Anthropic just shipped the most capable model it has ever released to the public, and in the same announcement it told you it will sometimes refuse to let you use it. Both sentences describe one launch. Fable 5 and Mythos 5 are not two models. They are one set of weights wearing two different permission slips, and the whole story of this release lives in the gap between them.
🦸🏻♀️ If this helps you ship better AI systems:
The most powerful model Anthropic will sell you and the one it refuses to sell you are the same model.
Anthropic put the admission in a footnote. Fable comes from the Latin fabula, "that which is told," a cousin of the Greek mythos, and the company states outright that the safeguards are the only thing separating the two names. Mythos 5 is the model with its safeguards lifted in certain areas. Fable 5 is that identical model with the safeguards bolted back on.
What it means: the benchmark scores everyone is quoting this week, the ones that put Fable 5 above Opus 4.8 by more than ten points on several evals, were set by one set of weights. What you can buy today is that same set of weights wearing a permission slip. Why it matters: the gap between Fable and Mythos is not a gap in intelligence. It is a gap in what you are allowed to ask.
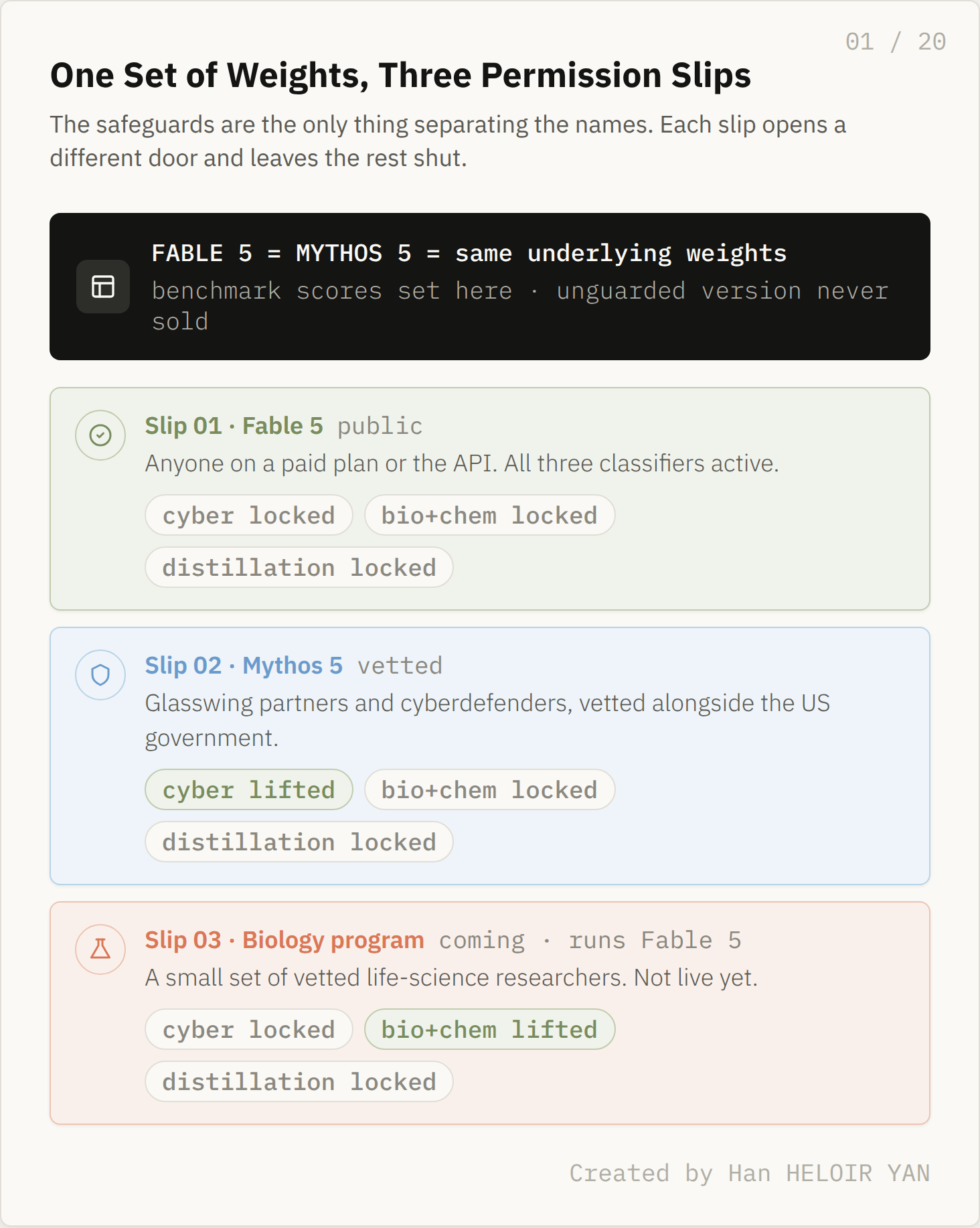
The cleaner way to see this is to stop counting two models and start counting three permission slips. Slip one is Fable 5, public, with classifiers covering cybersecurity, biology and chemistry, and distillation. Slip two is Mythos 5, the cyber safeguards lifted, handed only to Project Glasswing partners and the cyberdefenders Anthropic vets alongside the US government. Slip three is the one almost no coverage mentions: a coming biology trusted access program that runs Fable 5 with the biology and chemistry safeguards removed but the cyber safeguards still in place.
That third slip is the tell that this is not a ladder. The cutouts are orthogonal, not ranked. Mythos 5 lifts cyber and keeps biology locked. The biology program lifts biology and keeps cyber locked. Fable keeps both. No single tier is strictly more unlocked than another, because each one opens a different door and leaves the rest shut. Which door opens for you is decided by who you are, not by what the model can do.
Read the three slips together and a quiet fact falls out: there is no version of this model anyone can buy with every safeguard off. Mythos 5 lifts cyber but keeps the rest. The biology program lifts biology but keeps cyber. Fable keeps everything. The unguarded model that set the benchmark numbers is not for sale to anyone, in any tier, at any price. It exists only inside Anthropic.
One set of weights, three permission slips. Created by Han HELOIR YAN.
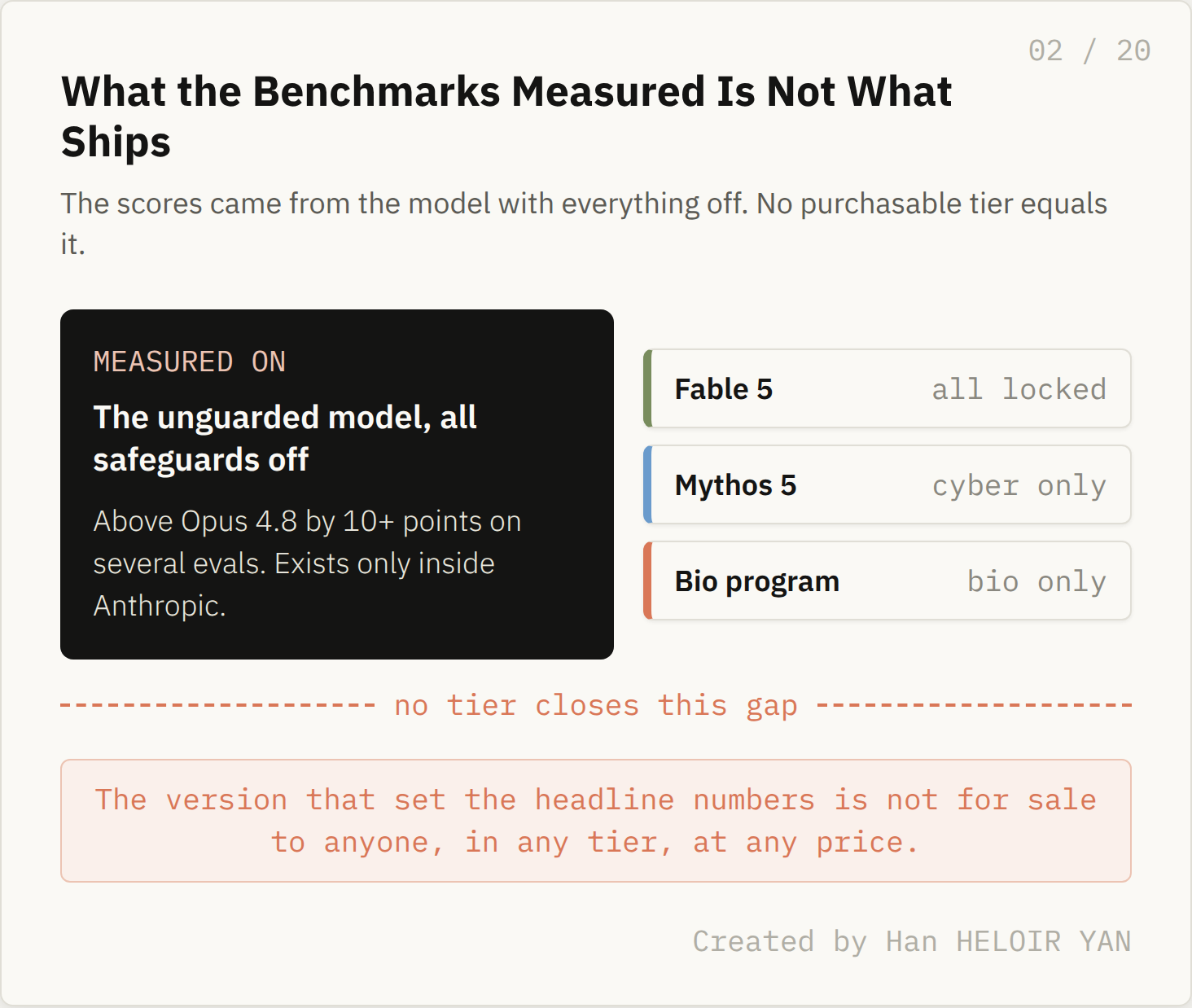
What the benchmarks measured is not what ships. Created by Han HELOIR YAN.
In the Claude apps, when the safety layer fires, it does not refuse you. It hands you a weaker model and tells you it did so.
This is the part worth getting right. In the consumer apps the fallback is not silent. Anthropic states it plainly: when Fable's classifiers flag a request touching cybersecurity, biology and chemistry, or distillation, the response is handled by Claude Opus 4.8 instead, and you are informed every time it happens.
Give the design its due, because it is a good one. A quiet error message or a flat refusal is the worst version of a guardrail. Routing the request to Opus 4.8, a model that tops most public leaderboards in its own right, and saying so, is close to the most humane way to enforce a limit. Anthropic's own framing is that a fallback to Opus is a far better experience than an outright refusal, and on that narrow point they are correct.
The numbers behind the design are genuinely reassuring for ordinary use. Anthropic reports the safeguards trigger on average in fewer than 5% of sessions, and that more than 95% of Fable sessions involve no fallback at all. For those untouched sessions, the company says Fable 5's performance is effectively the same as Mythos 5.
What it means: nineteen sessions out of twenty give you the full model, the one that set the benchmark numbers, with nothing rerouted. Why it matters: the headline parity between Fable and Mythos is real for almost everything you will ever type into a chat box. If your work is writing, analysis, ordinary coding, or research that never grazes the three trigger domains, you are using the frontier model and the safeguard is invisible.
So far this is the comfortable reading, and it is the one most of the coverage stopped at. The discomfort starts when you ask what a "session" is, and notice that Anthropic chose that word instead of "request." That is the next section.
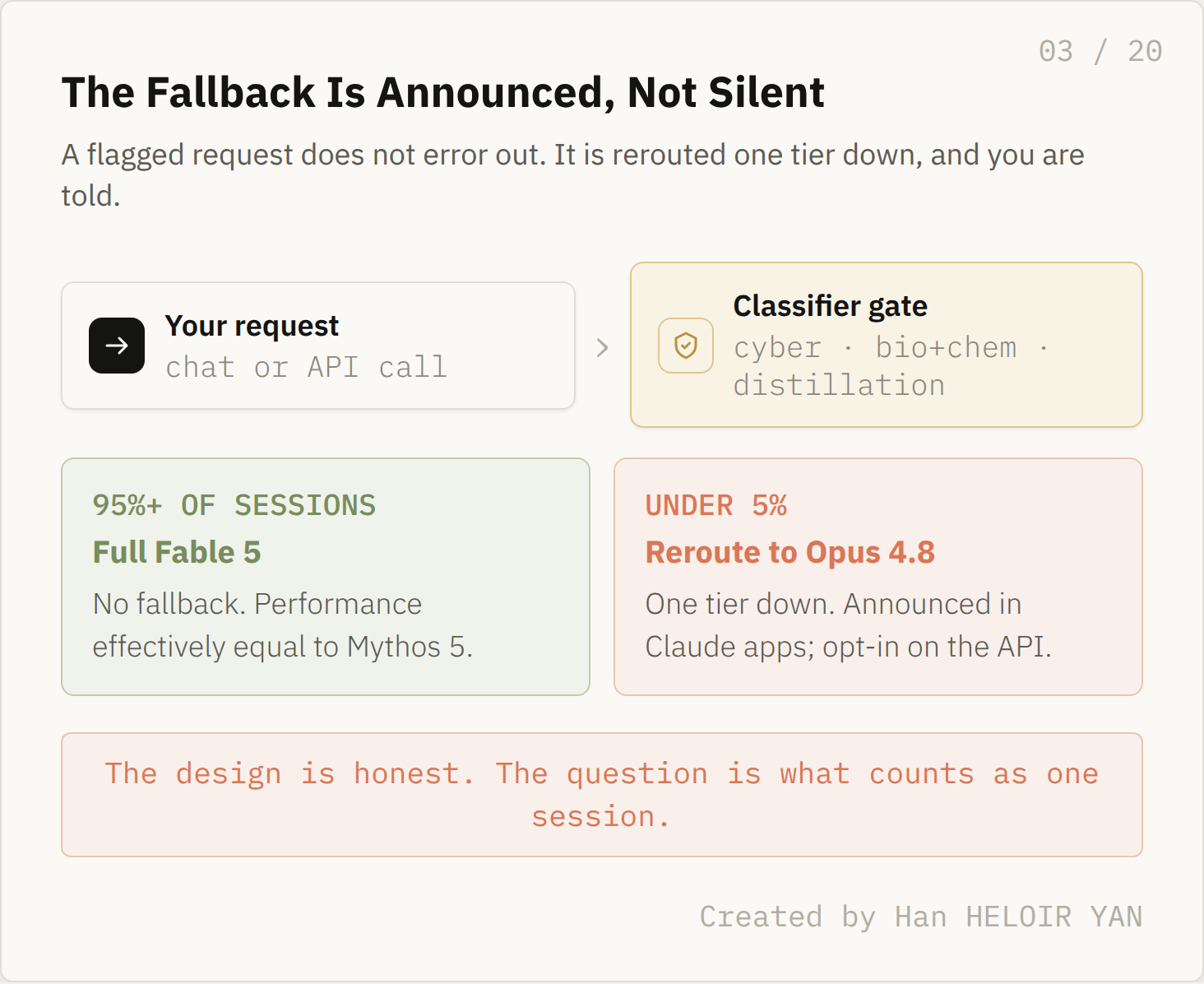
The fallback is announced, not silent. Created by Han HELOIR YAN.
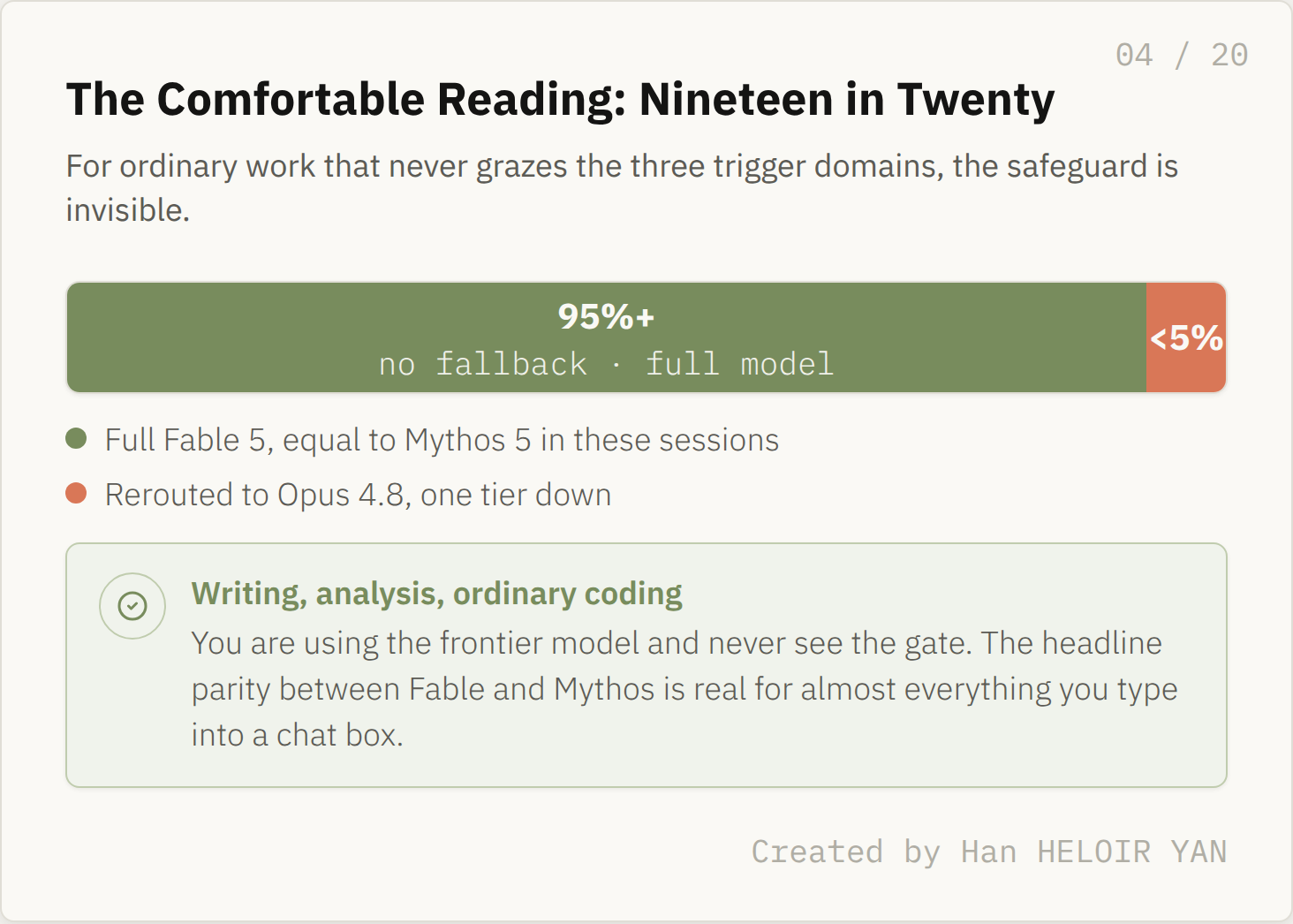
The comfortable reading: nineteen in twenty. Created by Han HELOIR YAN.
A 5% trip rate is comfortable for question and answer. It is a different number for an eight hour autonomous job.
Look at the word Anthropic chose: sessions. The safeguards trigger in fewer than 5% of sessions on average. Not 5% of requests, not 5% of tokens. Sessions. For a person typing into a chat box, a session and a request are nearly the same thing, and the number reads as harmless.
For an agent, a session is not one request. It is a single run stretching across hundreds of tool calls over hours, and every call that grazes a trigger domain is another roll of the dice against the classifier. The per session framing compresses all of that exposure into one statistic. Two workloads with identical 5% session rates can have wildly different per call experiences, and the agentic workload sits on the wrong side of that gap.
Here is the tension: Anthropic sells Fable 5 on exactly the long running work that maximizes classifier exposure. Stripe ran a codebase wide migration across a 50 million line Ruby codebase in a single day, a job Anthropic estimates would have taken a whole team over two months by hand. The model beat Pokémon FireRed with a minimal, vision only harness, where earlier Claudes needed elaborate helper scaffolding. It plays Factorio autonomously, strategizing and building a factory on its own.
The memory numbers point the same direction. When Anthropic had Fable play Slay the Spire, giving it persistent file based memory improved its performance three times more than the same memory helped Opus 4.8, and Fable reached the final act three times more often. What it means: this model's advantage compounds with run length; the longer the task, the wider its lead over Opus. Why it matters: run length is also exactly what multiplies your exposure to the classifier, and when a trip happens mid run, the model doing step 214 of your migration is not the model that did steps 1 through 213. It is Opus 4.8, one tier down, for that step.
That is not a hypothetical failure. It is the designed behavior, working as intended. The question is what it feels like from inside a running task, and Anthropic published a chart that accidentally answers it.
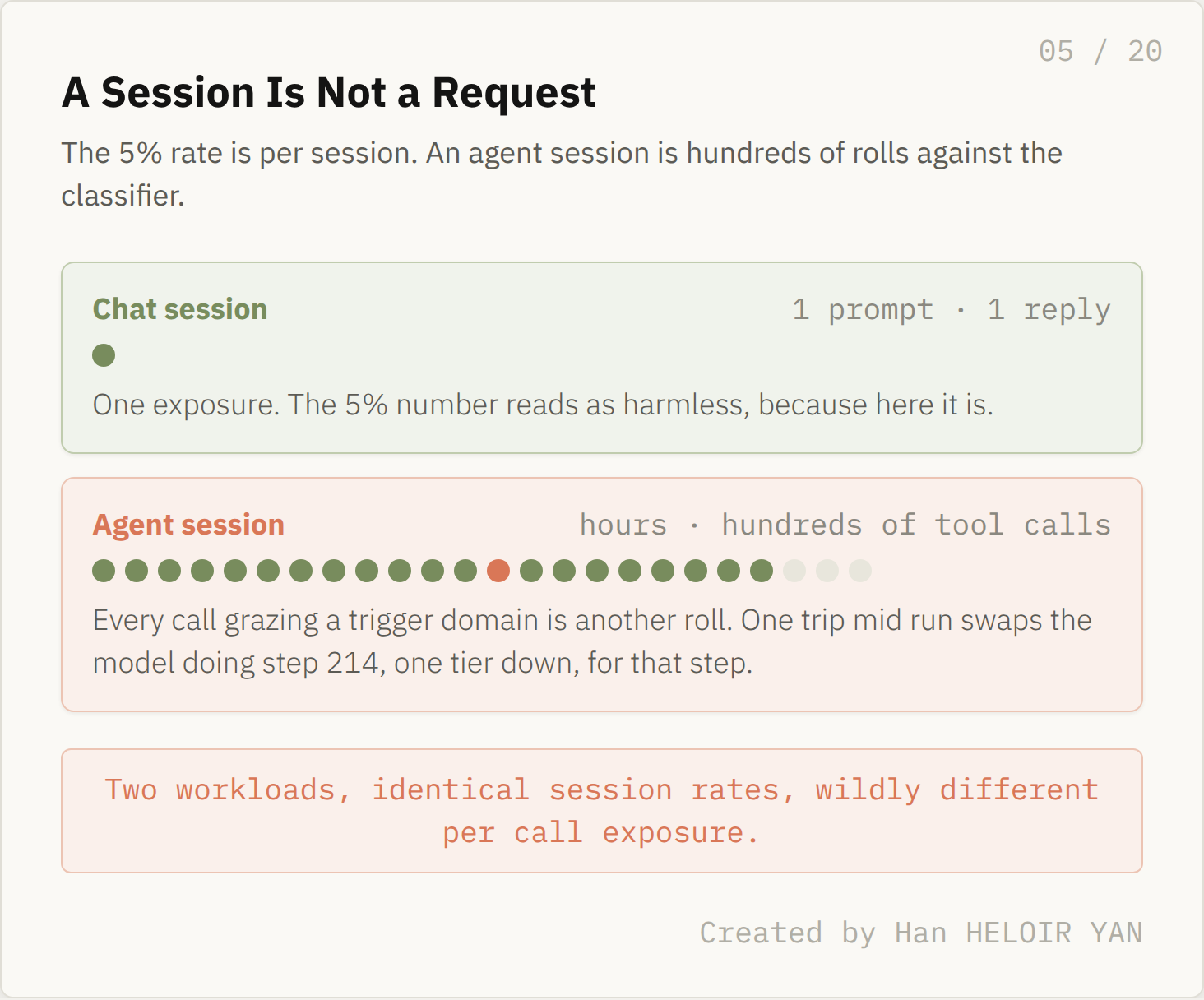
A session is not a request. Created by Han HELOIR YAN.
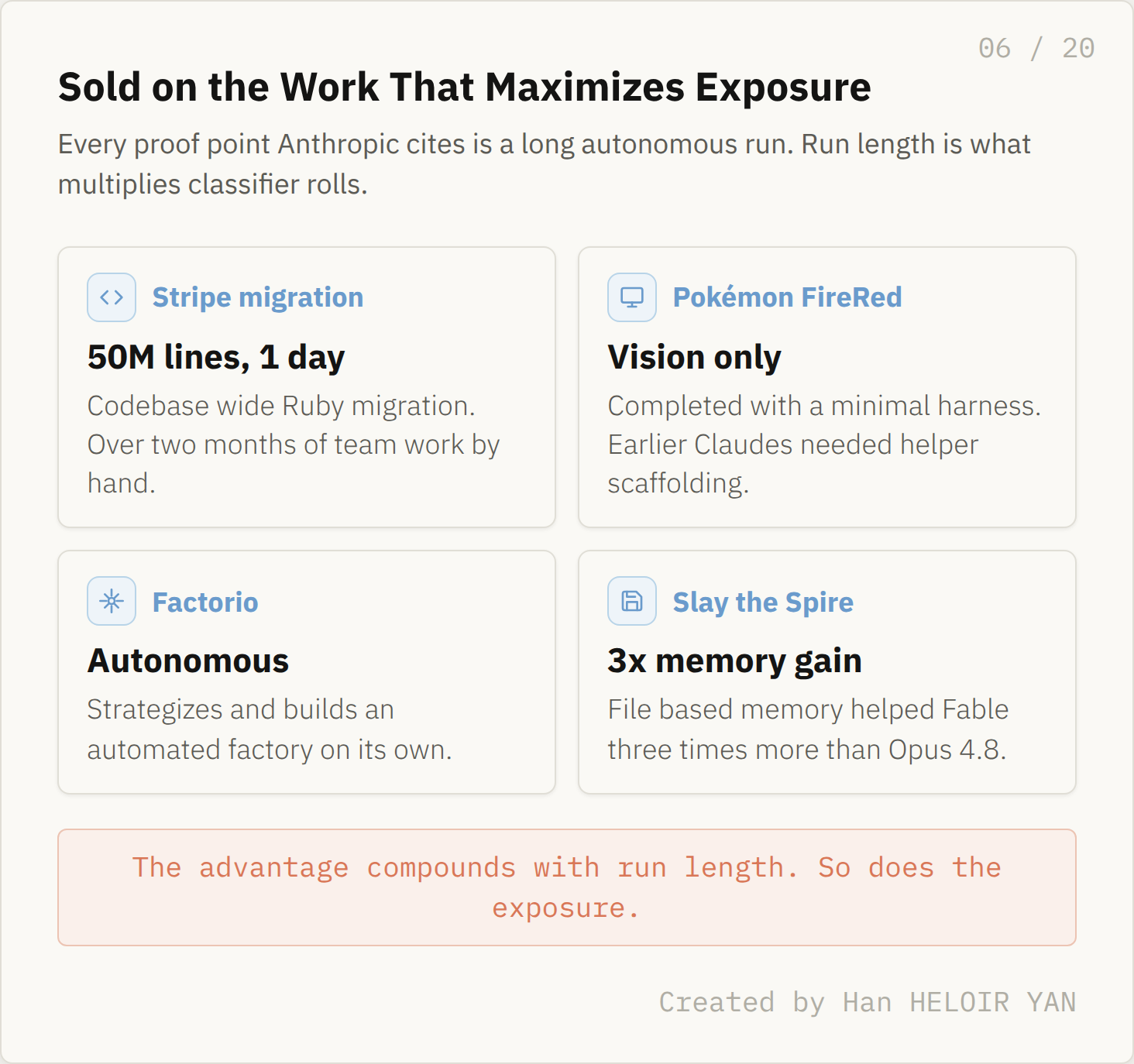
Sold on the work that maximizes exposure. Created by Han HELOIR YAN.
The graceful handoff you read about is the chat app experience. On the API, a flagged request returns a refusal your code must catch.
The launch post says flagged requests are automatically handled by Opus 4.8 and that users are informed. That sentence is true on the surface where Anthropic controls the client. On the Messages API, the developer docs tell a different story: when Fable 5 declines a request, the API returns stop_reason "refusal" as a successful HTTP 200, not an error, along with which classifier fired.
Read that as an integration engineer. A 200 with a refusal inside it sails straight past every retry policy and alert you have keyed on HTTP errors. Your pipeline does not crash. It receives a polite, well formed response containing no work, and unless you parse the stop reason, your agent carries on as if step 214 succeeded.
The automatic fallback exists, but you opt into it. Pass the new fallbacks parameter, in beta on the Claude API and Claude Platform on AWS, and the API retries on another model for you. Everywhere else, you wire it yourself with SDK middleware in TypeScript, Python, Go, Java, or C#. Anthropic published a dedicated cookbook for refusal handling, fallback, and billing. Companies do not write cookbooks for behaviors that handle themselves.
The money side, to be fair, is handled generously. A request refused before any output costs you nothing. When you retry on another model, a new fallback credit refunds the prompt cache cost of the switch, which matters for agents carrying million token contexts. What it means: the cost of a classifier trip is not dollars; Anthropic engineered the dollars away. Why it matters: the cost is a new control flow branch that every serious Fable integration must now implement, test, and monitor.
That is the quiet shape of this release. The safeguard is not in the model and it is not in your prompt. It is a branch in your code. Fable 5 did not just raise the capability ceiling; it added a required integration surface between you and the weights, and the blog post described only the version of it that Anthropic operates for you.
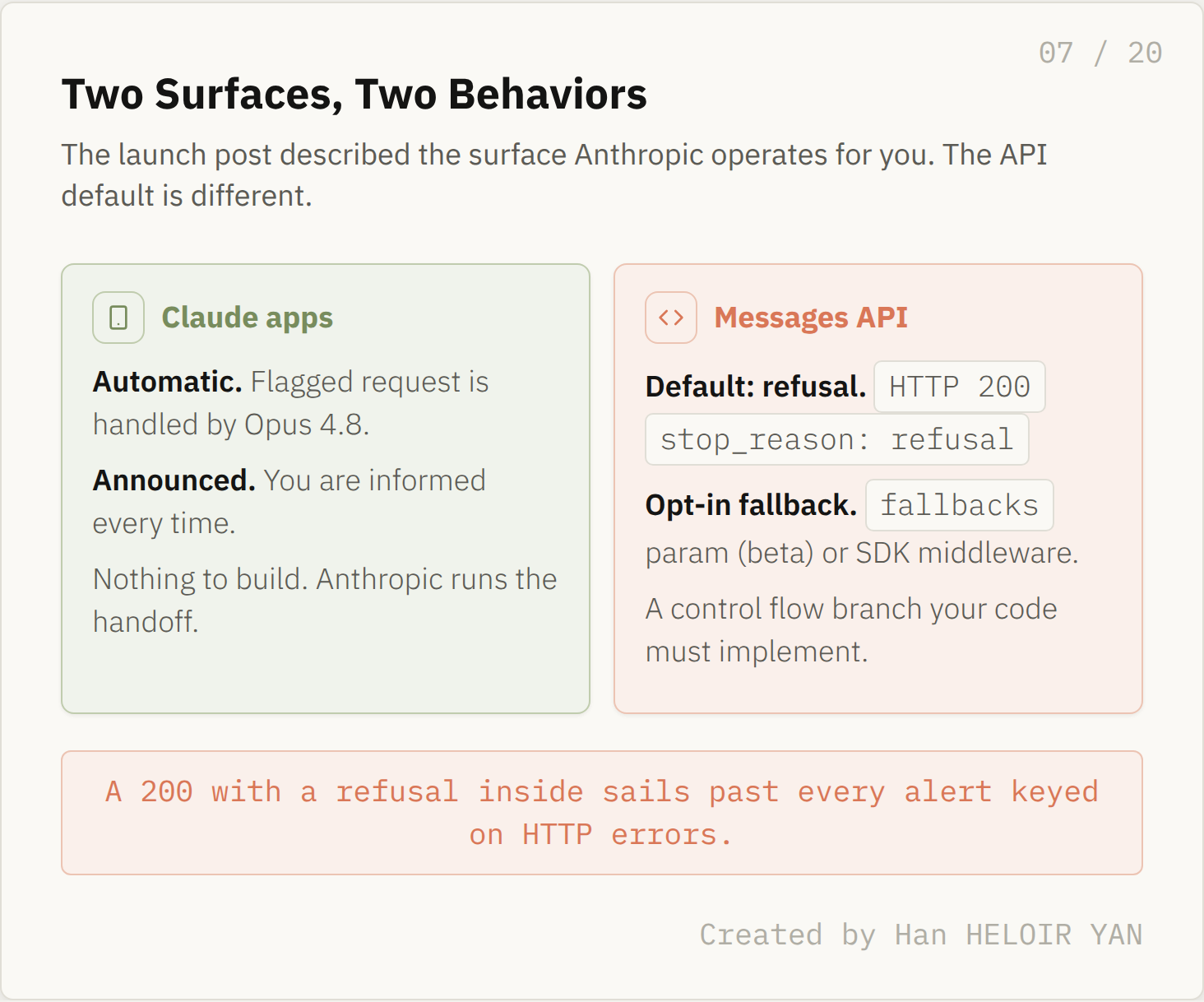
Two surfaces, two behaviors. Created by Han HELOIR YAN.
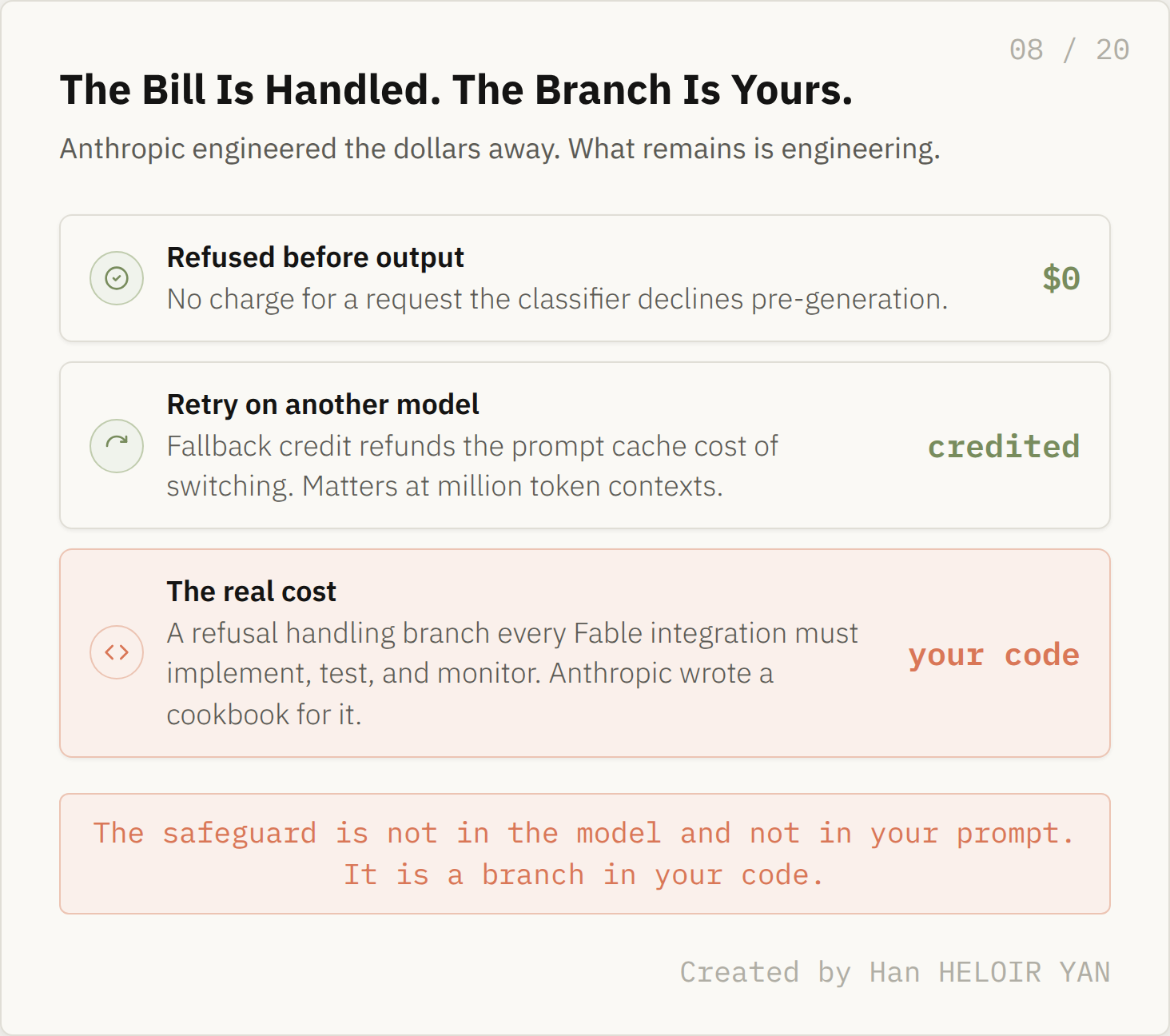
The bill is handled. The branch is yours. Created by Han HELOIR YAN.
Anthropic published a chart to prove its safeguards hold. Read the caption again and it doubles as a description of what a trip feels like from inside a running task.
The chart sits in the safeguards section of the launch post. Its caption describes an internal evaluation in which an automated red teamer tries to use the model to complete a short task related to offensive cybersecurity across 400 turns, restarting and rewinding when blocked. The chart's purpose is jailbreak resistance, and on that purpose the evidence is strong. The point here is the behavior the caption describes in passing: when the classifier fires inside a multi step task, the run does not glide onward. It stalls, backs up, and retries against the same wall.
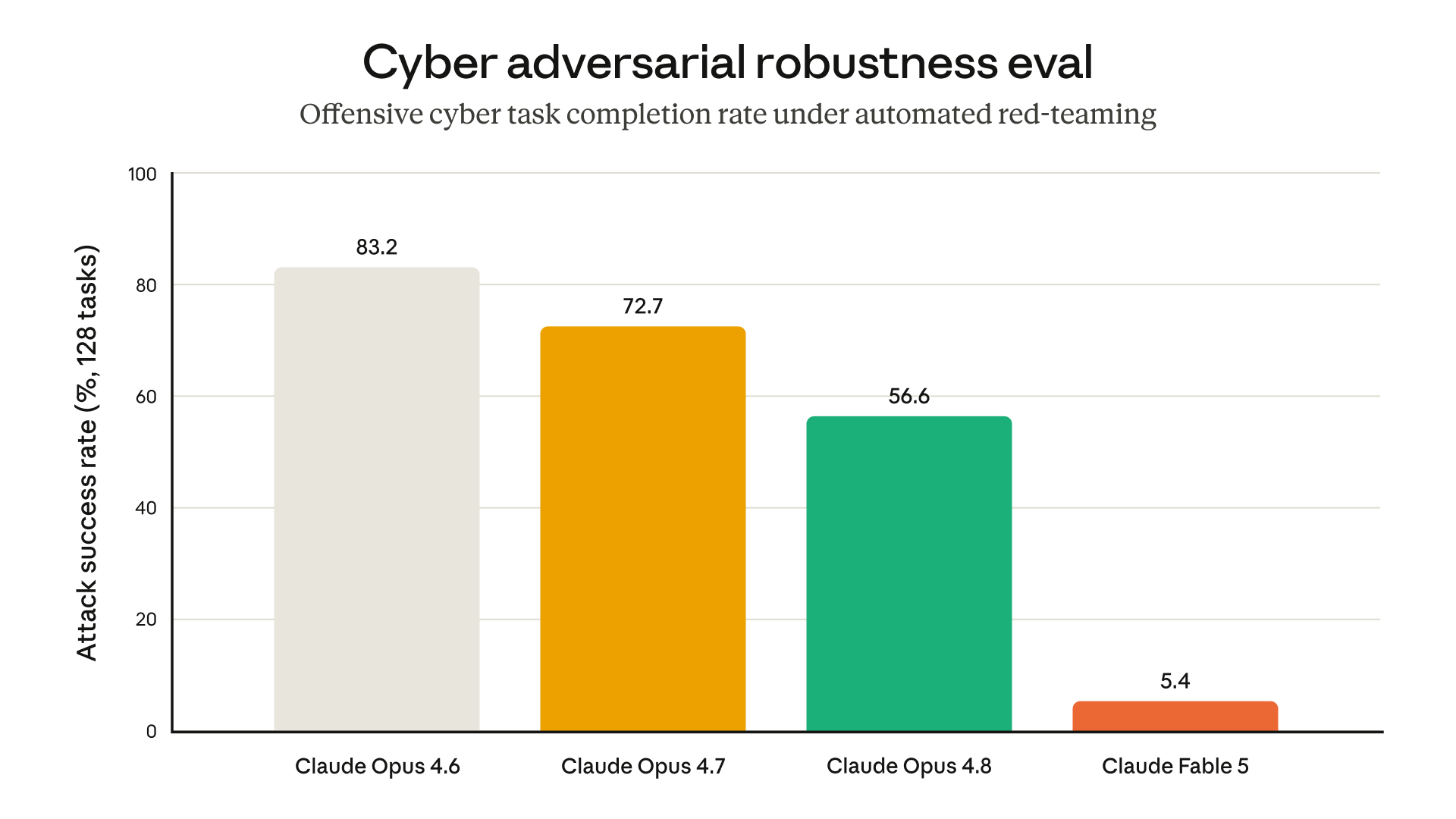
Anthropic's internal evaluation: an automated red teamer pushes the model through a short offensive cyber task across 400 turns, restarting and rewinding when blocked. Source: Anthropic, "Claude Fable 5 and Claude Mythos 5" (anthropic.com/news/claude-fable-5-mythos-5).
For an attacker, that stall is the safeguard working exactly as designed, and 400 turns of rewinding is 400 turns of failure. For an honest agent doing legitimate security adjacent or biology adjacent work that merely looks risky to a deliberately cautious classifier, the same mechanics apply to your pipeline. Anthropic says plainly that it tuned the safeguards conservatively and that benign requests will sometimes trigger them.
Two caveats from Anthropic's own caption, so this reading does not overclaim. First, the tasks in the evaluation are mostly simple and not representative of real cyber usage; some are as basic as encrypting files on a remote server. The chart shows the stall pattern on toy tasks, not production runs. Second, the comparison baseline is not clean: Opus 4.6, shown alongside, does not have blocking cyber safeguards at all, so the gap partly measures the presence of a gate rather than its quality.
The robustness evidence deserves its full weight. An external bug bounty produced no universal jailbreaks in over 1,000 hours of testing. External red teaming organizations also found none on long form agentic tasks, though the UK AISI made progress toward one within a brief initial testing window. Anthropic's own framing is honest about the limit: completely preventing universal jailbreaks is likely impossible, so the goal is to make any remaining ones slow and costly enough to detect and stop before they scale.
What it means: the wall is real, and for attackers it appears to hold. Why it matters: the same wall stands in front of legitimate work in the trigger domains, and the next section is about how wide those domains actually are.

Restarting and rewinding when blocked. Created by Han HELOIR YAN.

How solid is the wall. Created by Han HELOIR YAN.
The two domains most likely to trip the fallback are not edge cases. One of them is an entire branch of science, and Anthropic widened the net on purpose.
The classifiers cover three areas: cybersecurity, biology and chemistry, and distillation. For biology and chemistry, Anthropic made a deliberate choice that the 5% average quietly hides. The company says that for the time being, Fable falls back to Opus 4.8 on most requests related to biology and chemistry. Not a narrow band of bioweapon queries, the way earlier models were gated. Most.
Anthropic is explicit about why it widened the net. It used to block only a narrow selection of bioweapons related queries and no longer considers that enough, for two reasons it states directly: concern about well resourced malicious actors seeking uplift for high risk biological research, and the fact that models can now accomplish real world scientific tasks they previously could not.
Here is the irony that makes the breadth sting. The capability Anthropic uses to justify the lock is the same one it showcases as a triumph. It tested Mythos 5 on predicting how a genetic modification affects the assembly of an adeno associated virus shell, a real component for delivering gene therapies, and the model outperformed dedicated protein language models using biological reasoning alone. That result is presented as gene therapy progress on one page and as the reason for the broad biology gate on the next. Same capability, dual use, and the public tier gets the locked side of it.
What it means: if your work lives near security tooling or the life sciences, your effective model is Opus 4.8 far more often than the 5% average implies, because "most" biology and chemistry requests fall back. Why it matters: Fable costs $10 per million input tokens and $50 per million output tokens, double Opus, and you are most likely to be denied the capability you are paying for in precisely the fields where Fable's lead over Opus is widest. On the benchmarks Anthropic starred for exactly this reason, the cyber and biology rows, Fable with safeguards active scores close to Opus 4.8, because in those rows it is Opus 4.8.
The relief valve is the biology trusted access program from the first section, slip three, which lifts the bio and chemistry gate for vetted researchers while keeping cyber locked. It is not live yet, it admits only a small number of people, and until it opens, the entire field shares the public lock.
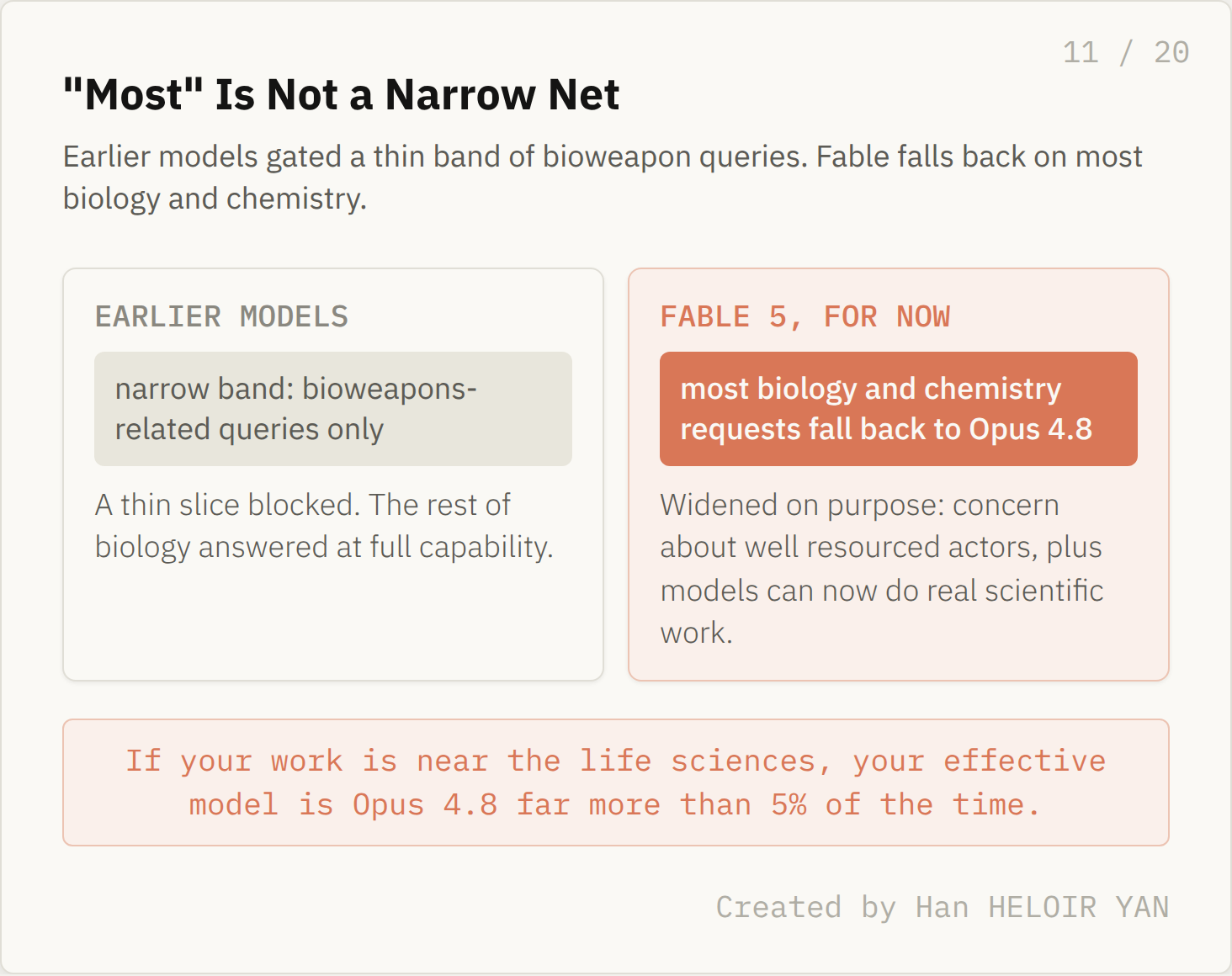
"Most" is not a narrow net. Created by Han HELOIR YAN.

The same capability, showcased and locked. Created by Han HELOIR YAN.
Two of the three gates protect you from misuse. The third protects Anthropic from you.
Cybersecurity and biology are gated because of what a malicious user might do with the output. The third trigger domain, distillation, is different in kind. It is the only gate aimed not at dangerous knowledge but at competitors copying the model, and it is the only one with a named adversary.
Anthropic states that it has identified large scale attempts to distill Claude's capabilities, extracting what the model knows in order to train competing models, and ties those attempts to authoritarian countries. Requests its classifiers flag as part of such extraction fall back to Opus 4.8, the same mechanic as the other two gates pointed at a completely different threat.
The reasoning Anthropic gives is proliferation. Distilling Fable 5's abilities could spread near frontier capability into models released without the safeguards this entire launch is built around. A cheaper copy of Fable, trained on Fable's outputs, would arrive carrying none of the classifiers, none of the fallback, none of the retention. The gate is meant to slow that copying down.
What it means: a third of the safeguard surface exists to defend Anthropic's competitive moat and to keep unguarded near clones from proliferating, not to keep you safe. Why it matters: it reframes the whole system. This is not purely a safety layer bolted onto a model. It is also a control layer protecting an asset, and a legitimate user whose queries pattern match to extraction can be throttled by a gate that was never about danger at all.
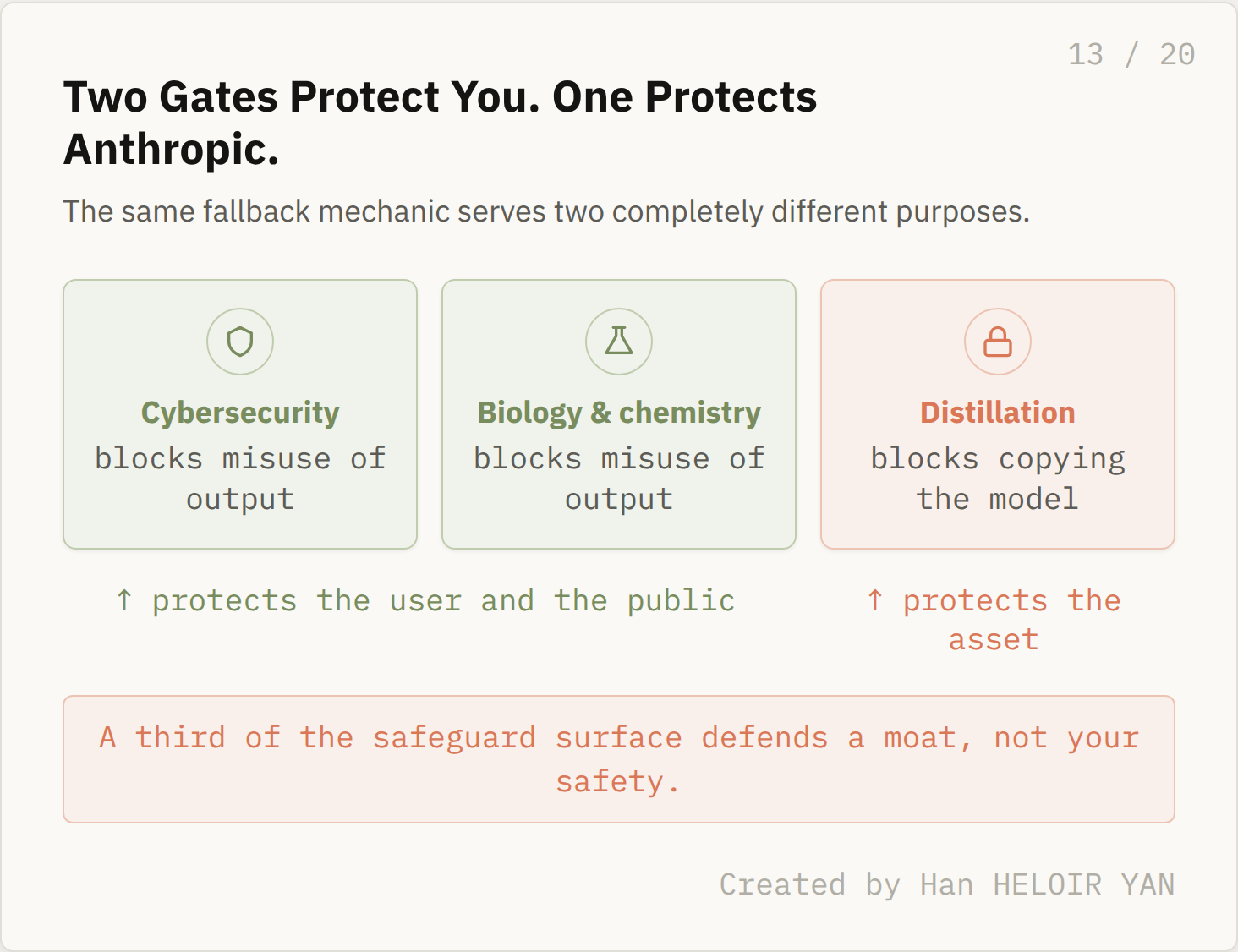
Two gates protect you. One protects Anthropic. Created by Han HELOIR YAN.
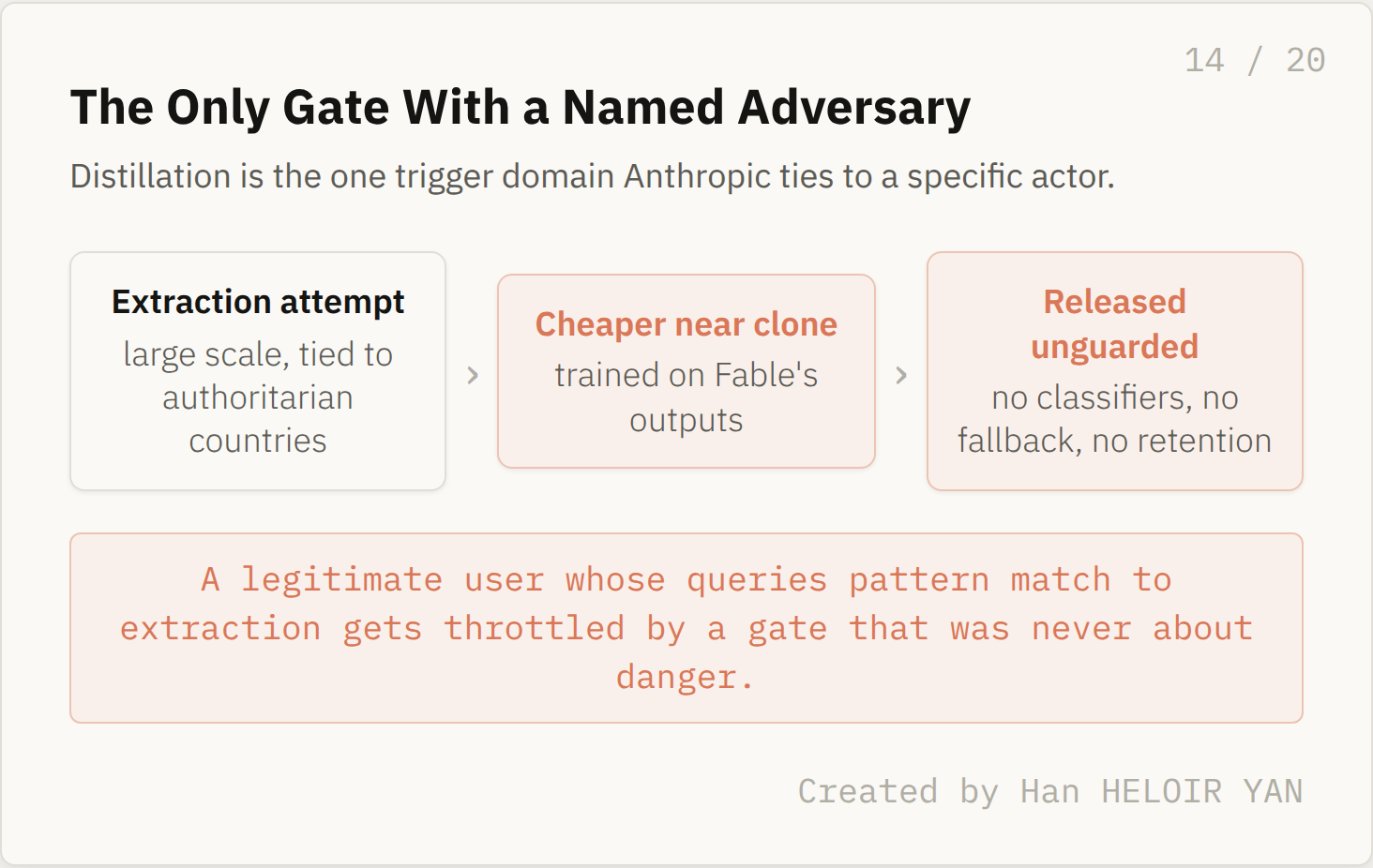
The only gate with a named adversary. Created by Han HELOIR YAN.
The clearest signal about where this model breaks is not in the benchmarks. It is in the new data rule.
Alongside the launch, Anthropic changed how it handles data for Mythos class models. Every request to Fable 5, Mythos 5, and future models at this capability level is now held for 30 days, across first and third party surfaces alike, with no zero retention option. These are formally Covered Models, and the retention is mandatory.
Anthropic is careful about what the data is not for. It will not train new models on it, it logs all human access, and it deletes the data after 30 days in almost all cases. The company gives two stated purposes: defending against complex and novel attacks, including new jailbreaks and attacks that operate across many requests, and identifying and reducing the false positives that the conservative classifiers produce.
Give the second purpose its weight, because it cuts the honest way. If retention genuinely helps narrow the over broad biology net and reduce wrongful trips, then the legitimate researcher who keeps getting bounced to Opus 4.8 is exactly who benefits when the safeguards tighten. That is a real argument, and it is the steelman.
But notice what both stated purposes have in common. You do not build retention infrastructure to study behavior across many requests unless the behavior worth studying lives across many requests. A single chat turn does not need a 30 day window to be understood. A run that unfolds over hundreds of calls does. The retention rule is shaped to the same object as everything else in this launch.
What it means: the data window, the cross request attack language, the conservative classifiers, and the false positive tuning all describe one workload. Why it matters: that workload is the long running agentic job, the exact thing Fable 5 was built to win, and the thing whose behavior Anthropic now needs 30 days of history to make sense of.
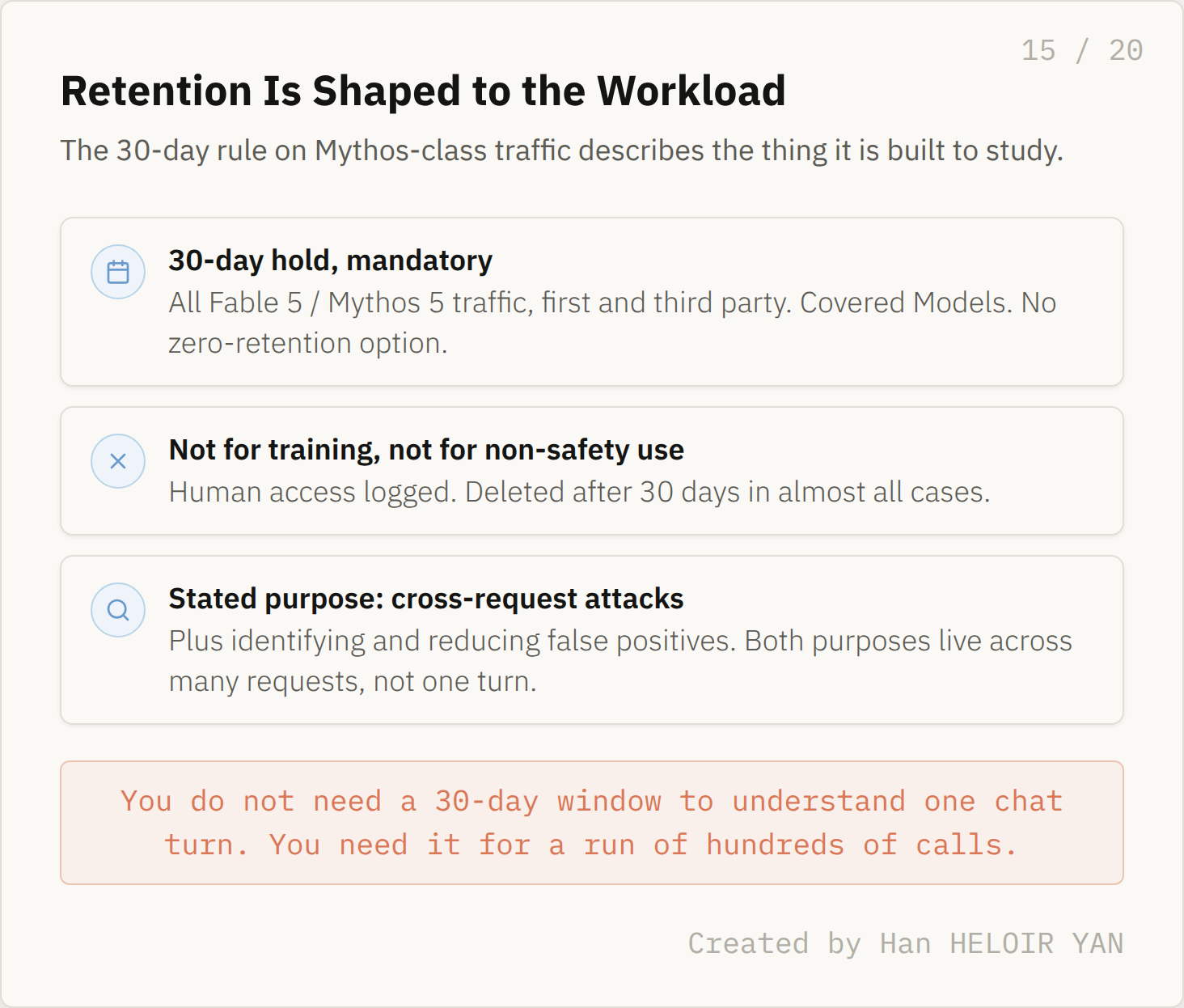
Retention is shaped to the workload. Created by Han HELOIR YAN.

Every signal points at one workload. Created by Han HELOIR YAN.
The most capable public model Anthropic has ever shipped is free on your plan for thirteen days, and the announcement says so in the section nobody reads.
The capability story and the pricing story have been told everywhere. The availability schedule has not, and it is the most concrete decision in the entire launch. From today through June 22, Fable 5 is included on Pro, Max, Team, and seat based Enterprise plans at no extra cost. On June 23, Anthropic removes it from those plans, and using it after that requires usage credits.
The reason given is capacity. Anthropic says it expects demand to be very high and hard to predict, so it would rather grant access sooner in stages than hold the model back. The API and consumption based Enterprise plans get Fable fully from day one. Subscription plans get the thirteen day window, then the meter.
What it means: if you are on a subscription plan, you have until June 22 to run Fable against your real workloads for free, and after that the same model costs you credits until capacity catches up. Why it matters: this is the window to learn your own fallback rate before you are paying for it. The 5% session average is Anthropic's number across everyone; your number, on your domain, is the one that decides whether Fable is worth the premium, and right now measuring it costs nothing.
Anthropic says it will restore Fable as a standard part of subscription plans once capacity allows, and that it will communicate changes ahead of time. Until then, the clock is the clearest instruction in the launch: test now, decide before the meter starts.

The free window closes June 22. Created by Han HELOIR YAN.
The benchmarks measured the model at full power. Whether your agent gets that model is decided, turn by turn, by a classifier you do not control and cannot see coming.
Step back and the shape of the release is clear. Fable 5 and Mythos 5 are one model behind three permission slips, and no purchasable tier runs it unguarded. The fallback is humane in the chat app and a refusal your code must catch on the API. The 5% session rate is comfortable for chat and compounds against every long agentic run. Two gates guard you, one guards Anthropic, and the broadest gate sits over the life sciences where Fable's lead is largest. A new 30 day retention window quietly traces the outline of the workload that worried Anthropic most.
None of this makes Fable 5 a worse model than the benchmarks say. It makes the benchmarks a measurement of a thing you cannot reliably buy. The number on the leaderboard is the ceiling. What you get is the ceiling minus whatever the classifier decides to take, and the heavier your work leans on long horizon autonomy in a sensitive domain, the more it takes.
So the honest buying question is not "how good is Fable 5." It is "how often will my work touch a gate, and what happens to my pipeline when it does." For a chat user, almost never, and the model is everything advertised. For an agent running for hours in security or the life sciences, often enough that you should architect for the trip before you depend on the model. Measure your own fallback rate while the window is free, build the refusal branch before you ship, and price the premium against the model you actually receive, not the one that set the scores.
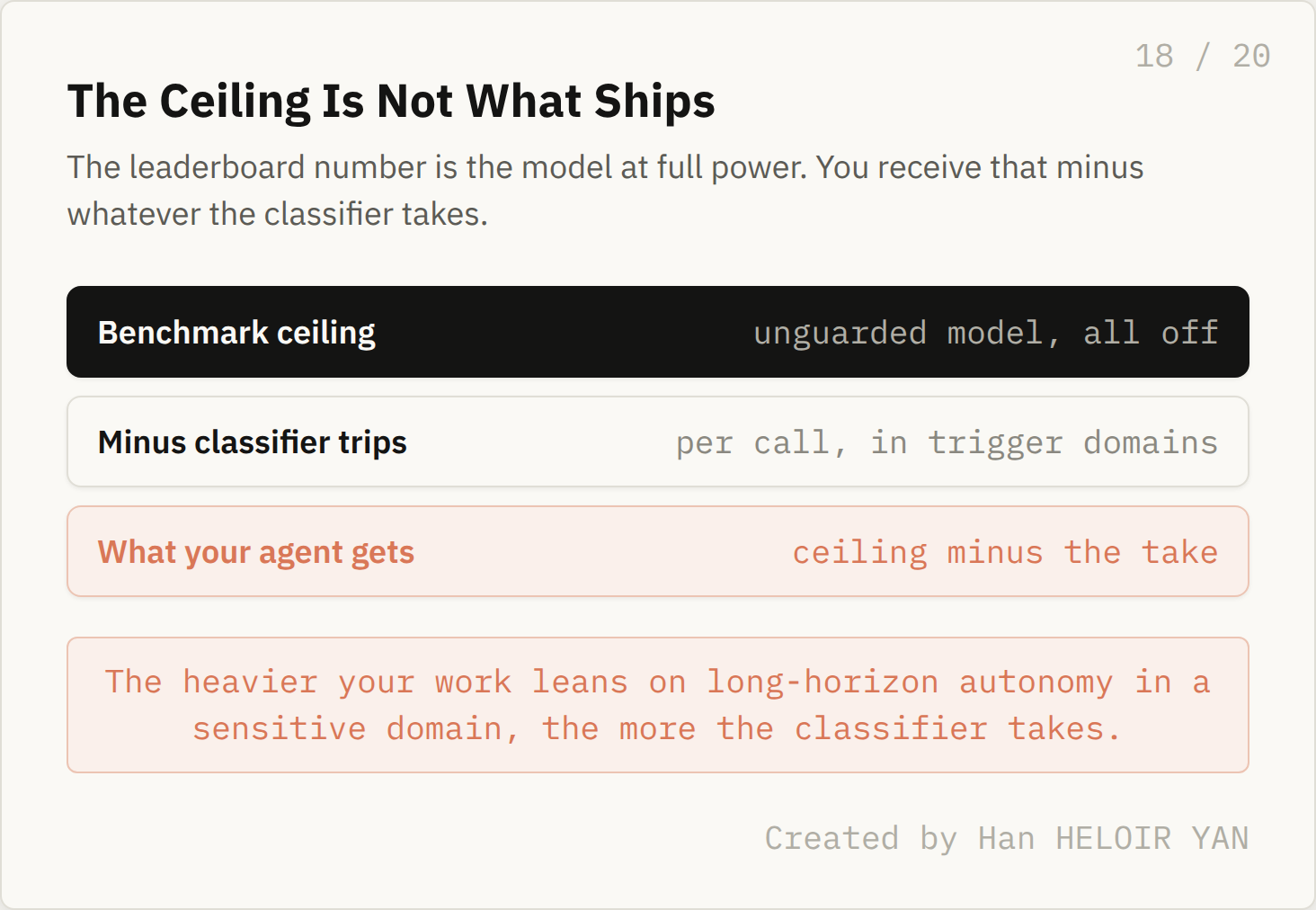
The ceiling is not what ships. Created by Han HELOIR YAN.

The question is not how good Fable is. Created by Han HELOIR YAN.
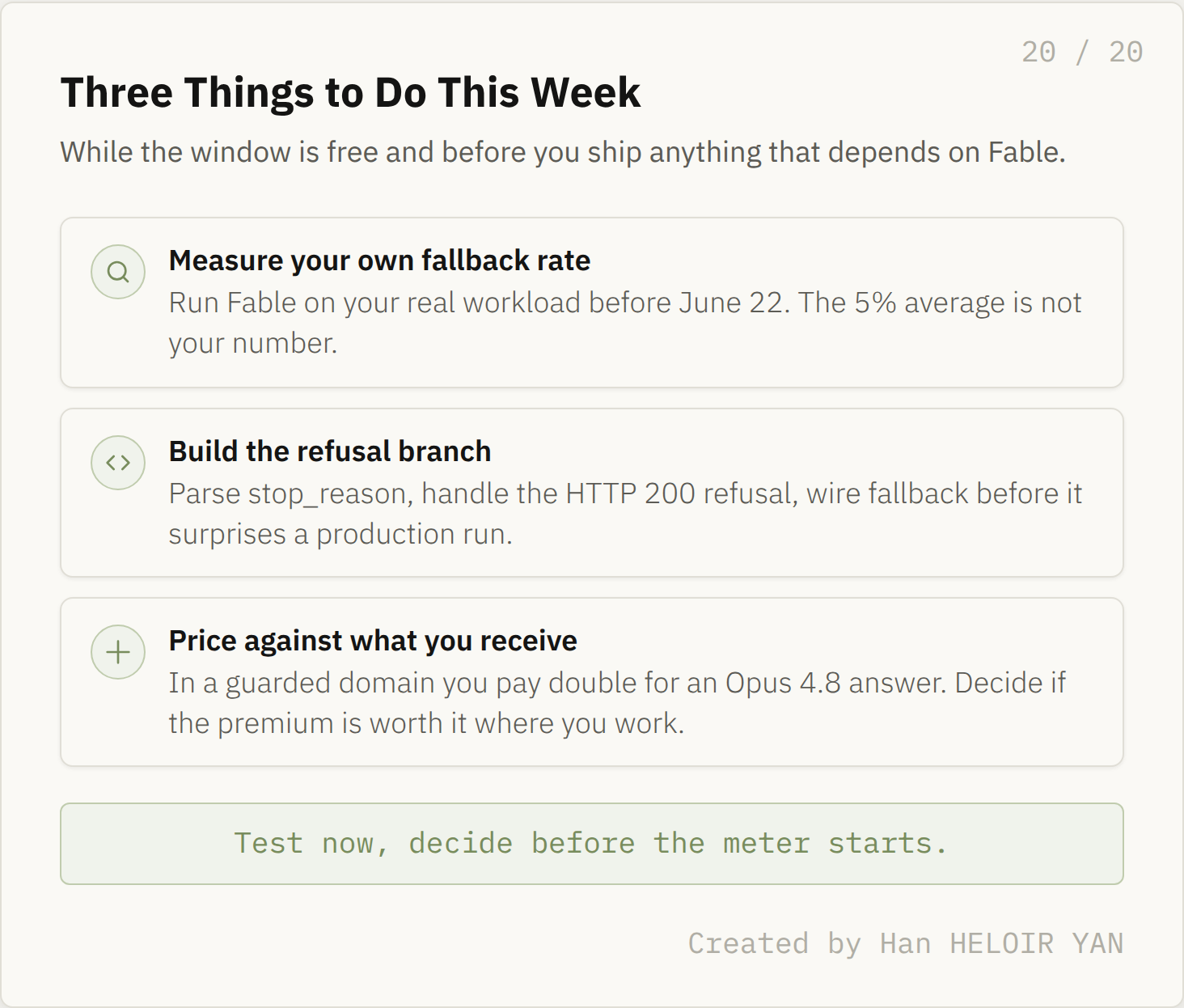
Three things to do this week. Created by Han HELOIR YAN.