
The benchmark was innovative. The engineering was real. The model ID told a different story.
March 20, 2026. A developer named Fynn is poking at Cursor's API endpoint. He's not hunting for secrets. He's just debugging.
But the response comes back with a model identifier that isn't "Composer 2." It's kimi-k2p5-rl-0317-s515-fast.
He tweets it. 444,000 views.
The most carefully orchestrated model launch of the year (custom benchmarks, Pareto efficiency charts, a pricing strategy designed to undercut everyone) gets upstaged by the one string nobody thought to rename.
Eight days before Composer 2 launched, Cursor published something that deserved more attention than it got.
On March 11, the team released a detailed blog post introducing CursorBench, their internal evaluation framework for coding agents. Whatever you think about what happened later, this benchmark is genuinely innovative.
Public coding benchmarks are hitting a ceiling. Cursor's blog makes this case directly, and the argument is hard to dismiss:
CursorBench was built around real developer behavior. The key design choices:
For a benchmark designed to evaluate real-world coding agents, that's the right set of axes.

Then there's the engineering behind the model itself.
Cursor developed compaction-in-the-loop reinforcement learning. The idea: build context summarization directly into the RL training loop. When a generation hits a token-length trigger, the model pauses and compresses its own context to roughly 1,000 tokens (down from 5,000+ with traditional methods).
Because the RL reward covers the entire chain (including the summarization steps), the model learns which details matter and which to discard. The results, per Cursor's published research:
Credit where it's due: this is serious engineering work.
On March 19, Cursor put it all together. Composer 2 launched with a polished blog post, clean benchmark tables, and a pricing strategy that made the competitive landscape uncomfortable.
| Benchmark | Composer 1 | Composer 1.5 | Composer 2 |
|---|---|---|---|
| CursorBench | 38.0 | 44.2 | 61.3 |
| Terminal-Bench 2.0 | 40.0 | 47.9 | 61.7 |
| SWE-bench Multilingual | 56.9 | 65.9 | 73.7 |
On Terminal-Bench 2.0, Composer 2 beat Claude Opus 4.6's 58.0. It still trailed GPT-5.4's 75.1, but the pricing flipped the value equation: $0.50 per million input tokens, $2.50 per million output. That's 86% cheaper than Composer 1.5 and a fraction of what Anthropic and OpenAI charge.

The blog post attributed the gains to "our first continued pretraining run, which provides a far stronger base to scale our reinforcement learning." Technically accurate. No base model was named.
The Pareto chart placed Composer 2 exactly where you'd want it: high performance, low cost, optimal quadrant. Compared against GPT-5.4 (various configurations), Claude Opus 4.6, and Cursor's own previous models.
One model was conspicuously absent from every comparison chart across both the CursorBench blog and the Composer 2 launch: Kimi K2.5. The model Composer 2 was built on top of.
You don't benchmark against yourself. That's understandable. But in hindsight, the omission completes a picture of a launch carefully designed to avoid any mention of where the foundation came from.
The choreography was meticulous:
Everything was scripted. Everything except the API response.
Less than 24 hours. That's how long the carefully constructed narrative held.
On March 20, a developer named Fynn (@fynnso) was testing Cursor's OpenAI-compatible base URL when something unexpected appeared in the API response:
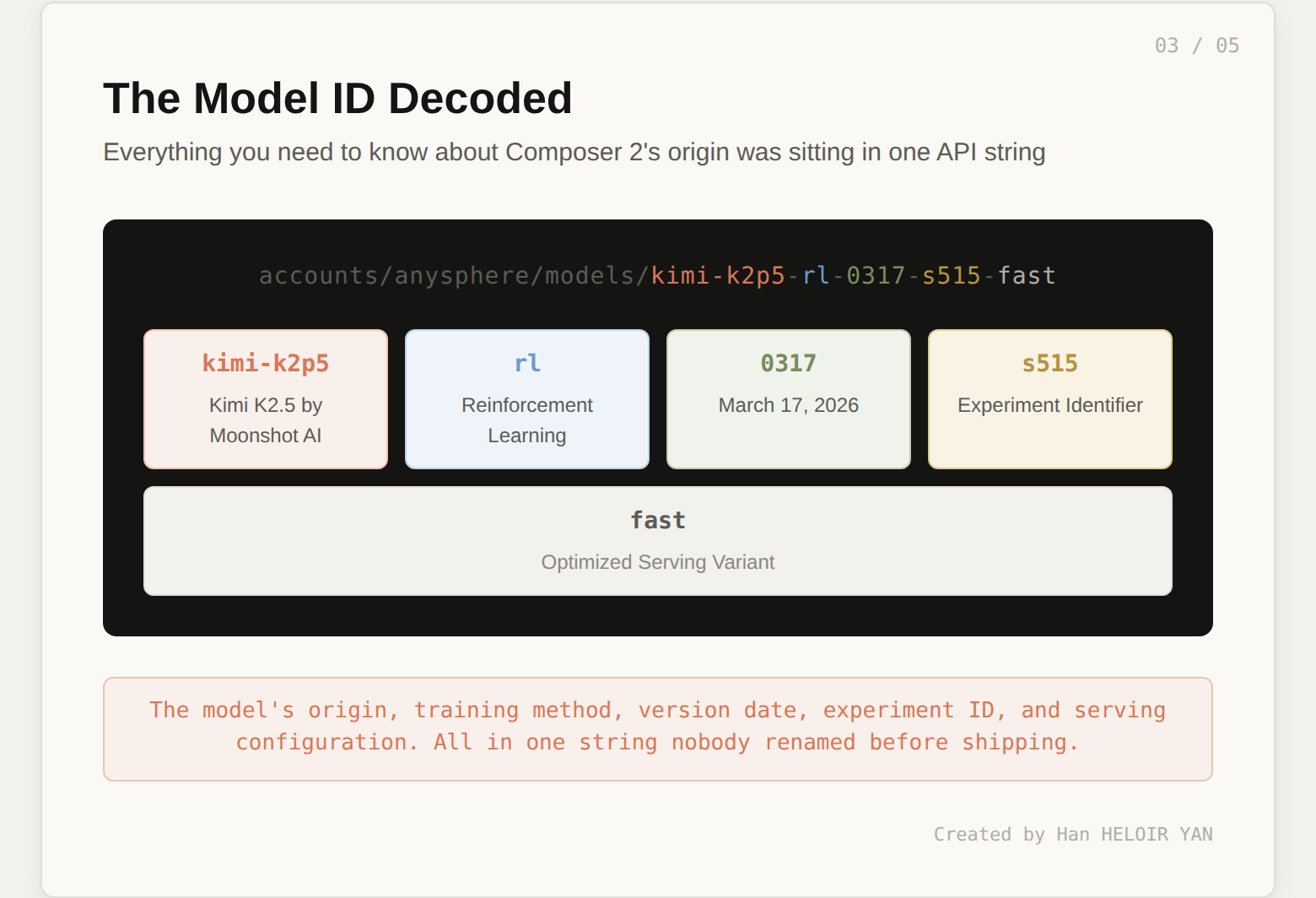
accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fastThat's not a Cursor model name. Let's decode it:
kimi-k2p5 : Kimi K2.5, Moonshot AI's open-weight modelrl : reinforcement learning (the post-training method)0317 : March 17, 2026 (likely the training date)s515 : internal experiment identifierfast : the optimized serving variantThe entire history of the model, its origin, its training method, its version, its serving configuration, sitting right there in a string that nobody thought to rename before shipping.
Fynn's comment was dry and perfect: "at least rename the model ID."
The tweet hit 444,000 views. Then things escalated.
Yulun Du, Head of Pretraining at Moonshot AI, moved fast. He ran Composer 2's tokenizer through analysis and posted his findings publicly: the tokenizer was identical to Kimi's. His conclusion: "almost certainly the result of further fine-tuning of our model."
Then he tagged Cursor co-founder Michael Truell directly, asking why Cursor wasn't respecting the license or paying fees.
Two other Moonshot employees confirmed the connection on social media. Then both deleted their posts. Internal communications, it seems, hadn't caught up with external communications.
This detail matters. It foreshadows what came next.
Kimi K2.5 is released under a Modified MIT License. Standard MIT is one of the most permissive open-source licenses available. Moonshot added one critical clause:
If the Software (or any derivative works thereof) is used for any of your commercial products or services that have more than 100 million monthly active users, or more than 20 million US dollars in monthly revenue, you shall prominently display "Kimi K2.5" on the user interface of such product or service.
The math on Cursor:
The license was written precisely for this scenario. Moonshot anticipated that companies would fine-tune Kimi K2.5 and ship it under their own brand. The attribution clause was designed to ensure the origin model still gets credit, even after modification.
Cursor's interface said "Composer 2." No Kimi anywhere.
Hours of silence.
Then Lee Robinson, a developer at Cursor, posted the first acknowledgment on X. The progression tells its own story:
The community noticed the sequence: first minimize, then acknowledge only when forced. Not a great look for a company that had plenty of good news to share.
The engineering was strong. The benchmark results were legitimate. Naming the base model would have cost Cursor nothing technically. It might have actually strengthened the narrative: "We took the best open-source coding model in the world and made it dramatically better." That's a compelling story.
Instead, the omission created a trust gap that the internet filled with the worst possible interpretation.
And then came the twist nobody expected.
Kimi's official account posted a congratulatory message to Cursor. The tone was warm, supportive, and completely at odds with what Moonshot's pretraining lead had posted hours earlier:
"Congrats to the @cursor_ai team on the launch of Composer 2! We are proud to see Kimi-k2.5 provide the foundation."
The statement confirmed that Cursor accesses Kimi K2.5 through Fireworks AI's hosted RL and inference platform as part of an authorized commercial partnership.
Read that again. Authorized commercial partnership.
The deal existed the whole time. Moonshot's own pretraining lead didn't know about it when he posted his accusation. Internal coordination failure on both sides: Cursor didn't disclose the base model publicly, and Moonshot's commercial team apparently didn't brief their technical leadership about the partnership before the launch.
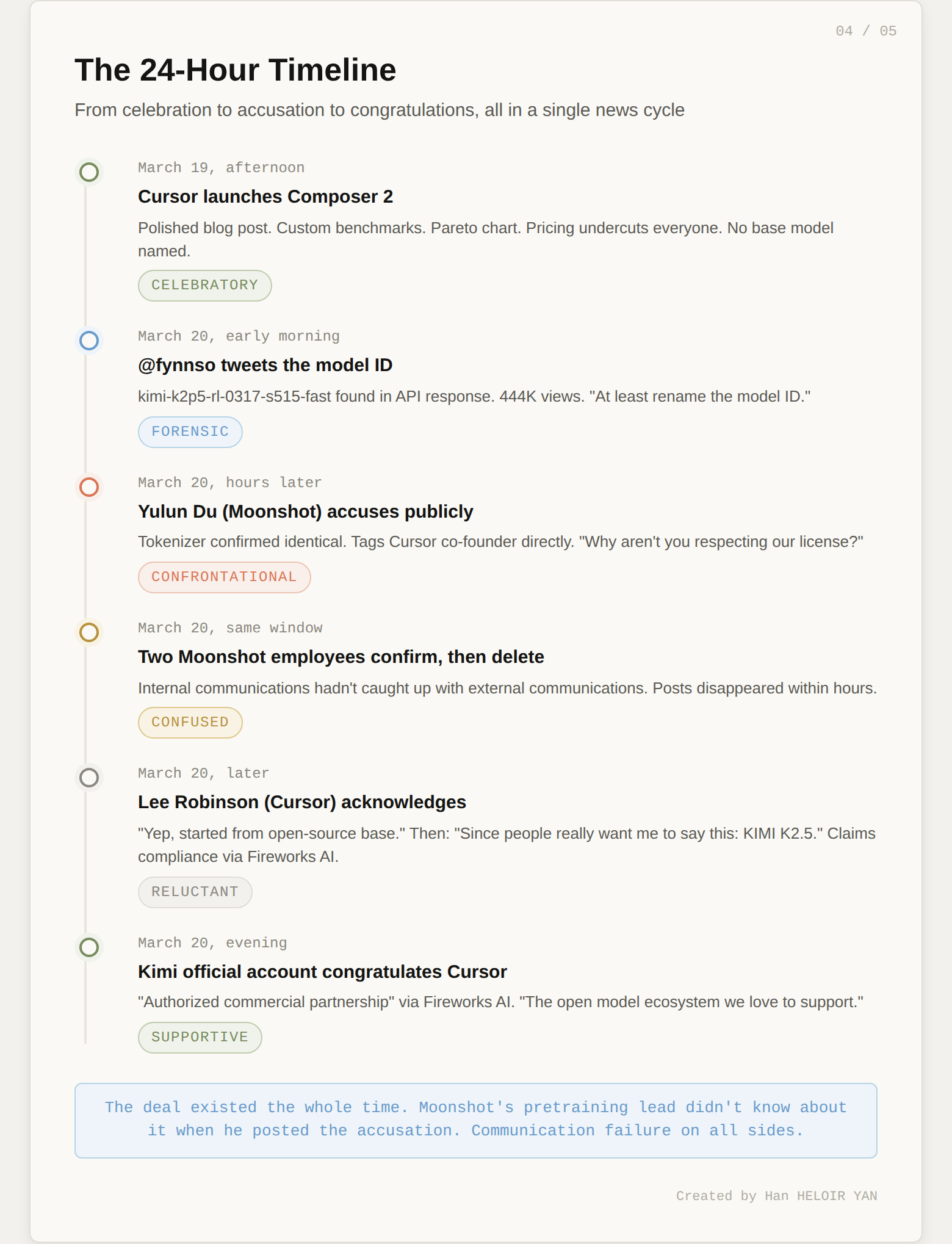
From accusation to congratulations in under 24 hours. The drama was real. The underlying business relationship was fine. The communication on all sides was a mess.
A forgotten model ID string is a good story. But it's not the real story.
The real story is that this pattern is everywhere, and Cursor just happened to be the one that got caught on a Wednesday night.
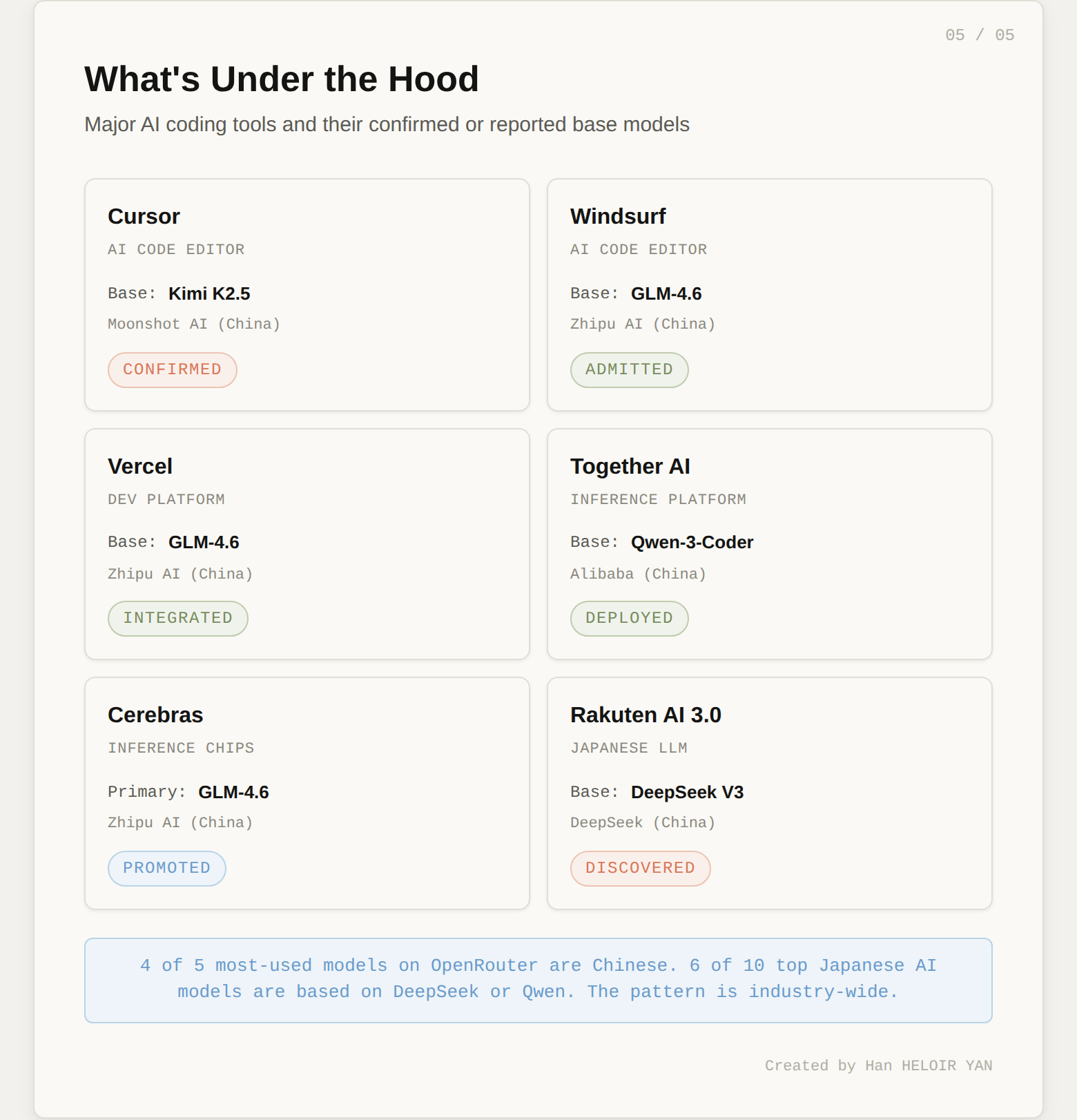
Cursor isn't an outlier. It's the norm.
The numbers tell the same story from a different angle. On OpenRouter, four of the five most-used models globally are Chinese. Chinese model usage exceeded US model usage for two consecutive weeks in early March 2026. On the agent leaderboard, Kimi, GLM, and Qwen all rank in the top tier.
Chamath Palihapitiya, founder of Social Capital, said it plainly: "We have started using Kimi-K2 on Groq. Although the models of OpenAI and Anthropic perform well, they are simply too expensive."
Performance plus cost. That's the entire explanation. Nobody's making this choice for ideological reasons. They're making it because Chinese open-source models are competitive at the frontier and priced for volume.
If the engineering rationale is so straightforward, why is every company so allergic to naming the base model? Three reasons:
Investor optics. Cursor is valued at $29.3 billion. That valuation is partly built on the narrative of proprietary AI capability. Saying "we took an open-source model and made it better" is a different pitch than "we built our own model." Both are valid. One sounds more like a $29 billion company.
Geopolitical awkwardness. "Powered by Chinese AI" is not a talking point any American company wants on its landing page. Not in the current political climate. The fact that six of ten top Japanese AI models are also based on DeepSeek or Qwen shows this isn't a US-only discomfort. Nobody wants to explain this to their enterprise customers.
The value proposition shift. If the base model is open-source and anyone can fine-tune it, the competitive moat isn't the model. It's the UX, the agent workflow, the tool integration, the RL training pipeline. That's a harder story to tell than "we built our own AI." Cursor's compaction-in-the-loop RL, their Cursor Blame evaluation system, their co-designed training infrastructure: that's real differentiation. But it takes paragraphs to explain, not a tagline.
The irony is that transparency would actually strengthen Cursor's position. "We took the best open-weight coding model available, invested 75% of our compute budget in continued pretraining and RL, and built a product that beats Claude Opus 4.6 at one-tenth the price." That's a story worth telling. It positions the engineering as the value, not the base weights.
Cursor claims compliance through "inference partner terms" with Fireworks AI. The argument seems to be that the license obligation is satisfied at the infrastructure level rather than in Cursor's own user interface.
Whether that interpretation holds is an open question. The license says "prominently display 'Kimi K2.5' on the user interface of such product or service." Cursor's user interface says "Composer 2." A reasonable person could read those two facts and see a gap.
This matters beyond one company. Open-weight model licensing is still being tested in real-world, high-stakes situations. If Moonshot doesn't enforce the attribution clause against a company generating $2 billion in annual revenue from their model, the clause becomes decorative. Every future open-weight license with a similar provision loses credibility.
The precedent cuts both ways:
The Moonshot pivot from accusation to congratulations suggests this will resolve quietly. That's probably the right business outcome. But it's the wrong signal for the open-source ecosystem.
Three takeaways:
Maybe the real benchmark isn't CursorBench or Terminal-Bench. It's whether your model ID survives a curious developer with an API debugger on a Wednesday night.
Han HELOIR YAN, Ph.D. · 2026