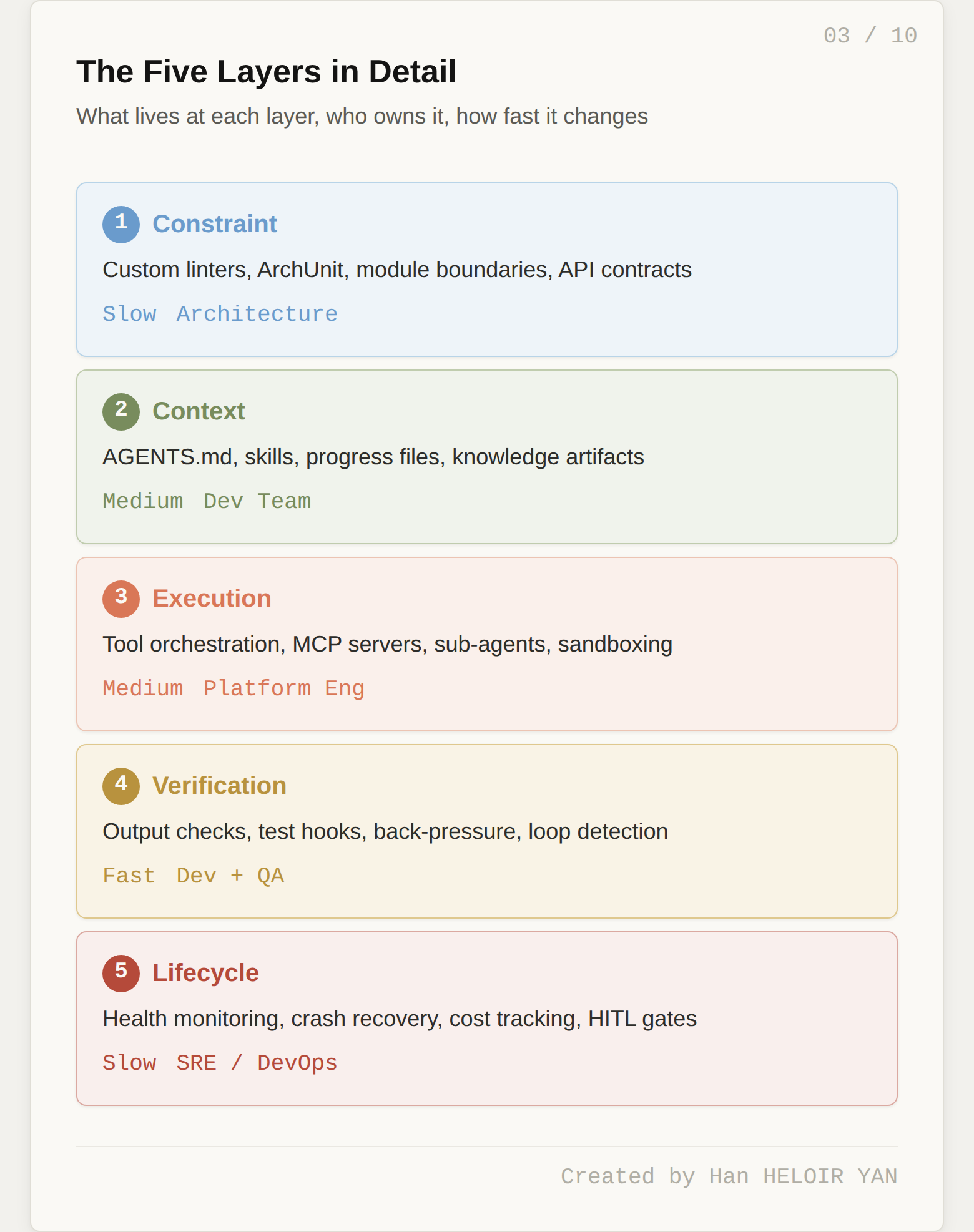
The Verification Layer checks whether the agent's output is correct and safe before it reaches the real world. It answers: should this output be accepted, retried, or escalated?
This is the single highest-impact pattern in harness engineering. Teams consistently report the largest reliability improvements from adding structured verification. Boris Cherny (creator of Claude Code) observed that giving Claude effective verification methods typically improves final output quality by 2 to 3x. LangChain improved their coding agent from 52.8% to 66.5% on Terminal Bench 2.0 by only tweaking the harness, and verification changes were a major part of that improvement.
The critical design principle at this layer is context efficiency. HumanLayer learned this the hard way: early on, they ran the full test suite after every change, and 4,000 lines of passing tests flooded the context window. The agent lost track of the actual task. The fix: swallow passing output, only surface errors. Success is silent. Failure is loud. Their pre-stop hook runs biome formatter and TypeScript type checks. On success, nothing enters the context. On failure, only errors are surfaced, and exit code 2 tells the harness to re-engage the agent.
This is also where Hashimoto's core principle lives: "Anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again." Every new verification rule is a lesson learned, encoded permanently.
Rate of change: Fast. This is the fastest-evolving layer, growing with every failure the team encounters.
Owner: Shared between development and QA. Developers write the verification rules. QA defines the acceptance criteria.
The Lifecycle Layer manages the agent as a running process: startup, health monitoring, graceful shutdown, crash recovery, cost tracking, and human-in-the-loop escalation. It answers: is the agent alive, healthy, making progress, and within budget?
Without this layer, agents are expensive, unmonitored processes that fail silently. The failure modes are specific and costly. Infinite loops where the agent retries the same error indefinitely can burn thousands of dollars overnight. State corruption after a crash and recovery leaves the agent operating on stale assumptions. Context rot over long-running sessions causes the agent to gradually lose track of its original goal.
LangChain's LoopDetectionMiddleware addresses doom loops by tracking per-file edit counts and injecting "consider reconsidering your approach" after N edits to the same file. Anthropic's two-agent pattern (initializer + coding agent) addresses context rot by constructing fresh context at the start of each session rather than replaying the full conversation history. Token budget management and cost-per-task tracking prevent runaway spending.
Human-in-the-loop controls also live at this layer. Production harnesses need approval gates for high-risk operations: deleting data, sending external communications, modifying infrastructure. The calibration challenge is real: too many approval gates and the agent is slower than doing the task manually, too few and you are one hallucinated API call from a production incident. The best practice is to start conservative and relax gates as confidence builds.
Anthropic's Claude Managed Agents (April 2026) elevates this layer to a platform primitive. Their engineering team decoupled the "brain" (the harness loop calling Claude) from the "hands" (sandboxes where code runs) and the "session" (a durable event log). Each component can fail or be replaced independently. When a harness crashes, a new one reboots with wake(sessionId), fetches the event log, and resumes from the last event. When a container dies, the harness catches the failure as a tool-call error and provisions a new one. No pet containers to nurse back to health. The result: p50 time-to-first-token dropped roughly 60%, and p95 dropped over 90%. That kind of improvement comes from treating agents as infrastructure, not application code.
Rate of change: Slow once built. This is infrastructure.
Owner: SRE and DevOps, the teams responsible for production reliability and operational visibility.
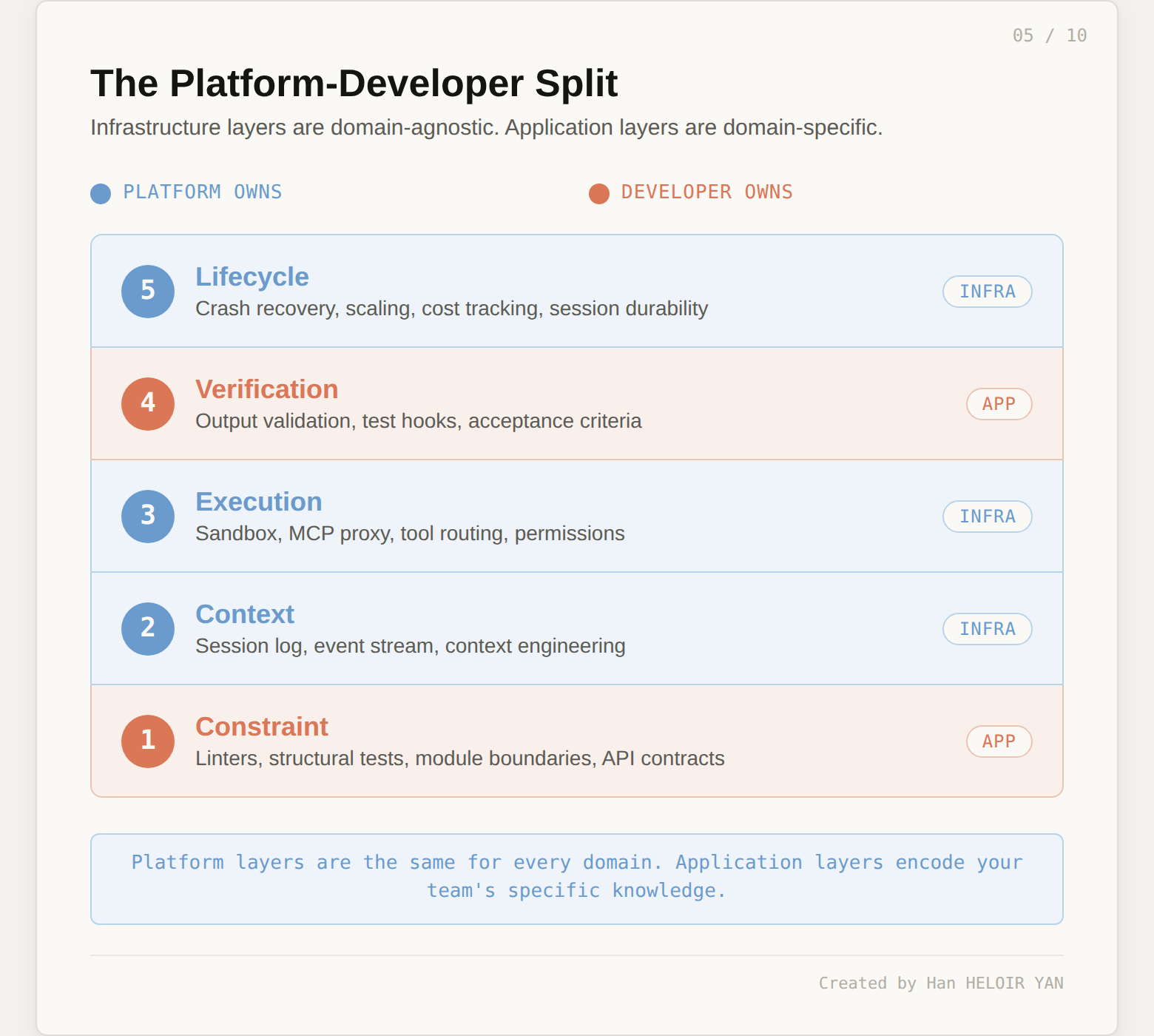
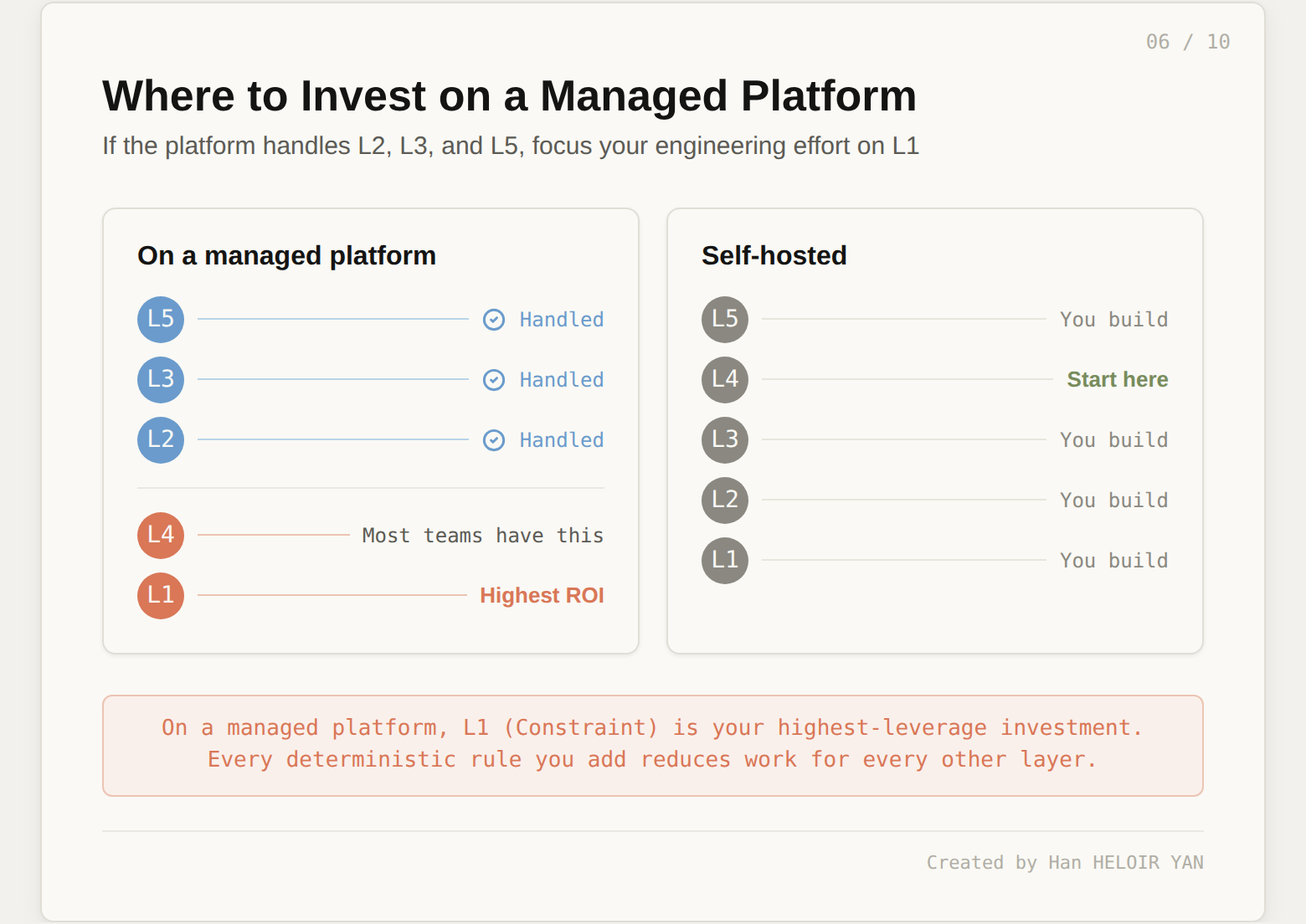
Now that we have a layer model, we can do something we could not do before: map existing tools and approaches to specific layers and see the gaps. But the more useful insight is not which layers are missing. It is who is expected to build them.
A pattern is emerging across platform providers. Anthropic's Claude Managed Agents (April 2026) virtualizes three components of the agent stack: the session (a durable event log living outside Claude's context window), the sandbox (disposable containers where code runs), and the harness loop itself (the brain that calls Claude and routes tool calls). Their engineering team explicitly frames this as a "meta-harness": infrastructure that is unopinionated about the specific harness that Claude will need in the future.
Map those three components to the five-layer model and a clean split appears.
The platform provides Layers 2, 3, and 5. Session durability and context engineering live in L2. Sandbox management, MCP proxy routing, and tool orchestration live in L3. Crash recovery, checkpoint-resume, scaling, and cost tracking live in L5. These are the layers that require infrastructure investment: containers, event logs, security vaults, scaling logic. The kind of work where Anthropic's decoupling of brain from hands dropped p50 time-to-first-token by roughly 60% and p95 by over 90%. That optimization is infrastructure work, not application work.
The developer provides Layers 1 and 4. When Anthropic says developers "define agent tasks, tools, and guardrails," they are describing L1 (Constraint). When they leave output validation and evaluation logic to the application, they are describing L4 (Verification). These are the layers that encode domain-specific knowledge: your architectural boundaries, your acceptance criteria, your definition of "correct." No platform can provide these because they are different for every team, every codebase, every domain.
This split is not accidental. It reflects a fundamental property of the five layers. L2, L3, and L5 are infrastructure concerns: they are the same regardless of whether your agent writes code, processes claims, or analyzes documents. L1 and L4 are application concerns: they are different for every team.
The "CLAUDE.md plus some tests" pattern, which is the industry default for teams claiming to do harness engineering, covers partial L2 and partial L4. Two layers, partially. On a managed platform, that means you are using half the infrastructure the platform provides and investing in only one of the two layers that are actually your responsibility. The missing layer is almost always L1. Teams write verification tests (L4) because testing is a known practice. Teams rarely write deterministic structural constraints (L1) because the practice has no established home in most engineering workflows.
OpenAI's Codex leap came specifically from heavy investment in L1. Their custom linters, structural tests, and architectural boundary enforcement are all Constraint Layer components. These deterministic checks catch entire categories of failures without LLM involvement, making every subsequent layer more effective. When your code structure is guaranteed to be valid before semantic checks even begin, the verification layer has less work to do.
The highest marginal return for teams on a managed platform is investing in L1. If the platform already handles your session durability, sandbox management, and crash recovery, your next dollar of engineering effort should go to deterministic constraints: custom linters, structural tests, module boundary enforcement, API contract validation. These are cheap to run, produce zero false positives when well-designed, and prevent entire categories of failures without burning a single token. Every constraint you add at L1 reduces the work L4 has to do downstream.
For teams not on a managed platform, the picture is different. You are responsible for all five layers. The priority then follows the original guidance: invest in whichever layer you are currently missing, starting with L4 (verification) because it delivers the fastest reliability improvement per engineering hour, then expanding to L1 and L5 as your agent workloads grow longer and more autonomous.
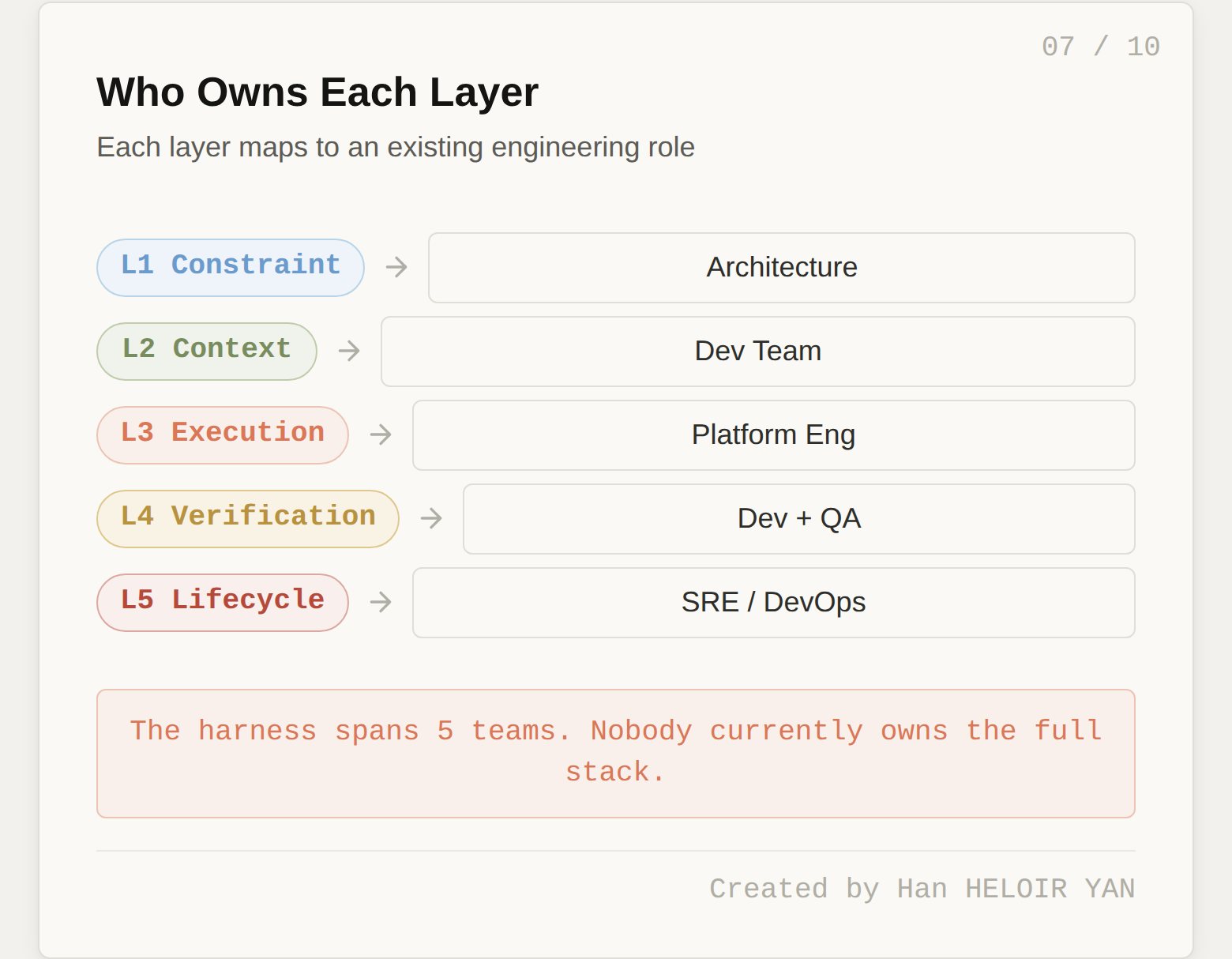
Each layer of the harness stack maps naturally to a different traditional engineering role. This is both an insight and a warning.
Layer 1 (Constraint) maps to architecture. The people who decide module boundaries, dependency directions, and API contracts are the same people who should encode those decisions as deterministic rules.
Layer 2 (Context) maps to the development team. The people writing code in the codebase daily are the ones who know which conventions matter, which patterns to follow, and what context the agent needs to do useful work.
Layer 3 (Execution) maps to platform engineering. Tool integration, sandboxing, MCP server management, and sub-agent infrastructure are platform concerns, the same team that manages CI/CD pipelines and developer tooling.
Layer 4 (Verification) is shared between development and QA. Developers write the verification hooks. QA defines acceptance criteria and evaluation metrics. The feedback loop between failure and new verification rules is a collaborative process.
Layer 5 (Lifecycle) maps to SRE and DevOps. Health monitoring, crash recovery, cost tracking, and operational dashboards are the same concerns these teams handle for every other production service.
Here is the warning: in most organizations, nobody owns "the harness" end-to-end. It is a cross-cutting concern, like security or observability, that spans five different teams. And cross-cutting concerns that nobody owns tend to be cross-cutting concerns that nobody builds.
The OpenAI Codex experiment worked partly because a single team owned all five layers. They had the architectural authority, the codebase knowledge, the platform skills, the verification discipline, and the operational maturity in one group. Most organizations cannot replicate that structure.
The practical solution is not a "harness engineering team" (yet another silo). It is a harness engineering practice: a shared set of standards, a common vocabulary (which this layer model provides), and clear ownership at each layer. Layer 1 lives in the architecture review. Layer 2 lives in the team's sprint process. Layer 3 lives in the platform roadmap. Layer 4 lives in the definition of done. Layer 5 lives in the operational runbook. No new team required. Just explicit ownership at each layer.

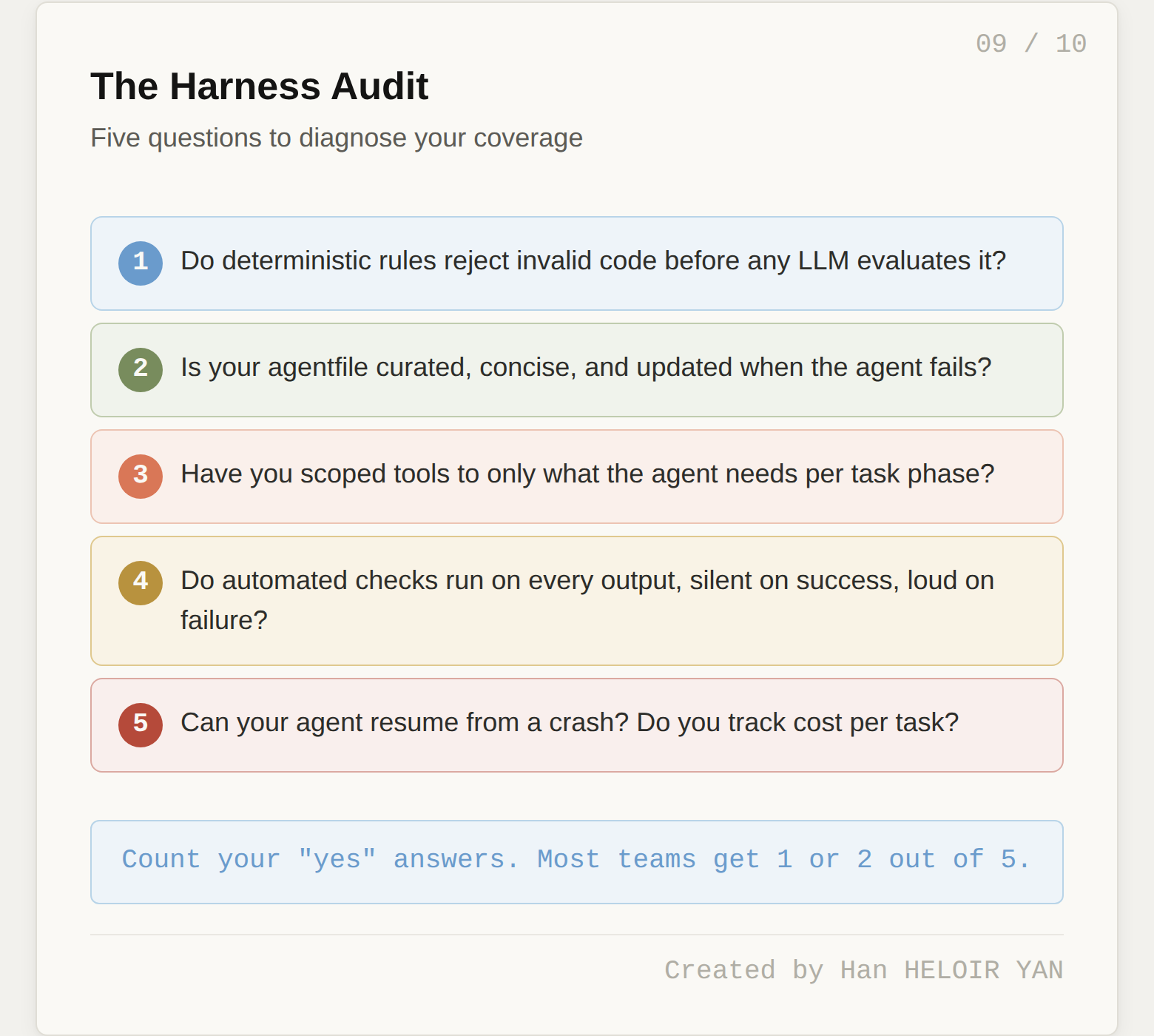
Start by auditing your current harness against the five layers. For each layer, ask: do we have anything here? Is it actively maintained? Is it producing measurable improvement?
Most teams will discover they are strong on Layer 2 (some form of agentfile exists) and have partial Layer 4 (tests run, but not in a context-efficient way). Layers 1, 3, and 5 are typically empty or ad hoc.
Once you see the gaps, prioritize based on where failures are actually occurring. If your agent produces structurally invalid code (wrong file locations, broken module boundaries, violated dependency directions), you need Layer 1. If your agent picks the wrong tools or burns tokens on irrelevant tool descriptions, you need Layer 3. If your agent crashes and restarts from scratch, or runs up unexpected bills overnight, you need Layer 5.
A useful heuristic: invest in the layer directly below your most frequent failure mode. Structural failures point to Layer 1. Context drift points to Layer 2. Tool confusion points to Layer 3. Incorrect outputs point to Layer 4. Silent failures and runaway costs point to Layer 5.
Harness engineering is an investment with a payback period measured in weeks to months. There are situations where it is premature or counterproductive.
During prototyping. You are still exploring whether the agent approach works at all. Building a 5-layer harness for a prototype you might discard next week is premature optimization. HumanLayer's principle applies: bias toward shipping, and invest in harness only in response to real failures, not preemptive anxiety.
For single-shot tasks. If your agent does one thing in one step (summarize a document, translate a file), a full harness is overhead. The compounding failure math (95% per step dropping to 36% over 20 steps) only kicks in with multi-step chains. No chain, no compounding, no urgency.
Against legacy codebases that resist harnessing. Birgitta Böckeler's sharpest insight: retrofitting a harness onto a pre-AI codebase is like running a static analyzer on a project that never had one. You drown in alerts. Not every codebase is equally amenable to harnessing. Strongly typed languages, clear module boundaries, and stable data structures make harnessing easier. Spaghetti monoliths fight every layer.
While still evaluating runtimes. If you are shopping between Claude Code, Codex, and DeepAgents, heavy investment in runtime-coupled harness components (hooks, plugins, middleware) gets thrown away when you switch. Invest only in portable components (constraints, linters, knowledge artifacts) until you have committed to a runtime.
With a team too small for the cross-functional spread. The 5-layer stack spans architecture, dev, platform, QA, and SRE. A 2-person team cannot staff all five. Trying creates harness debt in the form of half-built layers nobody maintains. Better to build Layers 2 and 4 well than all five poorly.
The overarching principle: if your project horizon is shorter than the payback period, it is the wrong time to invest in harness infrastructure. Start with the reactive approach (Hashimoto's pattern: fix failures as they occur) and formalize into layers only when the volume of failures justifies the investment.

Created by Han HELOIR YAN.