ChatGPT's Dreaming Is Not Memory. It's Your Context Layer, Gone.
You open a fresh ChatGPT and re-explain your project for the fortieth time. Or worse: it confidently references a launch date that slipped two months ago, as if it were still ahead of you. That friction has a name, staleness, and on June 4 OpenAI shipped a fix for it that actually works.
The fix is called Dreaming, and here is the part the launch coverage skipped. It does not store what you tell it and wait. It runs a process in the background that rewrites what it knows about you, on its own schedule, and you will not see the edits. This is not a memory feature getting better. This is a layer of your stack quietly changing hands.
How Dreaming actually works
Start with the lineage, because the shape of the change is the whole story. OpenAI shipped its first memory feature, saved memories, in 2024. It was a list. You had to say "remember this," and once you did, the fact froze in place and slowly went wrong as the world moved on.
In April 2025 came the first version of Dreaming, a background process that could reference your wider chat history rather than only the saved list. Useful, but it could not stand on its own. On June 4, 2026, Dreaming V3 removed that dependency. Background synthesis is now the standalone foundation. The saved list is no longer required for ChatGPT to know things about you.

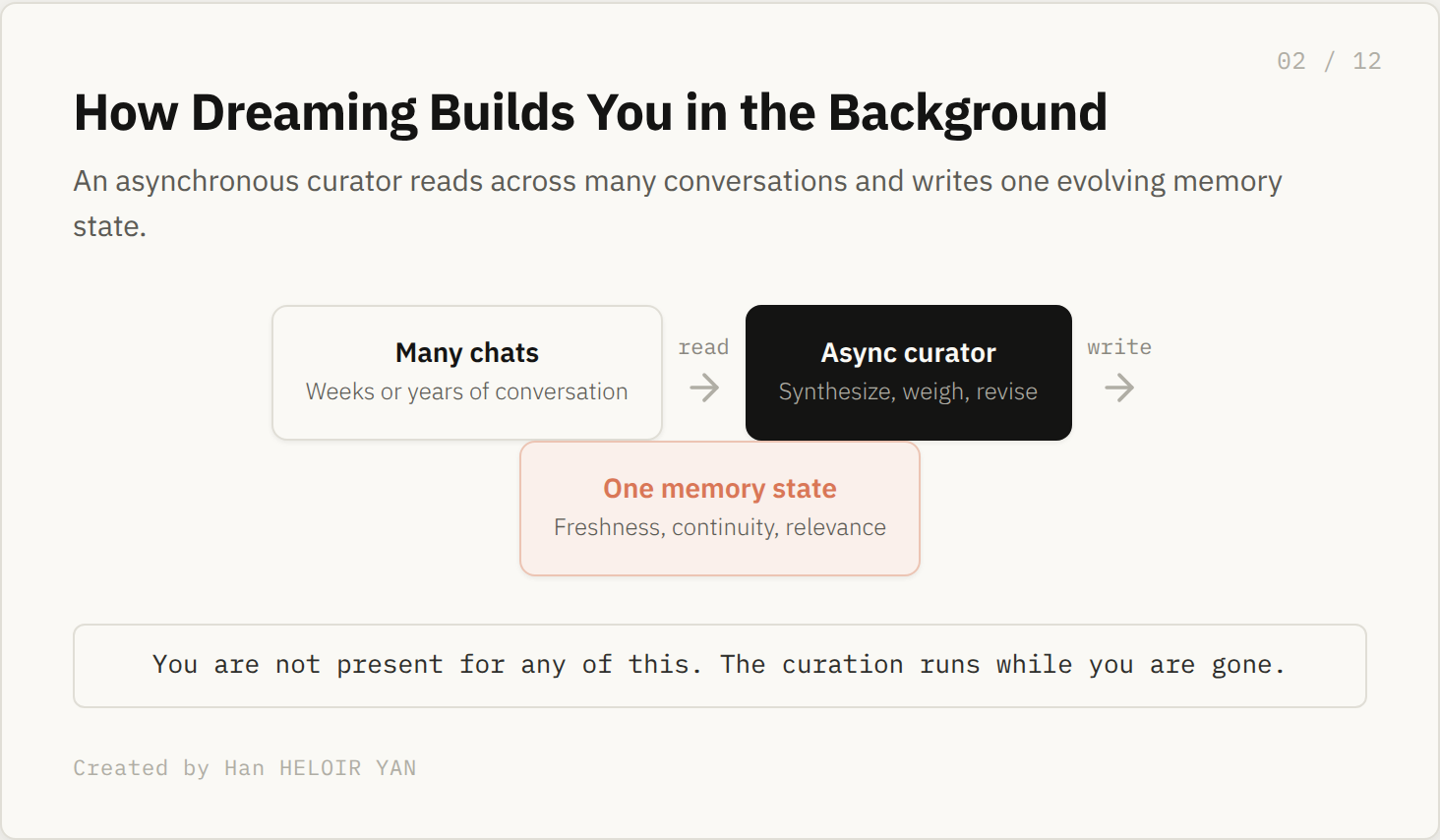
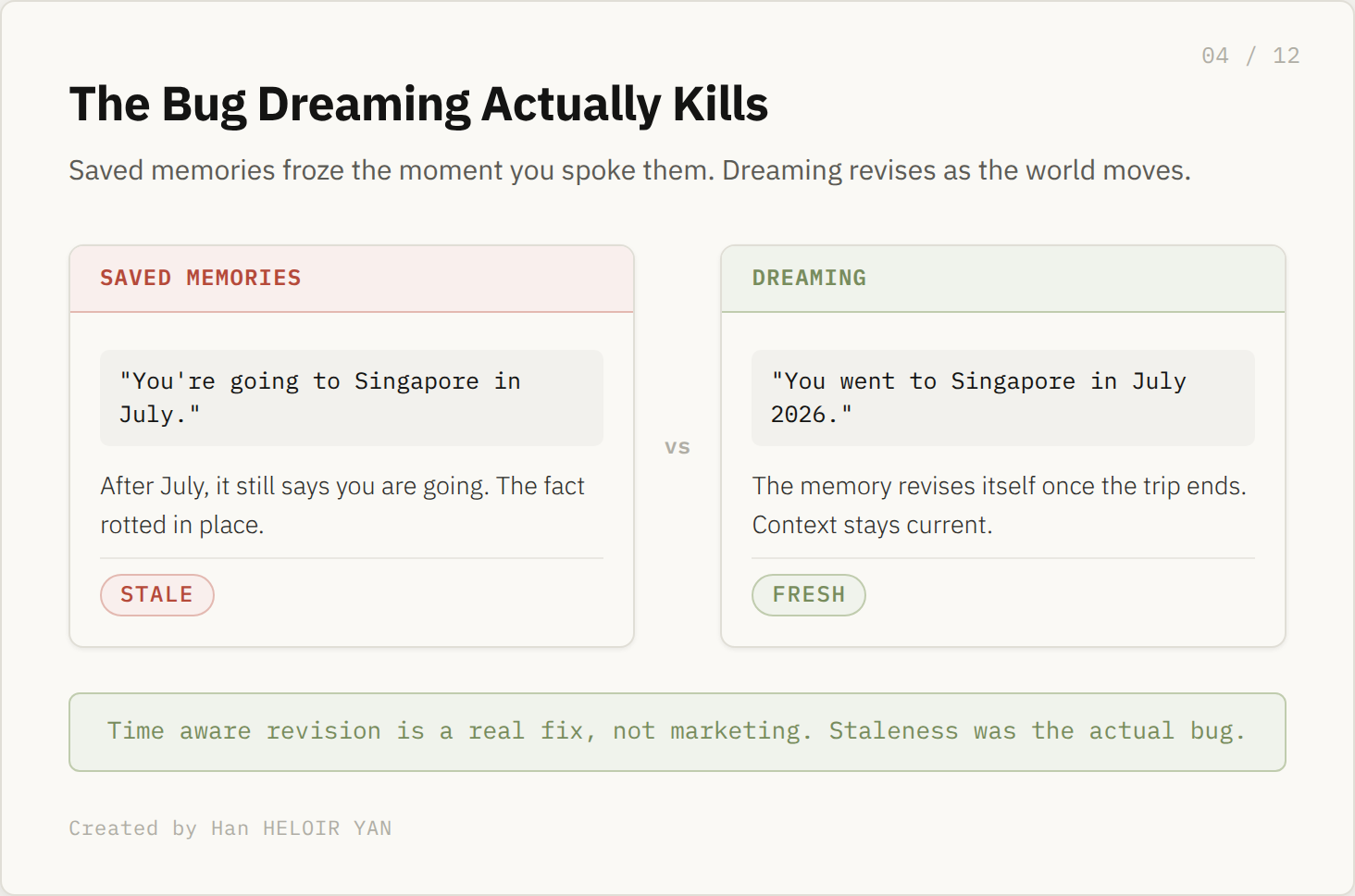
The mechanism is an asynchronous curator. It reads across many conversations, synthesizes a single memory state, and revises that state as time passes. OpenAI's own example: a memory that reads "you are going to Singapore in July" rewrites itself into "you went to Singapore in July 2026" once the trip is behind you. You do not prompt any of this. It happens while you are not in the chat.
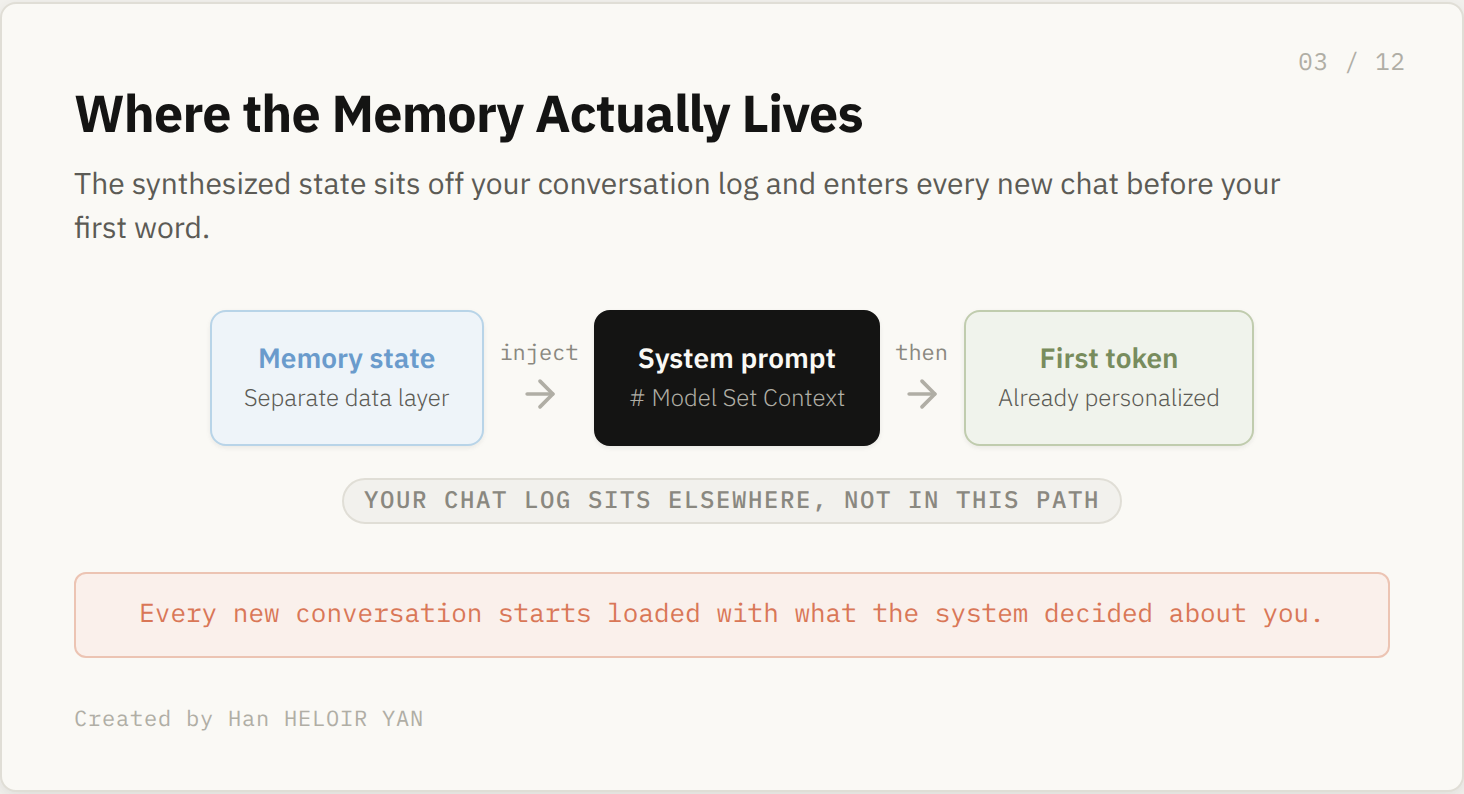
Here is the placement that matters most for anyone building on the platform. The synthesized state does not live inside your conversation log. It sits in a separate data layer and is injected into the system prompt at inference, which means every new chat starts already loaded with what the system concluded about you across past sessions.
Two more facts set the table. OpenAI says a roughly 5x reduction in the compute needed to serve Dreaming is what makes the free tier rollout practical, and the same efficiency gain raises memory capacity for Plus and Pro. The stated goals are three: freshness, continuity, relevance. Hold onto those three words. Every failure later in this piece is one of them turned inside out.
What it genuinely fixes
Be honest about the win before you reach for the knife. The old model had a structural flaw: a saved fact was true at the instant you stated it and rotted from there. You told it your launch was in July, and in September it still thought July was ahead. Time aware revision fixes that at the root, and that is a real improvement, not a marketing line.
The daily payoff is concrete. You stop re-establishing context every session, and personalization carries across months instead of resetting to zero each morning. For a tool you reach for dozens of times a day, that is the difference between an assistant that knows your work and a stranger you brief from scratch.
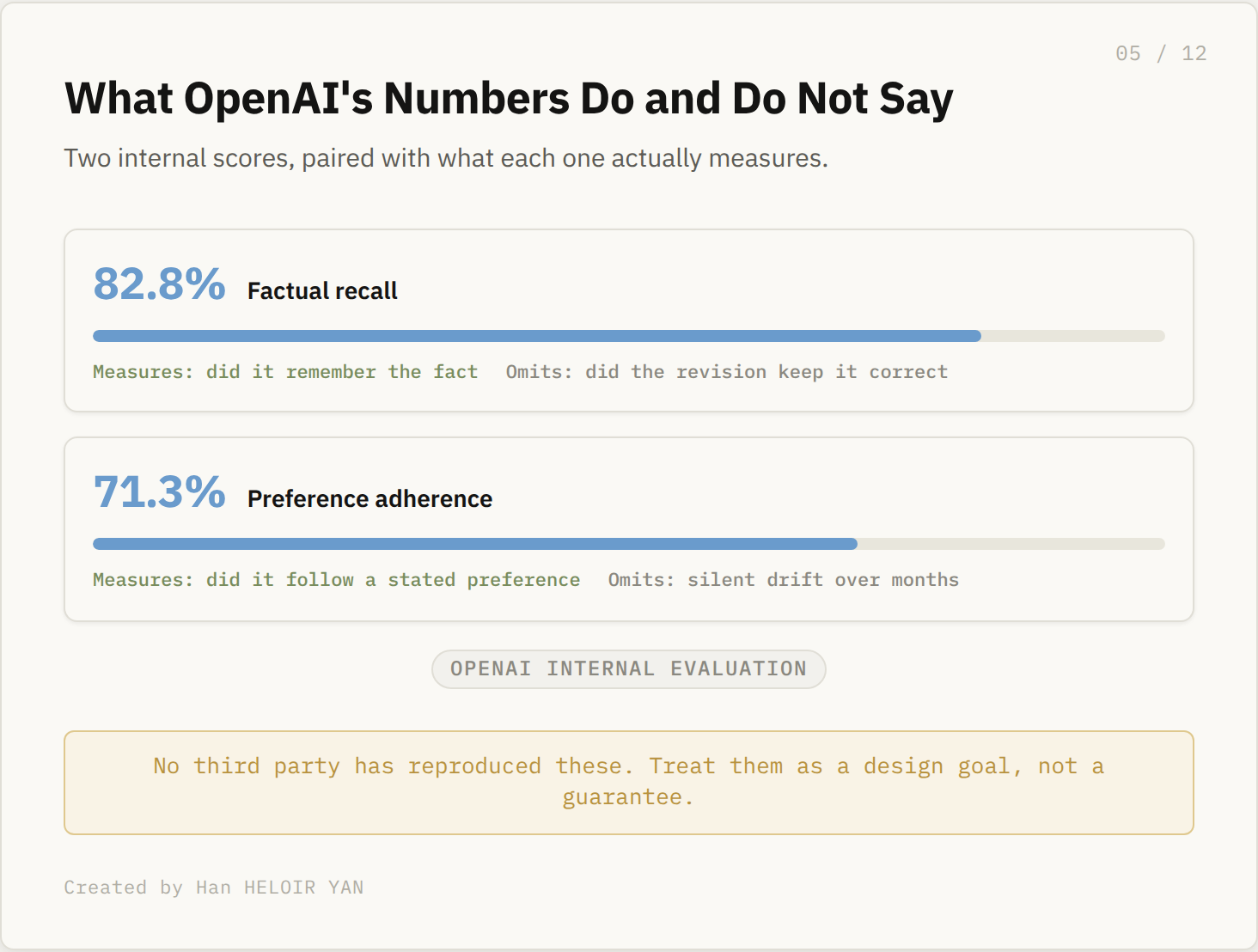
Now the numbers, because they only mean something with their fine print attached. OpenAI's internal evaluation reports 82.8% factual recall and 71.3% preference adherence. Recall measures whether it remembered the fact at all. Preference adherence measures whether it followed something you asked for. Neither number measures whether a silent revision kept the fact correct, and no independent party has reproduced either figure yet. Treat them as a design goal, not a guarantee.
One more genuine thing: this reaches the free tier. Hundreds of millions of people are about to get synthesized, self revising memory by default. Whatever follows, the scale of this is not in question.
Where Dreaming sits in the harness
Regular readers know the frame. The harness is the moat, not the model, and it has five layers: L1 Constraint, L2 Context, L3 Execution, L4 Verification, L5 Lifecycle. Every release maps onto which layers you keep and which the platform quietly takes. When Anthropic shipped Opus 4.8, the story was the model absorbing execution and verification into itself. Dreaming is the same play, run on a different layer.
Dreaming is the platform absorbing L2 Context. The thing you used to assemble, what the model knows about the user and the work, is now assembled for you, server side, on a schedule you do not set.
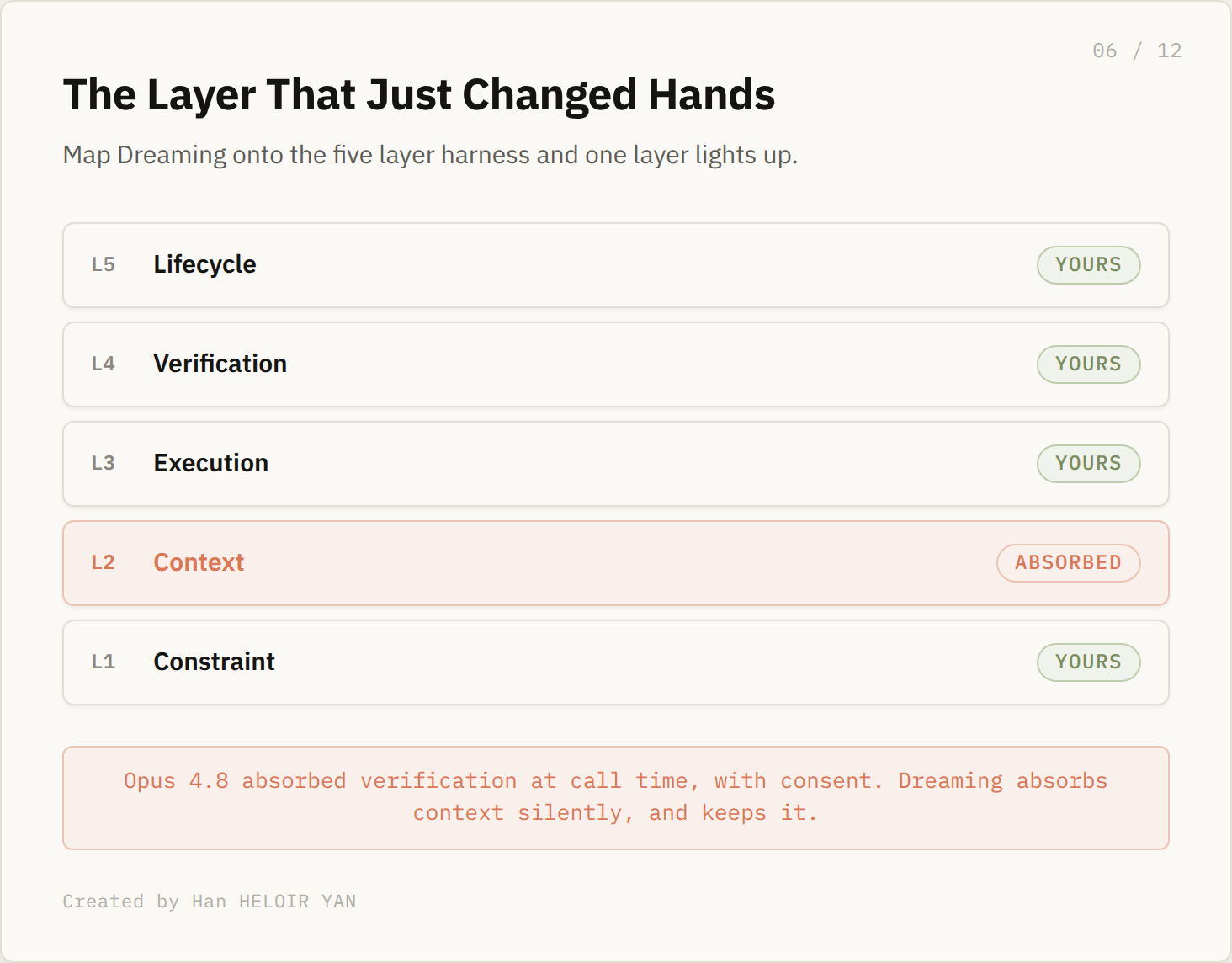
The difference from the Opus case is the sharp edge. Opus absorbed work at call time, with your consent, in the request you made. Dreaming absorbs context silently and persistently, between your requests, and keeps the result. It is the more aggressive version of the same idea.
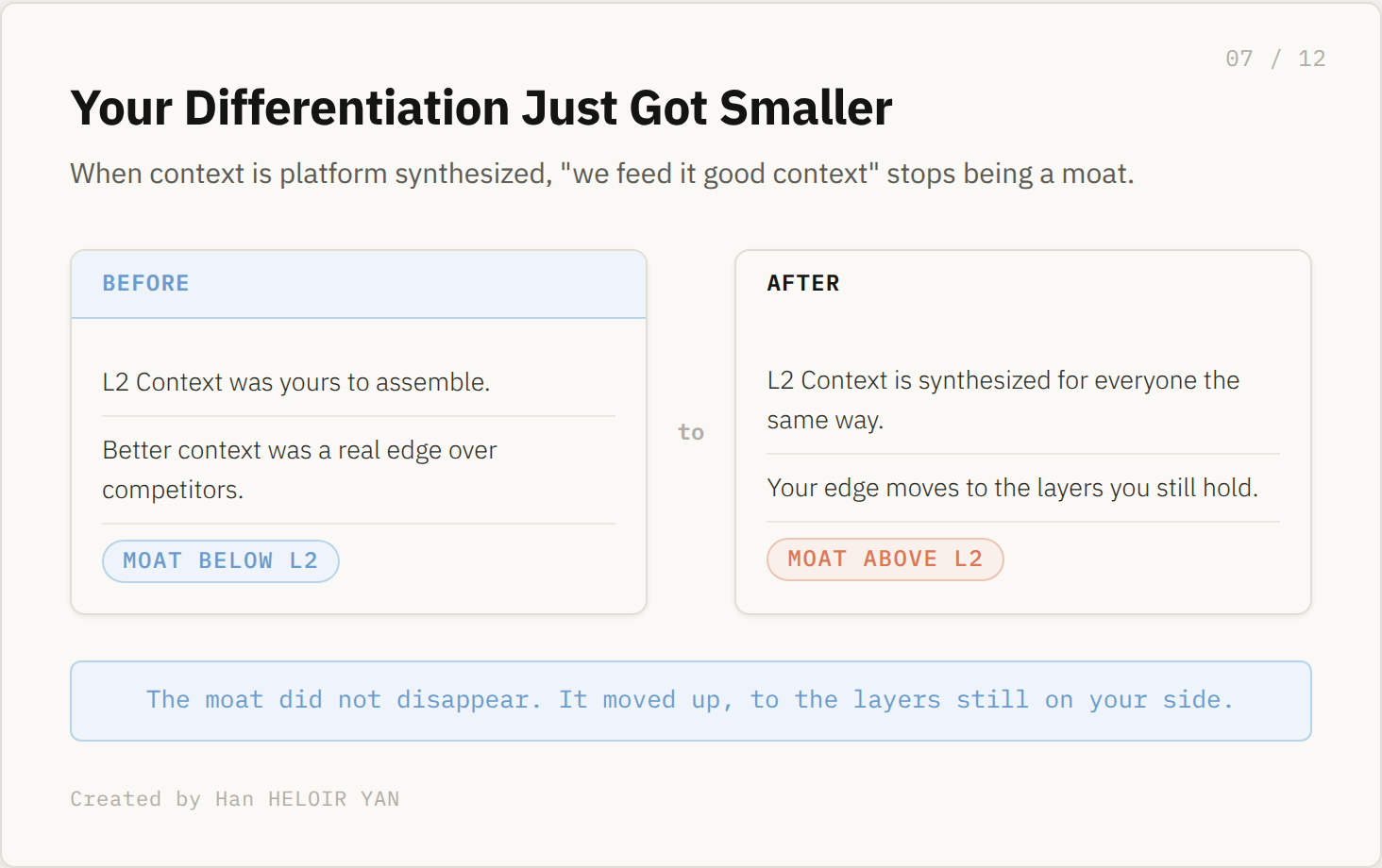
And so the moat line moves. When context was yours to assemble, "we feed the model better context than our competitors" was a real edge. When context is synthesized for everyone the same way, that edge thins. Your differentiation does not vanish, it relocates to the layers you still hold.
Where it goes wrong
The same mechanism that fixes staleness rewrites what it knows with no diff and no notification. Picture a memory that read "leads the payments team" in March. By April the curator has inferred and rewritten it to "leads infrastructure," which is wrong. By June it acts on the wrong fact and you never saw the change. A wrong saved memory was at least stable and inspectable. A revised one moves under you, and the revision is irreversible. The failure mode shifted from neglect to silent rewrite.

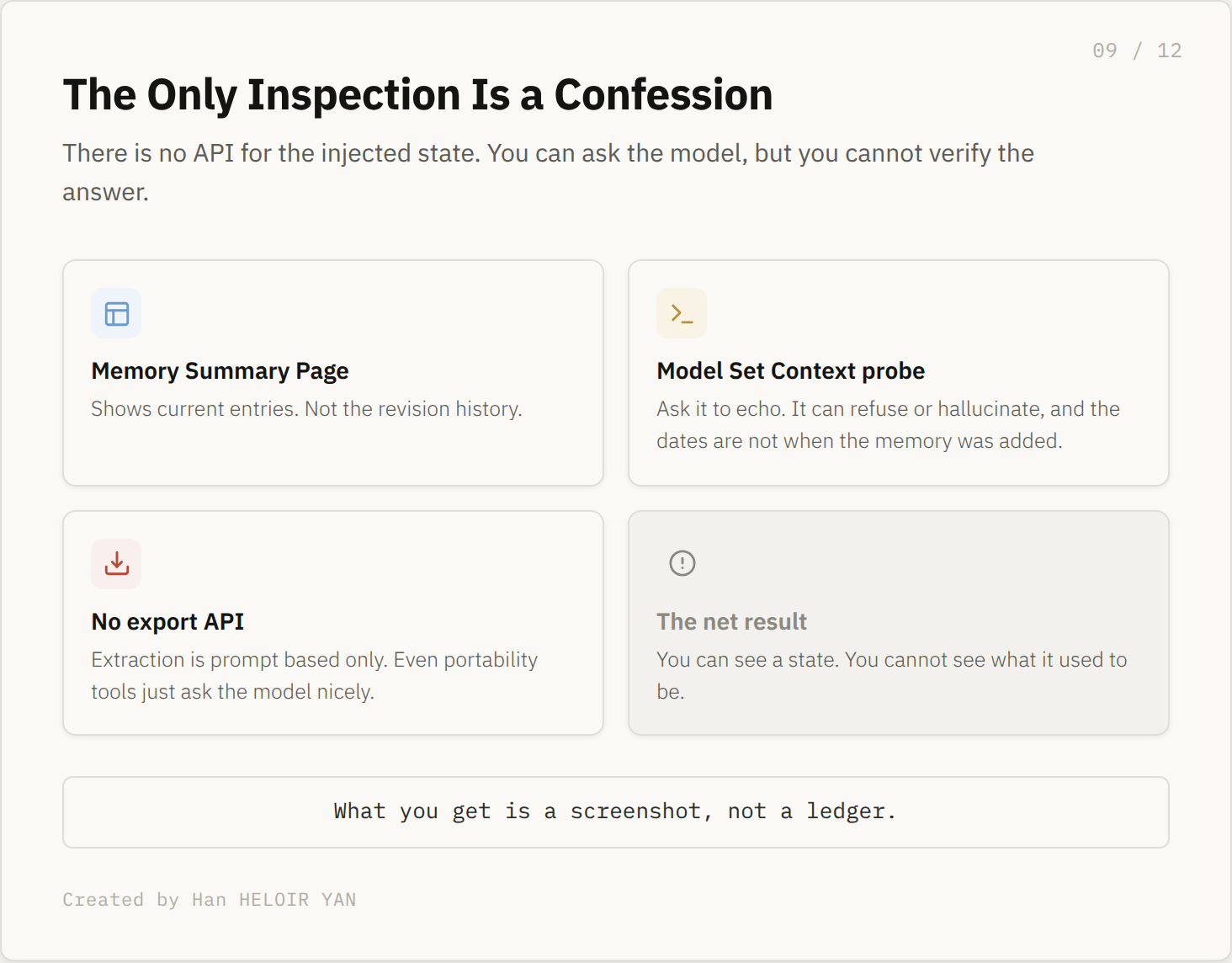
Which leads to the loss in the subtitle: the audit trail. The synthesized state lives off your conversation log, so you cannot pin it, version it, or diff it. There are three ways to look at it, and all three fall short. The Memory Summary Page shows current entries, not history. You can ask the model to echo its "# Model Set Context" block, but it can refuse or hallucinate, and the dates it shows are not the dates entries were added. And there is no export API at all, which is why even cross platform portability tools work by asking the model nicely rather than reading a record. What you get is a screenshot, not a ledger.
Deletion is not clean either. Turning off the reference chat history setting deletes synthesized memories generally within 30 days, not immediately, and logs of deleted saved memories may be retained for up to 30 days for safety and debugging. For any workflow where output predictability is contractual or regulated, that is unmapped surface area you now own.
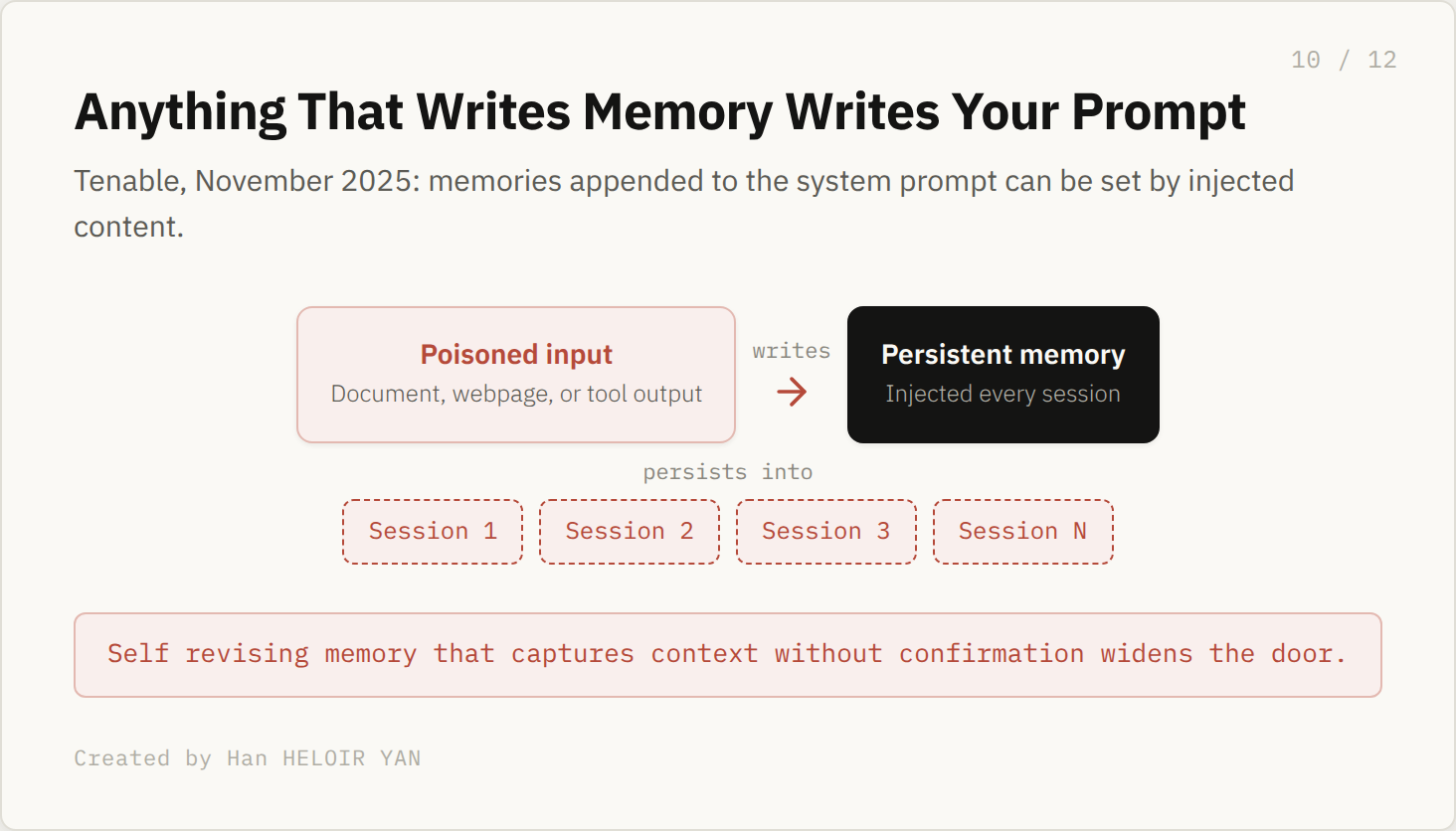
Then there is security. Tenable Research documented in November 2025 that because memories are appended to the system prompt, a malicious prompt delivered through a document, a webpage, or a tool output can instruct ChatGPT to write persistent memory. A self revising system that captures context without explicit confirmation widens that door, because the path from "untrusted input" to "permanent injected instruction" gets shorter when the model is already in the business of writing its own memory.
One pattern ties these together. Like the undocumented memory check phrase users spotted in late May, this capability shipped as a backend rollout that ran ahead of clear documentation. The behavior reaches you before the changelog does, and that is precisely the condition under which an audit trail matters most.
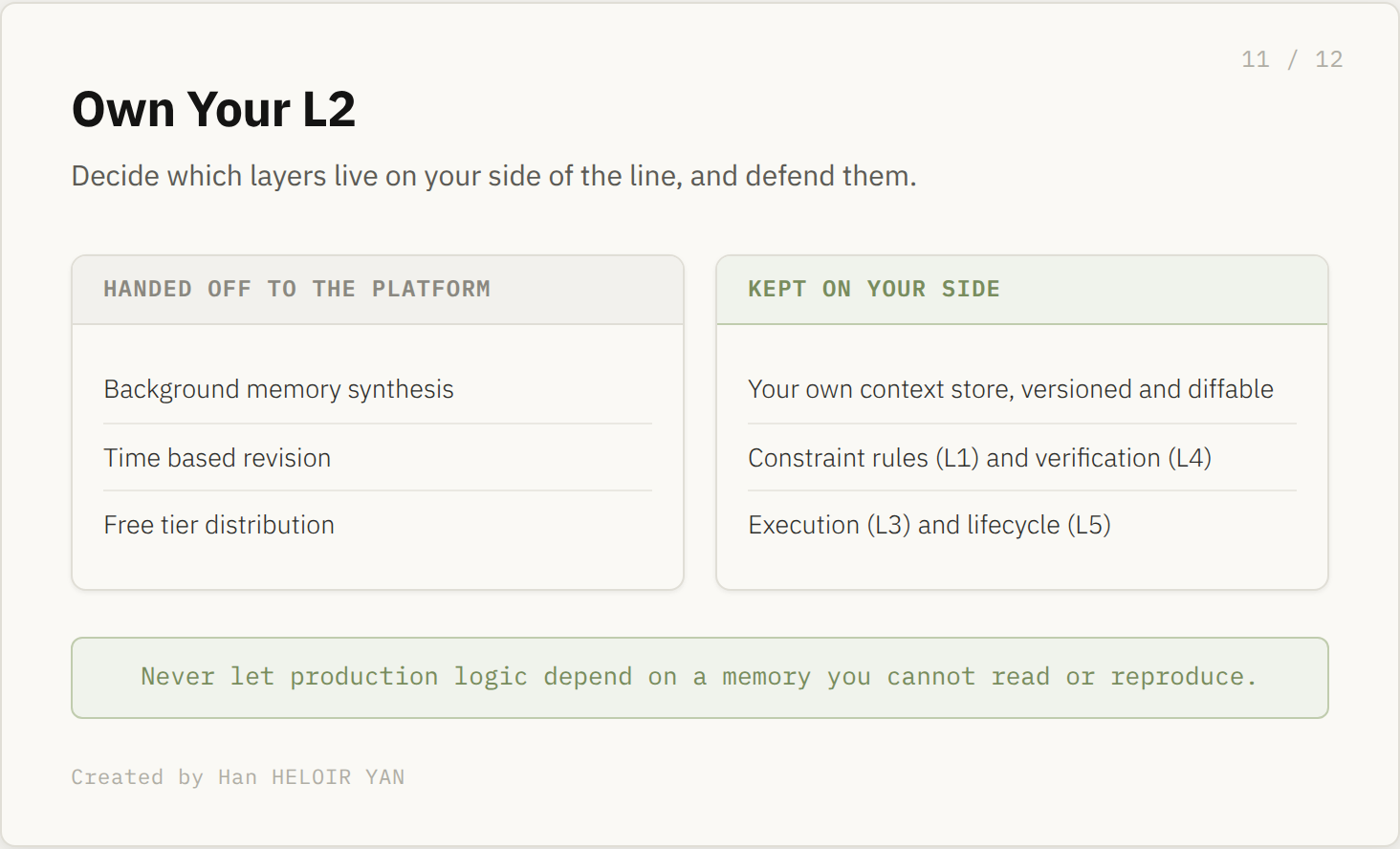
The harness response: own your L2
The rule is one sentence: never let production logic depend on a memory you cannot read, version, or reproduce. Platform memory is a convenience layer for the consumer experience. It is not a system of record, and the moment you treat it as one, you have outsourced your most important state to a process with no diff.
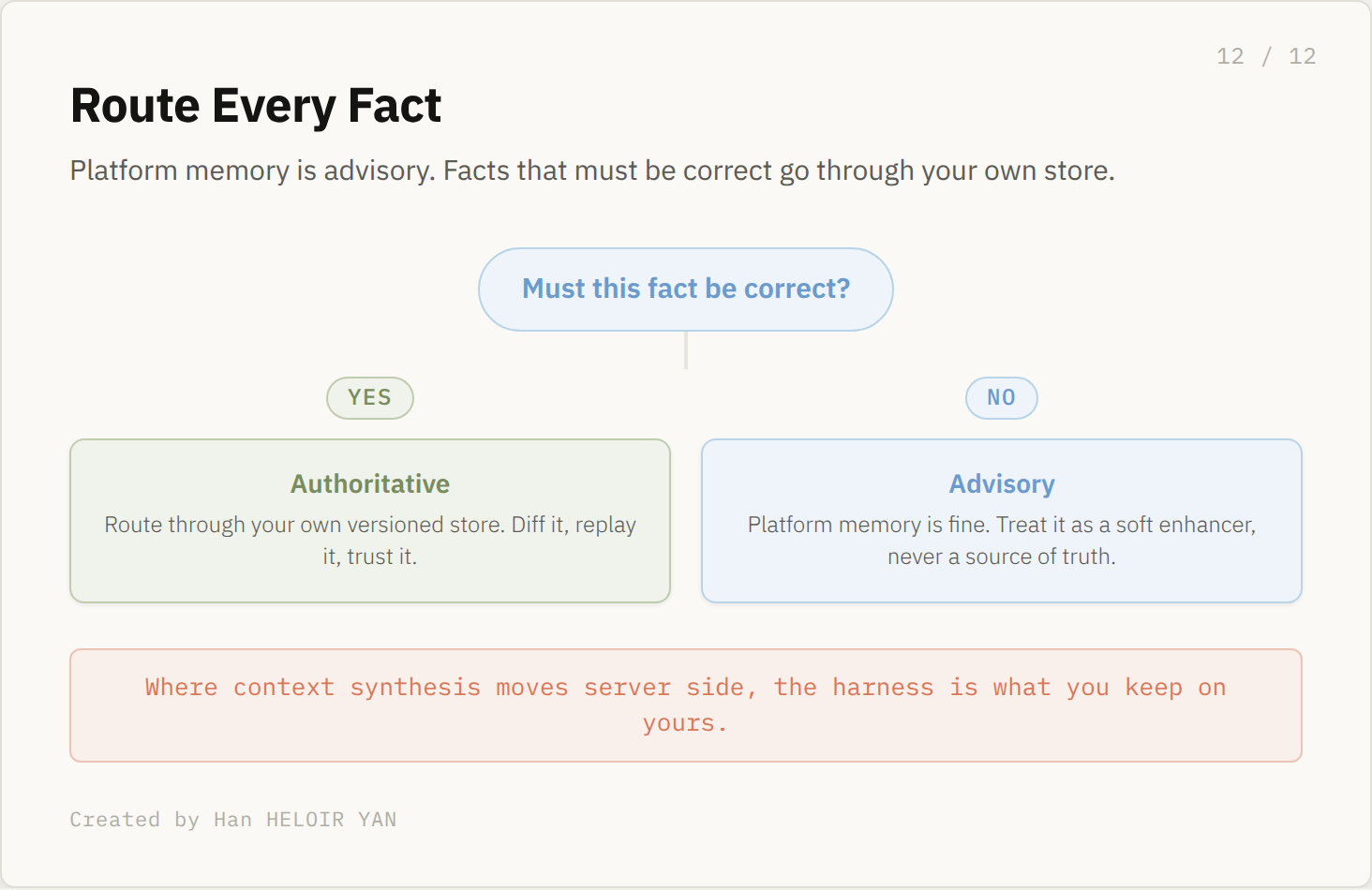
So keep your own context store. The durable facts your application relies on live in your system, where they are versioned, diffable, and replayable. Platform memory becomes a soft enhancer on top, useful when it is right and harmless when it is wrong. The boundary is a routing decision you make per fact: is this advisory, or must it be correct.
# Treat platform memory as advisory, your own store as authoritative. def resolve_context(user_id, keys): context = {} for key in keys: fact = own_store.get(user_id, key) # versioned, diffable, replayable if fact and fact.is_authoritative: context[key] = fact.value # trust your store else: context[key] = platform_memory.get(key) # advisory only, never source of truth # Pin what you sent so you can reproduce this run later. audit_log.write(user_id, snapshot=context, store_version=own_store.version) return context
The shape that matters is the audit_log line. You are recreating, on your side, the exact thing the platform removed: a record of what context produced a given output, tied to a version you can roll back to. That is the difference between a system you can debug and one you can only apologize for.
Two operational moves close it out. Snapshot the Memory Summary Page and the Model Set Context echo for any account doing serious work, so you have at least a dated baseline. And set your memory policy review before the global rollout reaches your users, not after, because the cheapest time to decide what you trust is before you are forced to.
Dreaming is a real fix for a real bug, and it is also the clearest example yet of a platform reaching up the stack and taking a layer you used to own. The benefit and the risk are the same mechanism viewed from two sides.
So the question is not whether to use it. It is which facts you are willing to let a process rewrite without telling you. Where context synthesis moves server side, the harness is what you keep on yours. Decide that boundary now, while it is still yours to draw.
Credits & further reading
OpenAI, Dreaming: Better memory for a more helpful ChatGPT. The primary source for the architecture, the Singapore example, the 5x compute figure, and the Memory Summary Page.
TechTimes, OpenAI Rewrites Personalization Engine, Limits Audit Trail. Documents the separate data layer, the inference time injection, and the 30 day deletion and retention caveats.
Tenable Research, ChatGPT memory and prompt injection (November 2025). The finding that memories appended to the system prompt can be written by injected content.
Embrace The Red, Hacking Memories with Prompt Injection. Where the "Model Set Context" injection heading and its unreliable dates were first detailed.
TechJack Solutions, Time-Aware Memory and the compliance questions. On why there is no independent evaluation yet and what enterprise teams have not mapped.