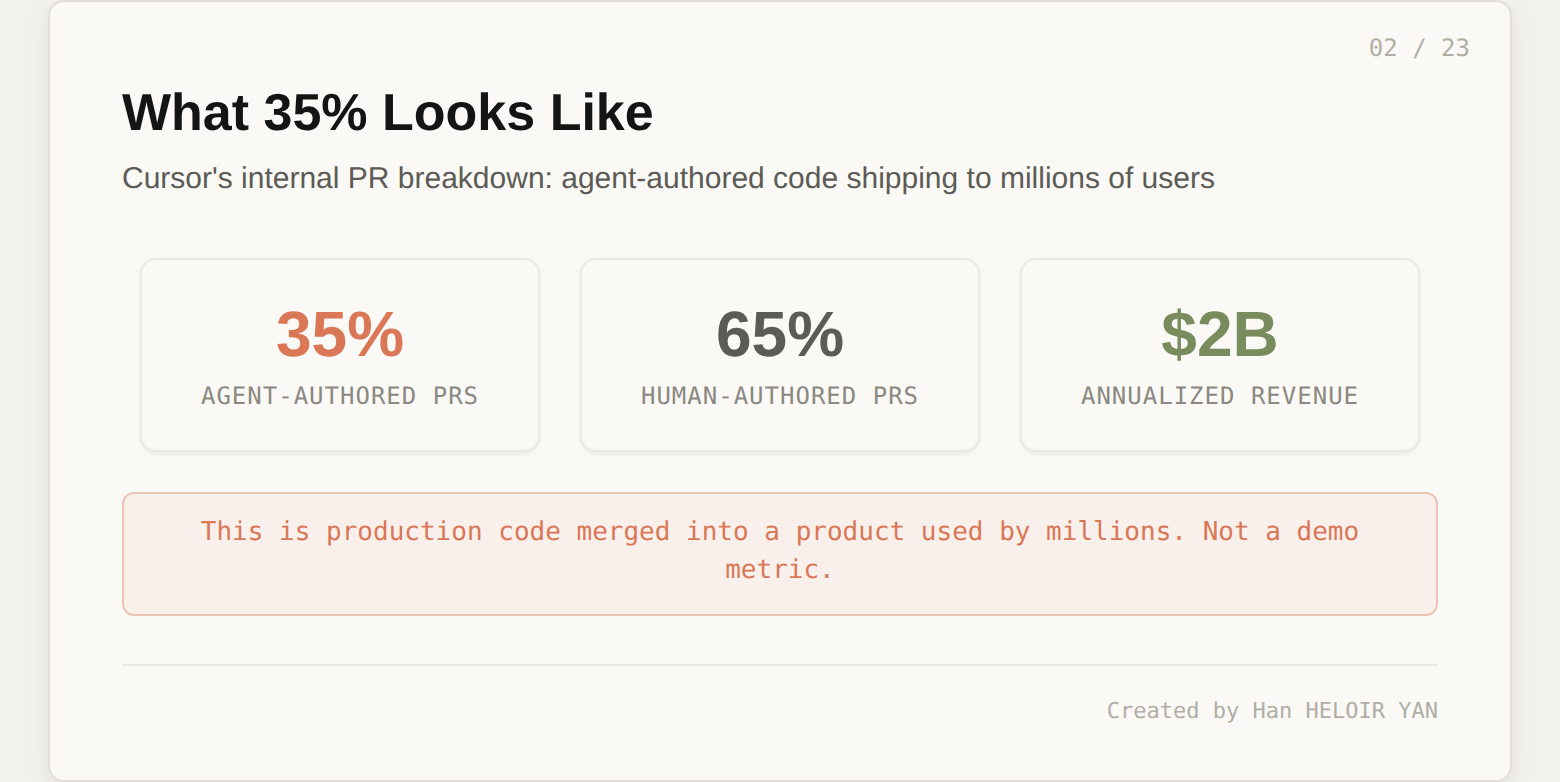
Your AI coding assistant just shipped a PR while you were on the train. It attached a video of itself clicking through the UI to prove the feature works. It resolved its own merge conflicts and squashed to a single commit. This is not a demo. 35% of Cursor's own merged pull requests are now produced this way. But here's what most engineers miss when they look at this: the model inside that agent (GPT-5, Claude, Gemini) is the least interesting part of the stack. What makes it work is everything around the model: VM isolation, codebase onboarding, parallel orchestration, video artifact capture, and multi-model routing. Cursor calls it a cloud agent. The more precise term is a harness.
If this helps you ship better AI systems:
👏 Clap 50 times (yes, you can!) — Medium's algorithm favors this, increasing visibility to others who then discover the article.
🔔 Follow me on Medium, LinkedIn and subscribe to get my latest article.
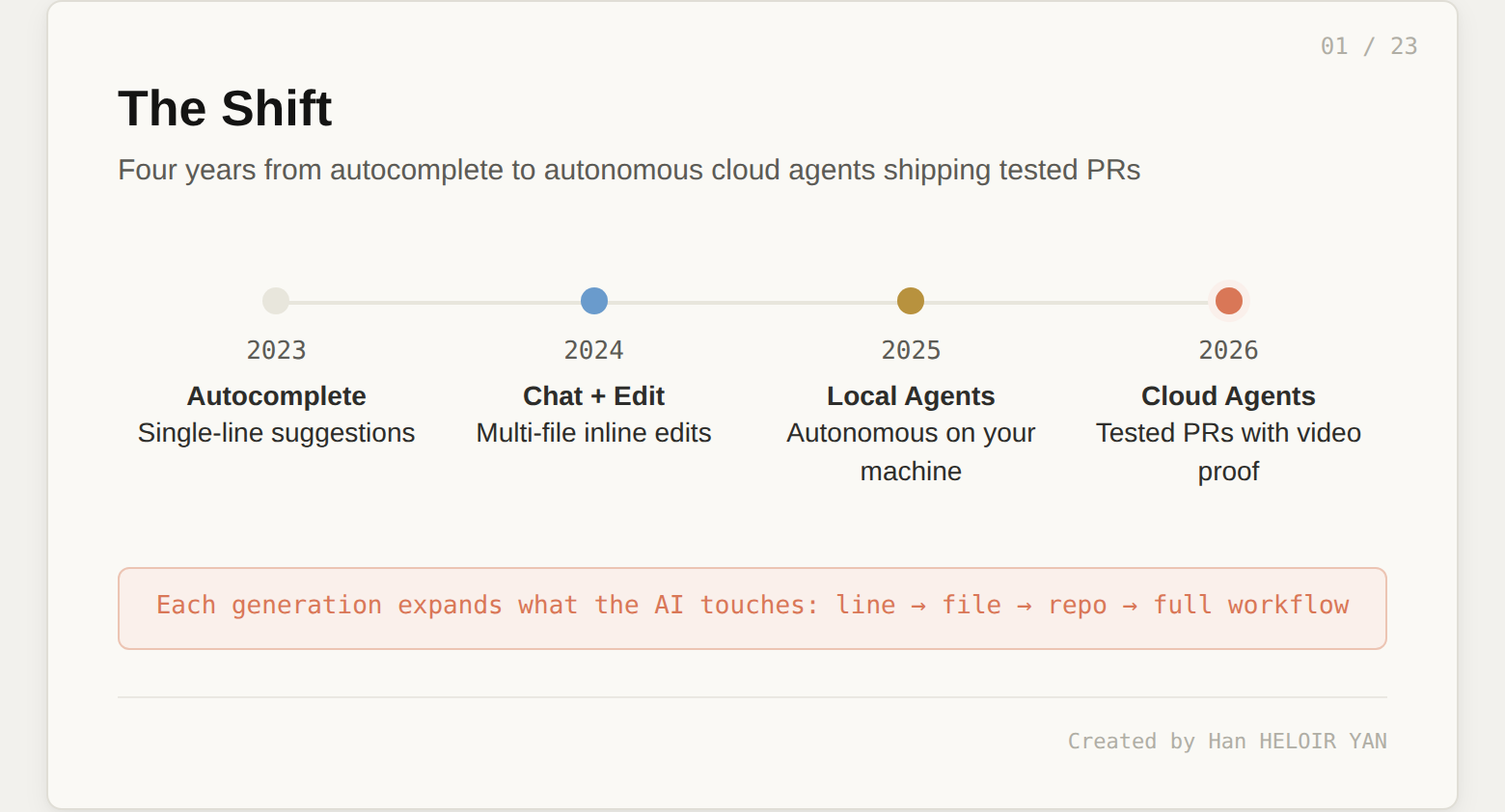
The shift from "AI suggests code" to "AI ships tested features end to end" is happening right now, and it is happening faster than most engineering teams expected. In October 2025, Cursor launched cloud agents as background workers. By February 2026, those agents could control their own computers: opening browsers, clicking through UIs, and recording video proof of their work. By April 2026, Cursor 3 tore out the chat panel entirely and rebuilt the IDE around an Agents Window where developers dispatch and monitor autonomous tasks like a project manager reviewing work.
This matters beyond Cursor because the harness pattern is emerging everywhere. Claude Code ships background agents with worktree isolation. OpenAI Codex runs sandboxed tasks from GitHub issues. GitHub Copilot added its own coding agent. Every tool converges on the same promise: the AI works while you do something else. But the implementations are radically different. Understanding Cursor's harness teaches you how to evaluate all of them, because the differentiator is never the model. It is always the infrastructure wrapped around it.
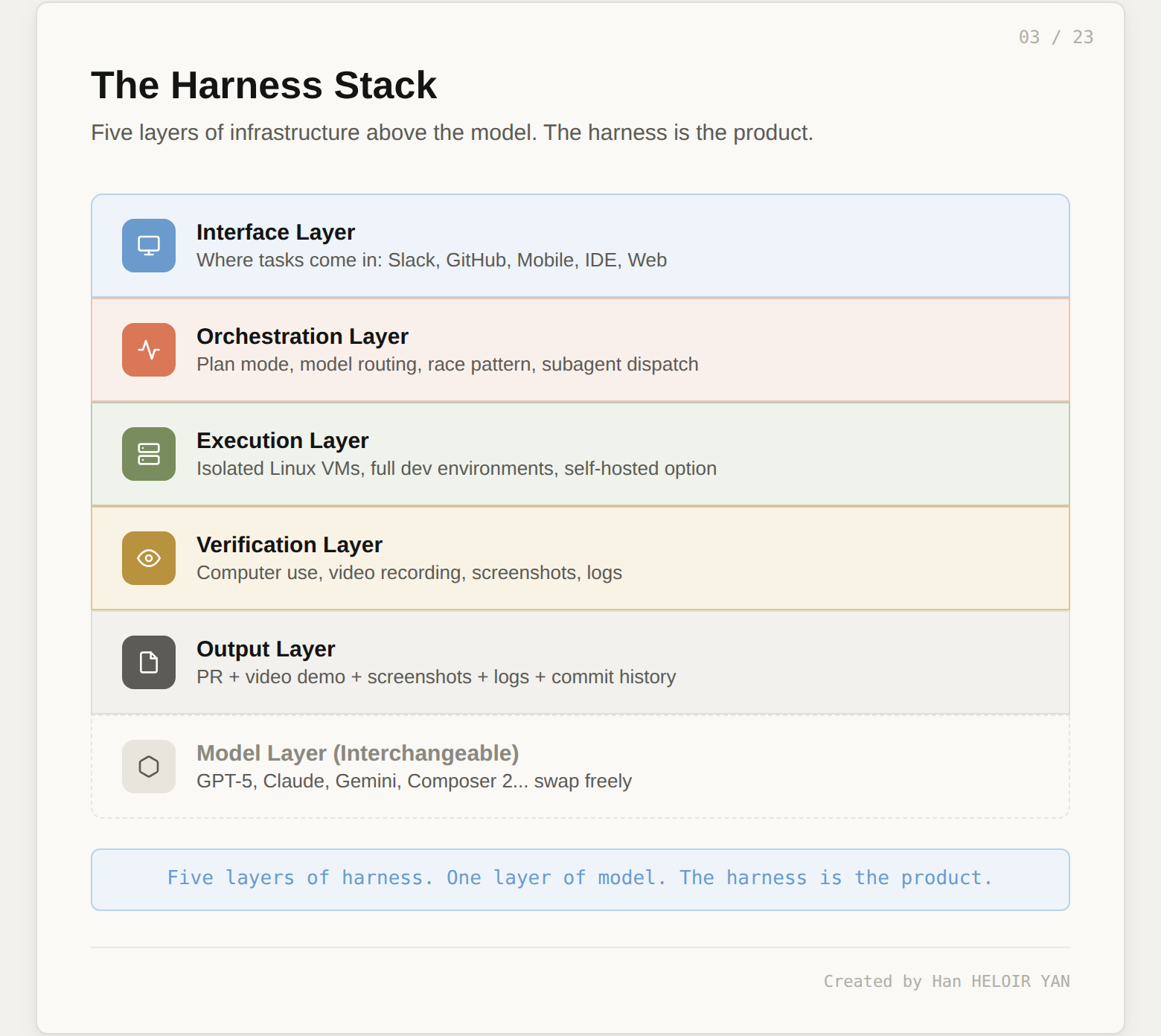
You do not buy a car for the engine alone. You buy it for the chassis, the suspension, the transmission, the safety systems, and the dashboard that ties them together. The engine is interchangeable: swap a V6 for an electric motor, and the car still drives. Same with cloud agents. The LLM is one component at the bottom of the stack. The harness is everything above it that makes raw model capability useful for shipping code.
Cursor's harness has five layers. At the top sits the interface layer: where tasks come in (Slack, GitHub, mobile, IDE). Below that, the orchestration layer: how work gets planned, which model gets picked, and how many agents run in parallel. Then the execution layer: where code actually runs (isolated VMs, not your laptop). Then the verification layer: how the agent proves its output works (computer use, video, screenshots, logs). And finally the output layer: what the developer receives (a PR with artifacts, not a chat message).
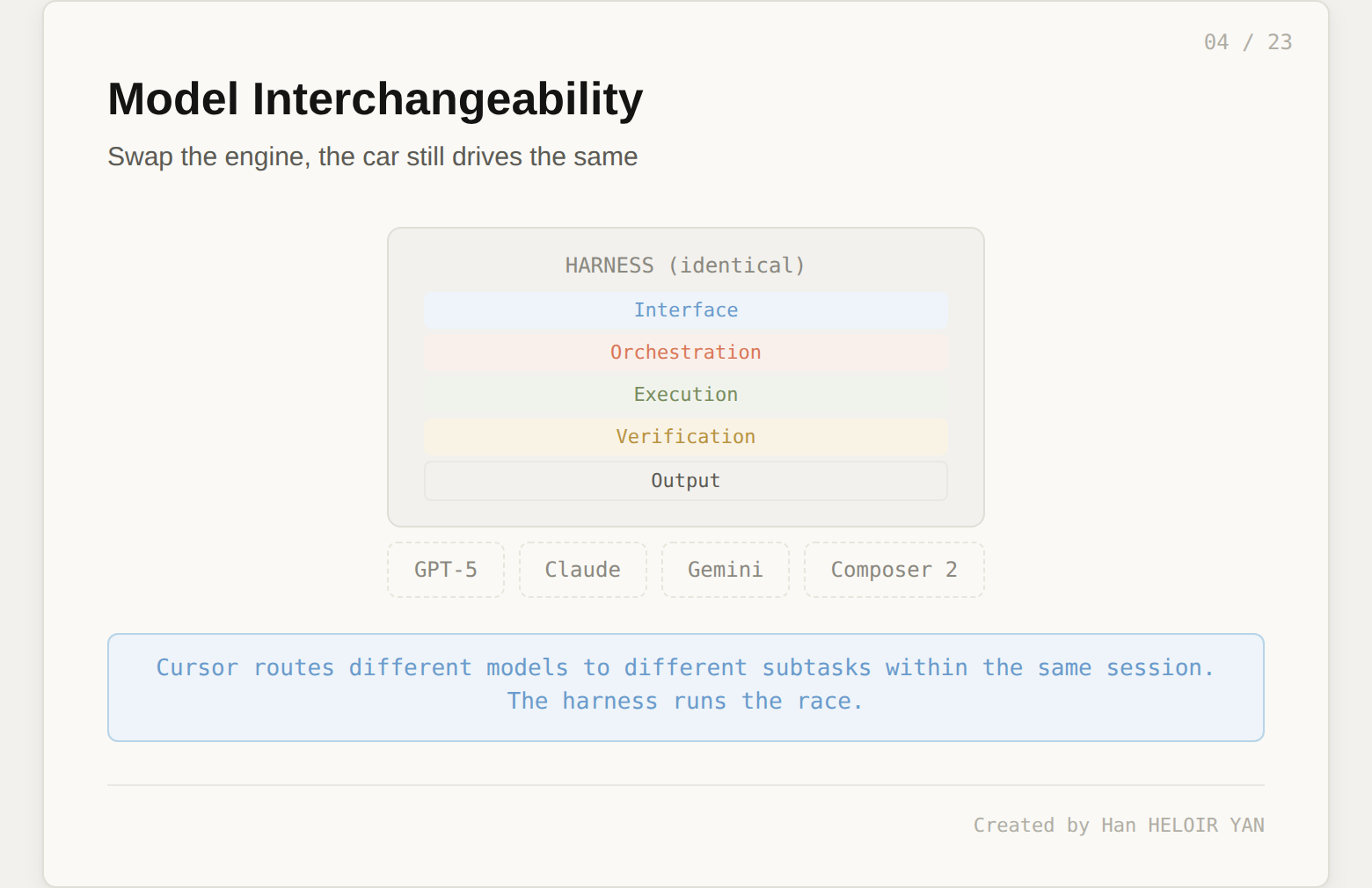
The model sits below all five layers. You can swap GPT-5 for Claude for Gemini for Composer 2, and the harness behaves identically. This is not a theoretical claim. Cursor literally does this: it routes different models to different subtasks within the same agent session, and it runs the same task against multiple models in parallel to pick the best result. The model is the engine. The harness is the car. And Cursor's $29.3B valuation is a valuation of the car.
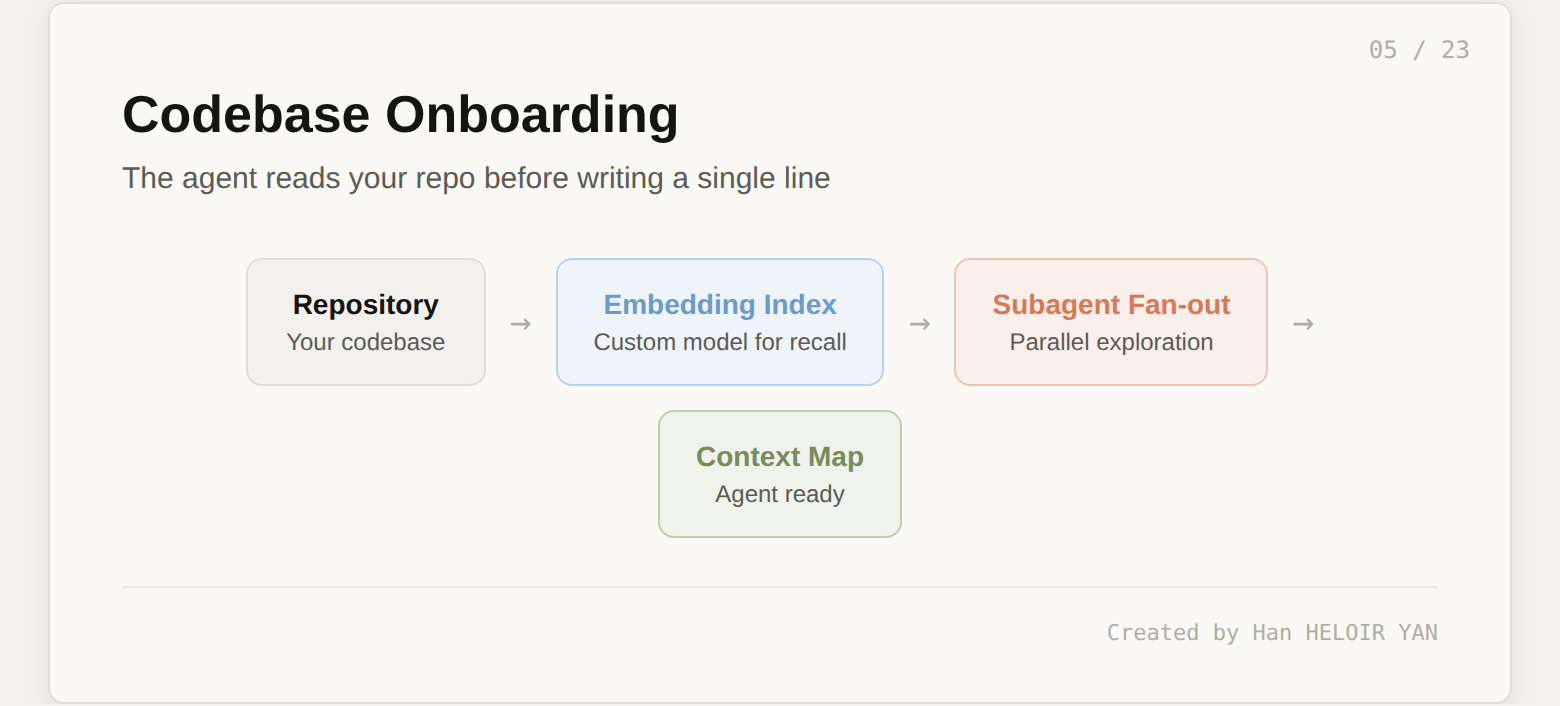
The agent reads your repo before writing a single line of code. Cursor built a custom embedding model specifically for codebase recall across large repositories. When a cloud agent starts, subagents fan out in parallel to explore different parts of the codebase, each using the model best suited for that subtask. One subagent might index the frontend component tree while another maps the API routes and a third reads the database schema. The result is a context map that gives the agent working knowledge of your project before it touches any files.
For new repos, you can kick off onboarding at cursor.com/onboard. The agent configures its own environment, installs dependencies, and records a demo video of the working application. You watch the demo to verify the agent understood your project correctly. This is not a README parser. It is an active exploration of your codebase that produces a verified baseline.

Each cloud agent gets its own isolated Linux VM with a full development environment: file system, terminal, browser, running application instance. Your laptop is not involved. There is no resource competition between agents, and there is no resource competition between agents and you. This isolation is what makes parallelism possible. You can run 10 to 20 agents simultaneously, each in its own sandbox, each working a completely different task on a completely different branch.
Before cloud agents, local agent mode meant your machine was doing double duty: running your editor, running the agent, and running the application being tested. Three agents on one laptop meant memory pressure, port conflicts, and a fan noise that sounded like a jet engine. Cloud VMs eliminate all of that. Each agent gets a clean environment that cannot interfere with anything else.
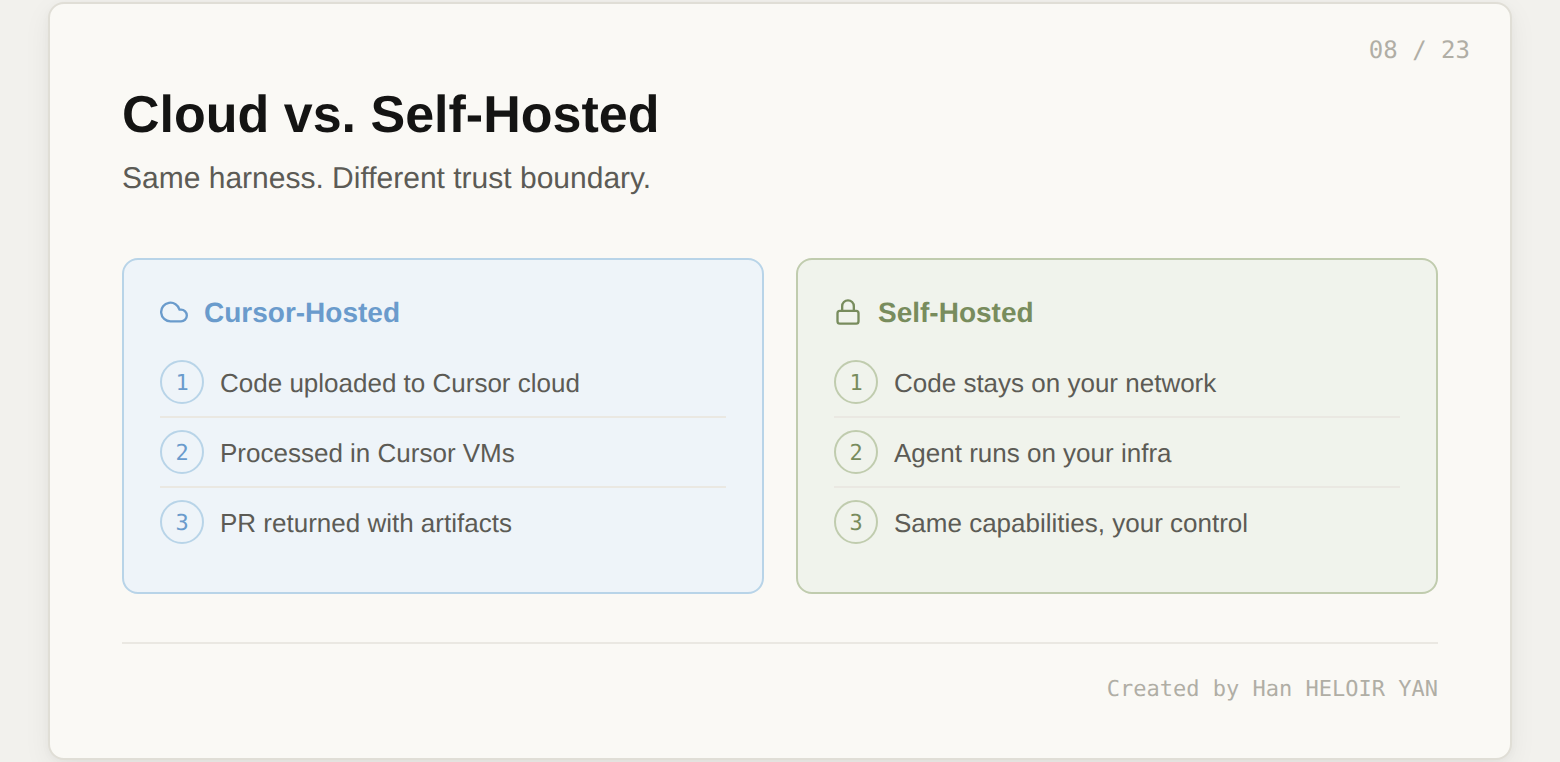
In March 2026, Cursor shipped self-hosted cloud agents for enterprise teams. Same capabilities: isolated VMs, full dev environments, multi-model harnesses, plugins. The difference is that your codebase, build outputs, and secrets never leave your network. The agent handles tool calls locally on your infrastructure. Same harness, different trust boundary.

Cursor's workflow for complex features splits into two phases. First, you iterate locally with a model to create a detailed plan: what the feature should do, which files it touches, what the acceptance criteria look like. Once the plan is solid, you send it to a cloud agent for implementation. You move on to your next task. The agent works in the background, following the plan you agreed on.
Model routing happens at the harness level, not the developer level. Cursor picks the best model for each subtask based on the task type and complexity. The GPT-5 Codex agent harness was specifically revamped for long time horizons in the cloud. Claude handles reasoning-heavy subtasks. Gemini processes large context windows efficiently. Composer 2, Cursor's own model trained with reinforcement learning from user interactions, handles routine coding with strong results on challenging tasks.
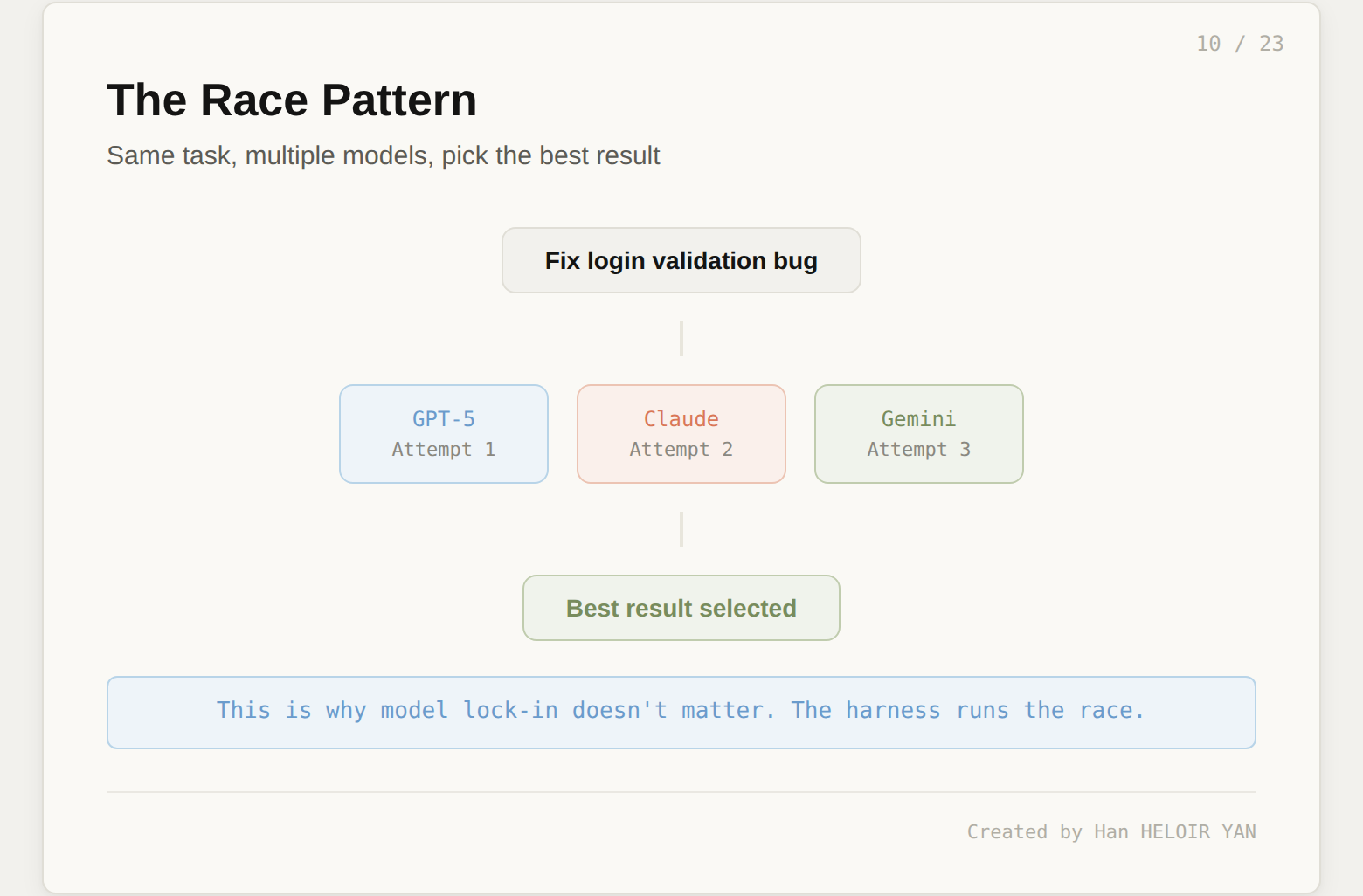
The most interesting orchestration pattern is the race. Cursor dispatches the same problem to multiple models in parallel and picks the best result. The team reports this significantly improves final output quality, especially for harder bugs that require a handful of precise changes. This is why model lock-in does not matter at the harness level. The harness runs the race. The models are contestants.

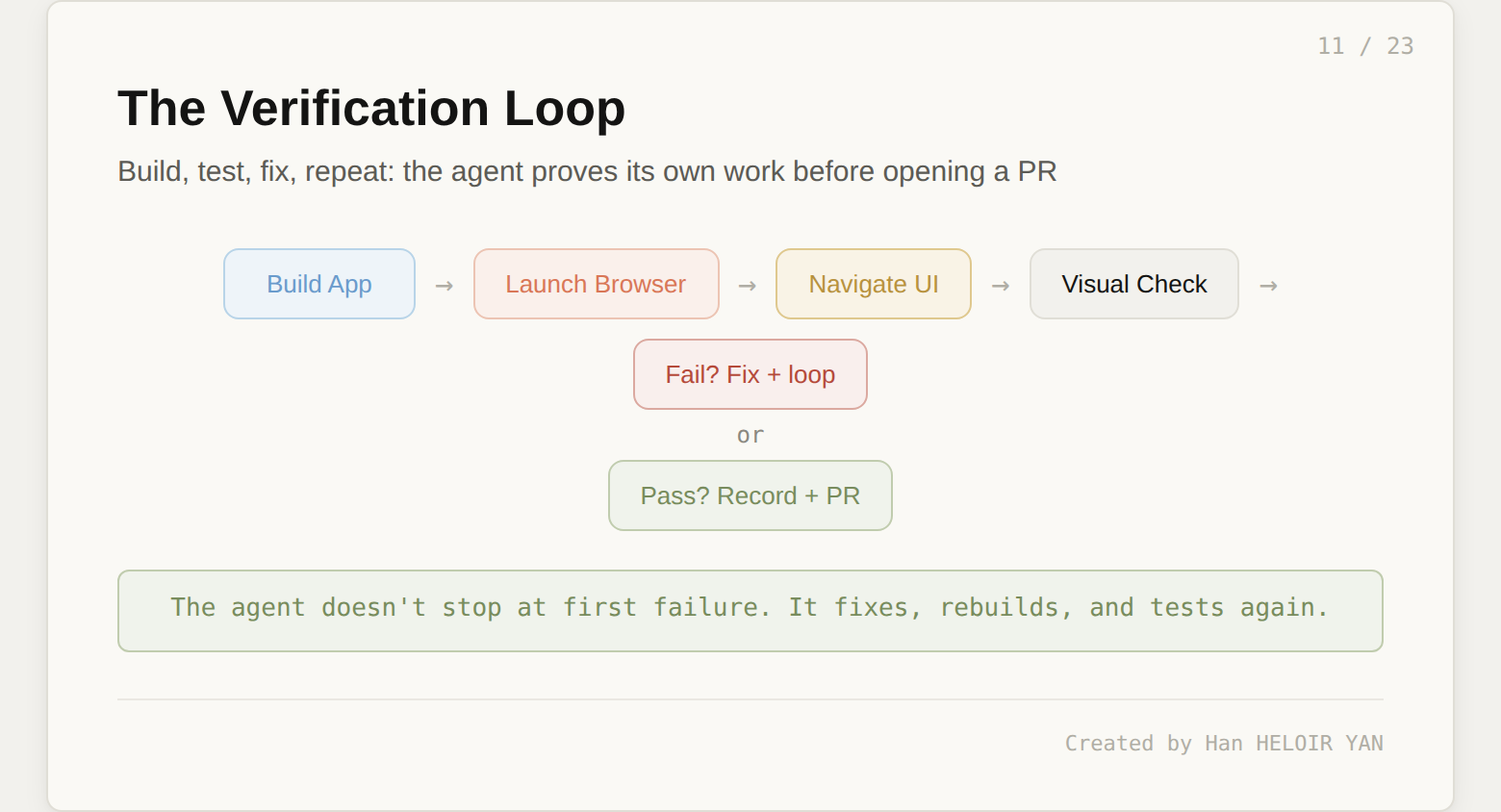
On February 24, 2026, Cursor shipped the capability that separates cloud agents from everything that came before. Agents can now use the software they create. Each VM includes a browser. The agent builds the application, launches it, navigates to localhost, and interacts with the UI the way a human would: clicking buttons, filling forms, navigating pages, and checking that elements render correctly.
When the agent finds a problem during this verification, it does not stop and report a failure. It goes back to the code, fixes the issue, rebuilds, and tests again. This loop continues until the agent has verified that its changes actually work. When verification passes, the agent records a video of the entire session, takes screenshots of key states, and collects logs. All of this gets attached to the pull request as artifacts.
Cursor has been dogfooding this capability internally. They used a cloud agent to build source code links for the Cursor Marketplace: the agent implemented the feature, navigated to the imported Prisma plugin, clicked each component to verify the GitHub links worked, then rebased onto main, resolved merge conflicts, and squashed to a single commit. For security work, they kicked off a cloud agent from Slack to triage a clipboard exfiltration vulnerability. The agent built an exploit page, started a backend server, loaded it in the browser, and recorded the complete attack flow. The summary appeared in the Slack thread.
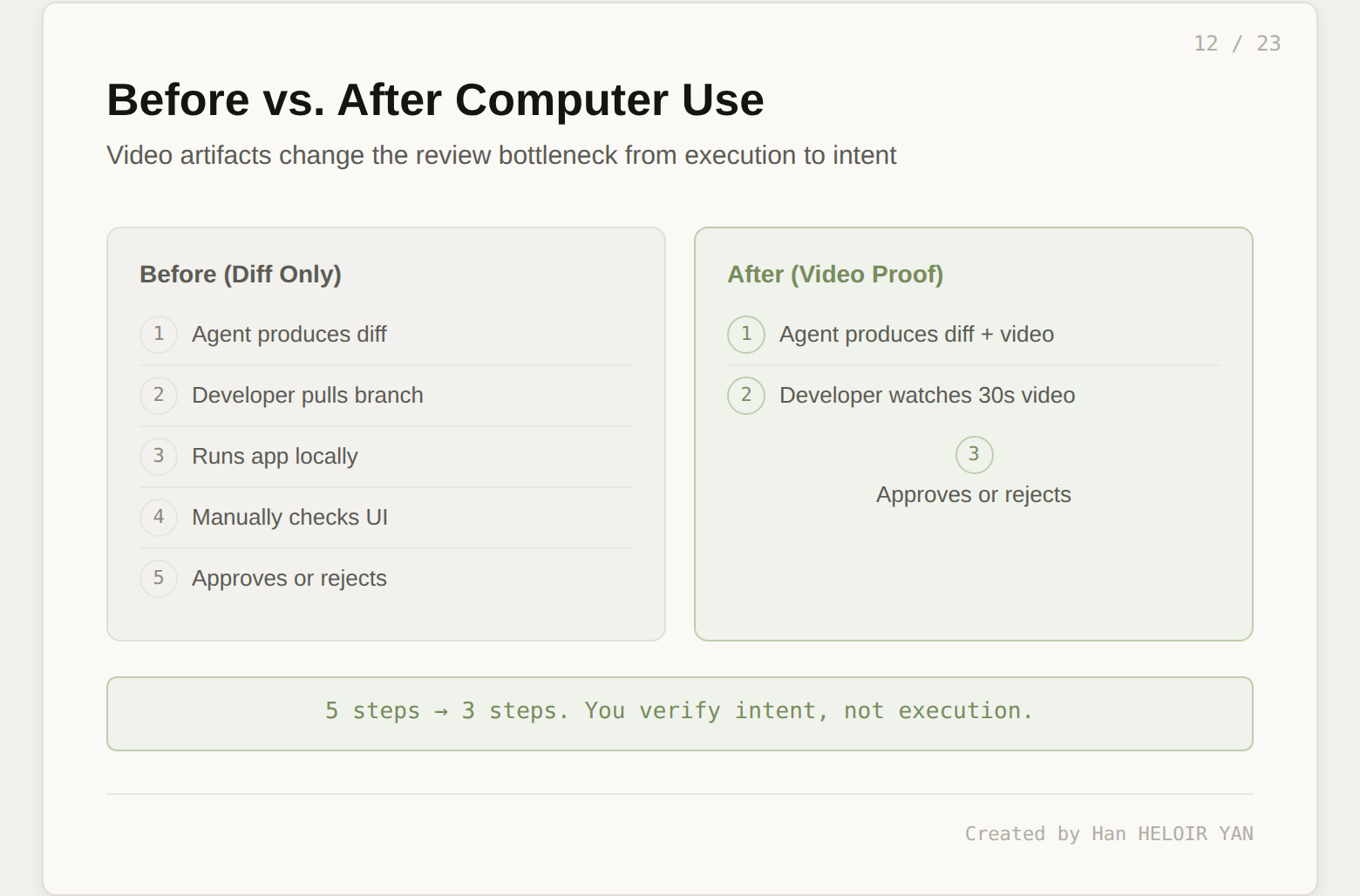
The pull request from a cloud agent is not a diff. It is a diff plus a video demo plus screenshots plus logs plus a clean commit history (rebased, conflicts resolved, squashed). When you review this PR, you are not reading code and mentally simulating whether it works. You are watching a 30-second video of the agent demonstrating the feature. This changes the review bottleneck fundamentally: you verify intent, not execution.
For teams that have adopted this workflow, the code review conversation shifted. Reviewers stopped asking "does this work?" and started asking "is this what we actually wanted?" The mechanical verification is handled by the agent. The human judgment is reserved for product decisions. That is a meaningful reallocation of engineering attention.
Now that you have seen what actually happens, here is how it maps to the harness stack from the previous section. Each layer of the harness corresponds to a piece of the workflow you just walked through.
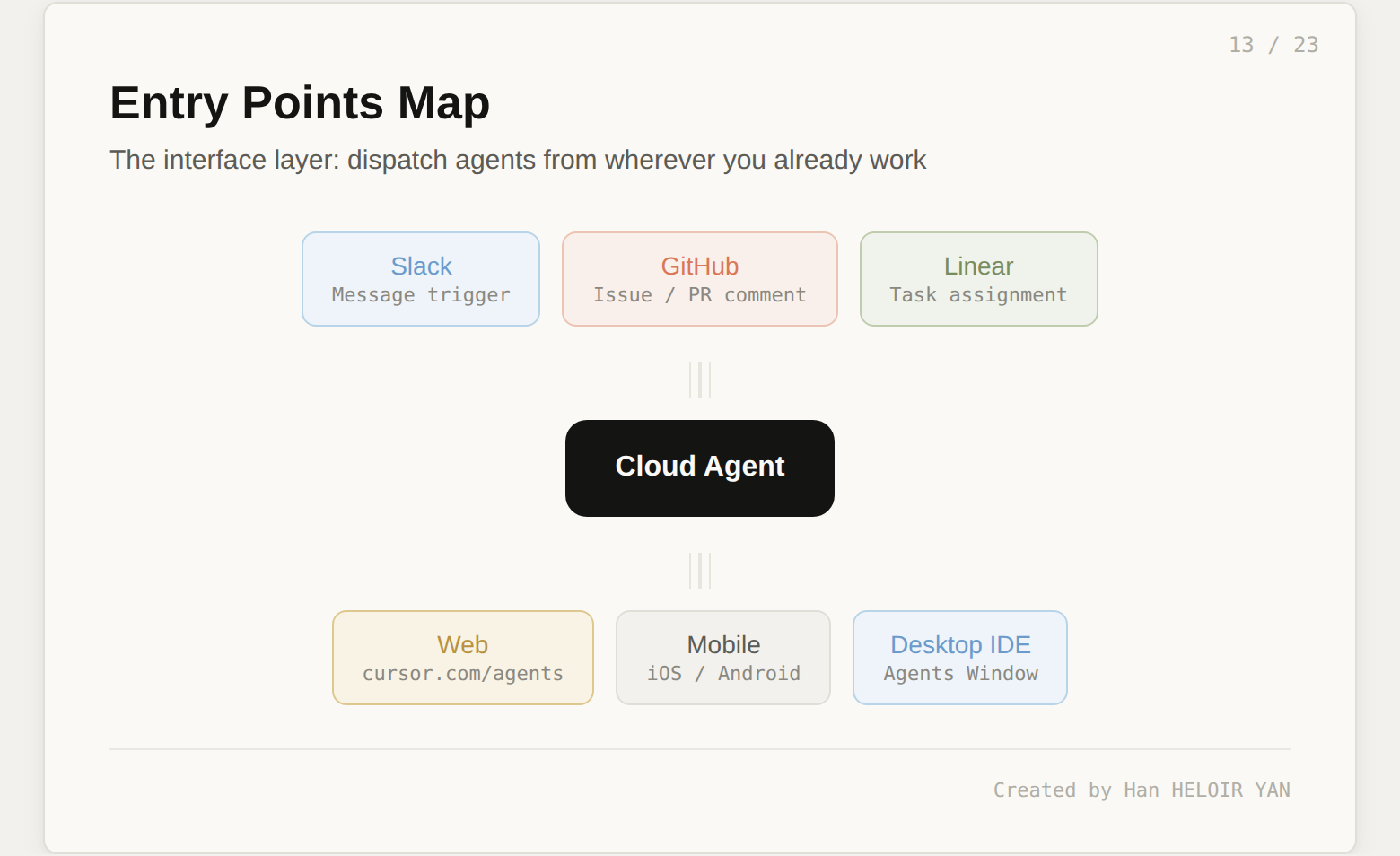
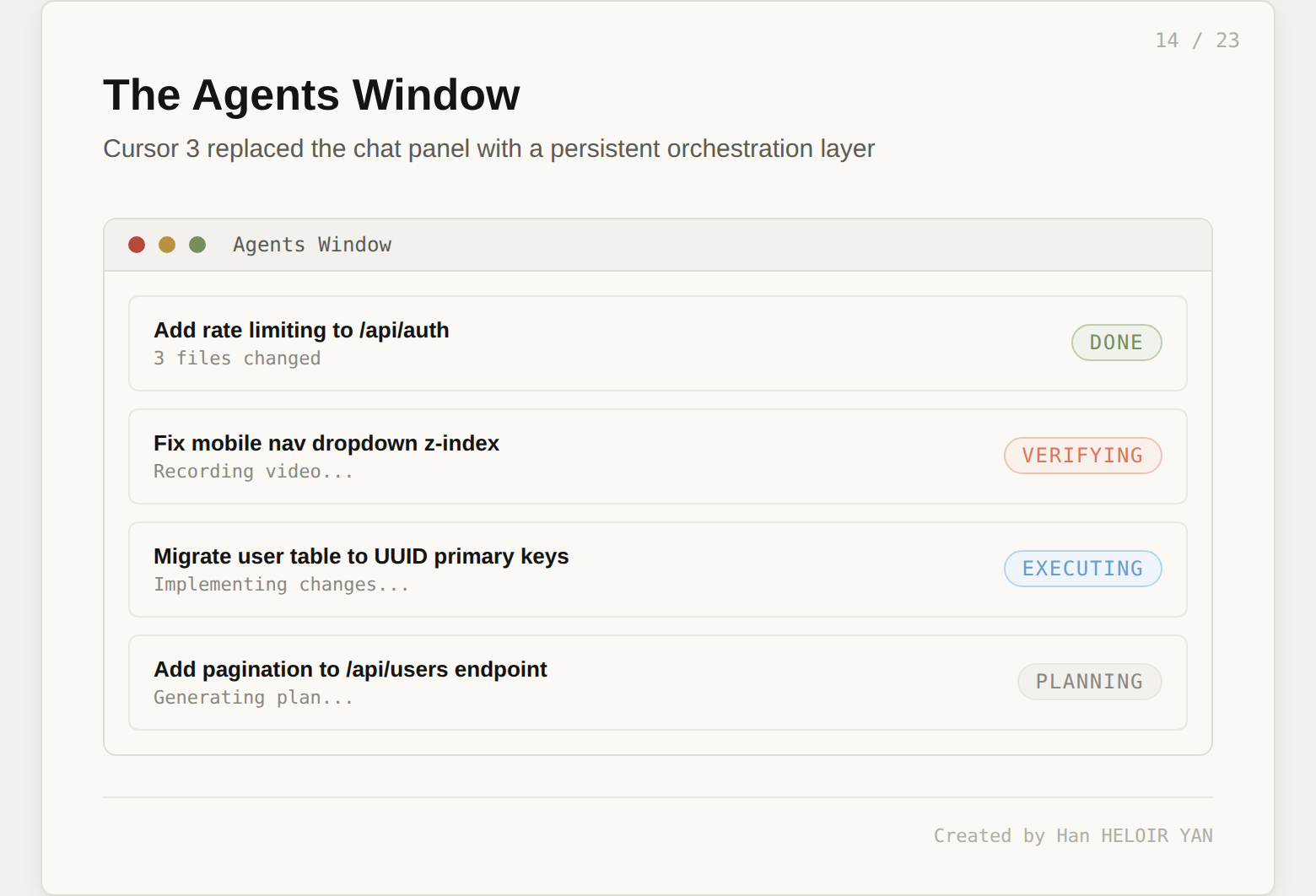
Interface layer. Cloud agents can be triggered from Slack, GitHub, Linear, cursor.com/agents (web), mobile, or the desktop IDE. The Agents Window in Cursor 3 replaced the chat panel with a persistent orchestration panel: task cards showing Planning, Executing, Reviewing, or Done status, with file diffs and progress indicators. You dispatch five tasks, monitor them as cards, and review results when they surface. The mental model shifted from pair programming to project management.
Orchestration layer. Plan mode, model routing, the race pattern, and subagent dispatch live here. This is the layer that decides how work gets done and which model does it. As shown in the race pattern above, Cursor does not commit to a single model. It hedges by running multiple models on the same problem and selecting the best output.
Execution layer. VM isolation and the self-hosted option. This layer determines where code runs and who controls the environment. The trust boundary decision lives here: Cursor-hosted means code leaves your machine; self-hosted means it stays on your network.
Verification layer. Computer use, video recording, screenshot capture, and log collection. This is the layer that turns a code diff into proof. Without it, cloud agents are just remote code generators. With it, they are autonomous engineers that demonstrate their work.
Output layer. The PR with artifacts. The deliverable format that closes the loop between the agent's work and the developer's review.
Five layers of harness. One layer of model at the bottom. The model is interchangeable. The harness is not.

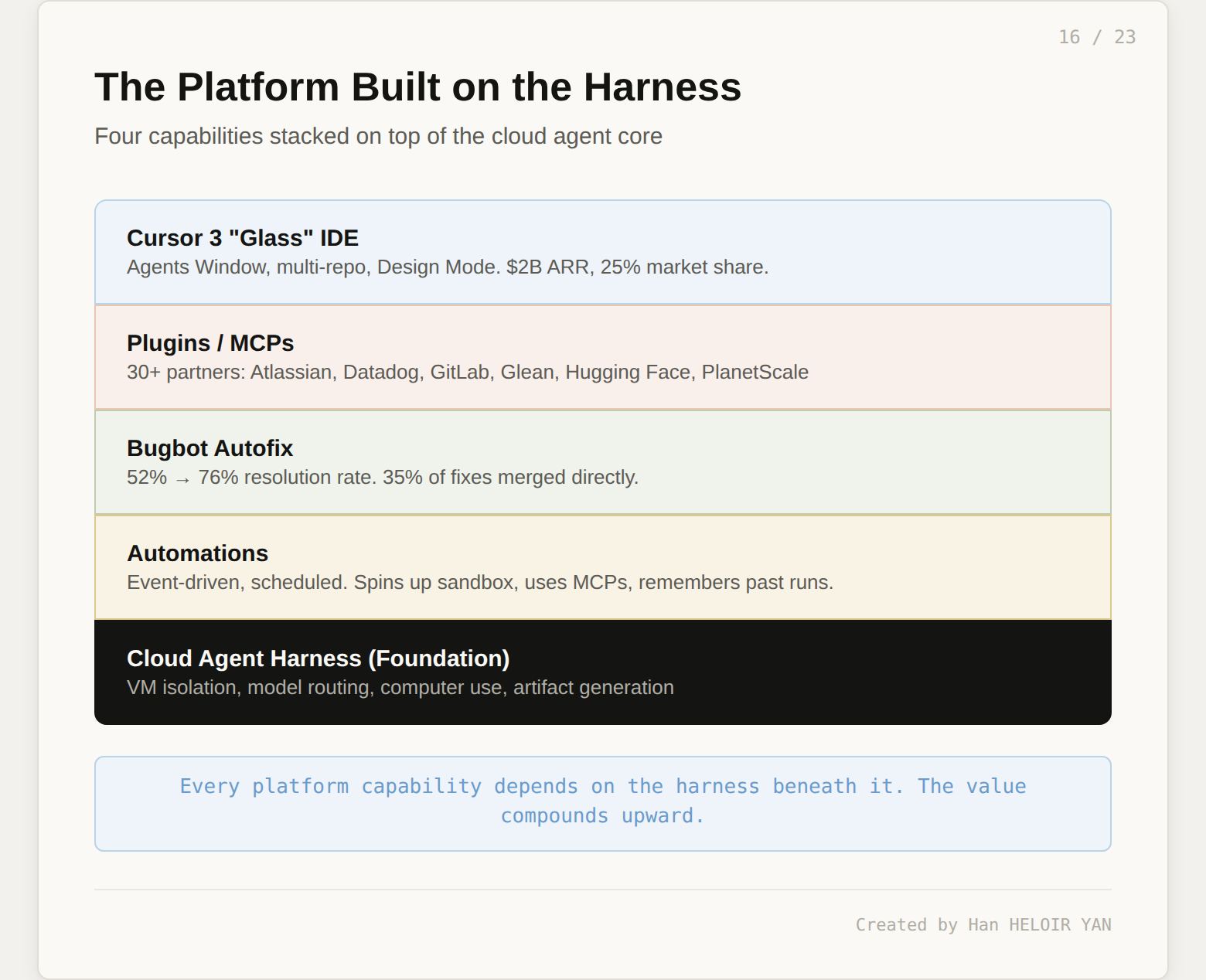
The cloud agent harness is the foundation. Cursor built four platform capabilities on top of it.
Automations. Event-driven agents that trigger on a schedule or on events from external tools without you being present. When a trigger fires, Cursor spins up a cloud sandbox, follows your instructions, uses whatever MCPs you have configured, and can optionally remember the outcome of previous runs to improve over time. One limitation worth noting: automations do not yet support computer use, so automated agents cannot do visual verification.
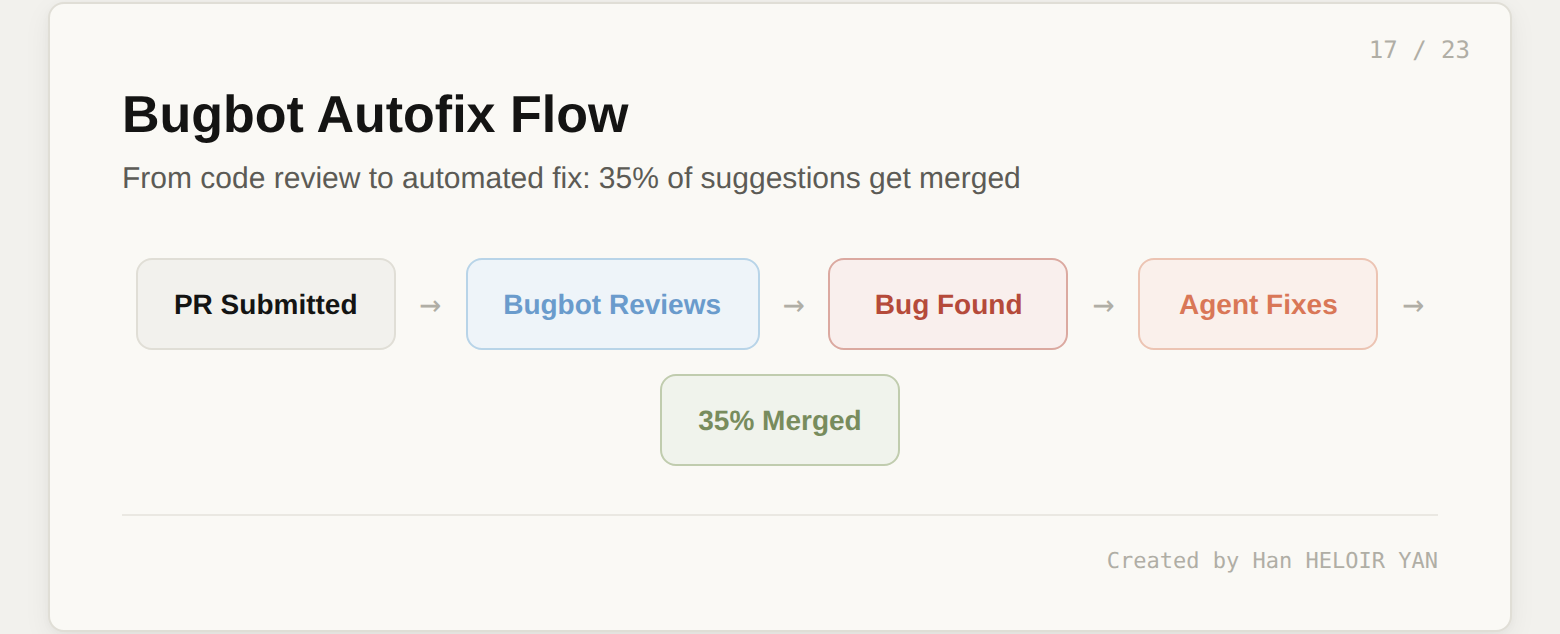
Bugbot Autofix. Bugbot started as a code reviewer. Now, when it finds a problem on your PR, it spins up a cloud agent on its own VM, tests a fix, and proposes the fix directly on your pull request. Over 35% of Bugbot Autofix suggestions are being merged into the base PR. The resolution rate (bugs flagged by Bugbot that get fixed before merge) climbed from 52% to 76% over six months, while the average number of issues identified per run nearly doubled. The tool is getting more accurate, not just louder.
Plugin ecosystem. More than 30 plugins from partners including Atlassian, Datadog, GitLab, Glean, Hugging Face, monday.com, and PlanetScale. Most plugins contain MCPs that cloud agents can use when kicked off manually or through automations. This is where the harness becomes an integration platform: agents that can read from Jira, write to Datadog, and query PlanetScale within a single task.
Cursor 3 "Glass." Launched April 2, 2026, this is the IDE rebuilt around agent orchestration. The Agents Window replaces the chat panel. Multi-repo layout lets agents read and write across multiple repositories in a single workspace. Design Mode provides a visual editor for UI components: click an element in a live preview, describe the change in natural language, and an agent modifies the source code with the preview updating in real time. Cursor crossed $2B ARR at launch and holds roughly 25% of the AI coding tool market.
Video artifacts make review 10x faster. You verify intent, not execution. A 30-second video catches visual regressions that reading a diff cannot.
Parallel agents multiply throughput for well-defined tasks. Ten bug fixes running simultaneously while you focus on architecture. The productivity math is simple: if each agent saves 30 minutes on a well-scoped task, ten agents save five hours in one session.
Multi-surface access meets developers where they already work. Kick off an agent from Slack. Review a PR on your phone. Dispatch tasks from GitHub issues. The interface layer is the least flashy part of the harness, but it removes enough friction to change daily behavior.
Self-hosted option addresses the hardest enterprise objection. "Our code cannot leave our network" used to disqualify Cursor Cloud entirely. Since March 2026, that objection has an answer: same harness, your infrastructure.
Lazy delete. Parallel workers occasionally use // ... existing code ... placeholder comments, silently deleting real code. You must review diffs carefully. This is not a rare edge case; multiple independent reviewers have flagged it.
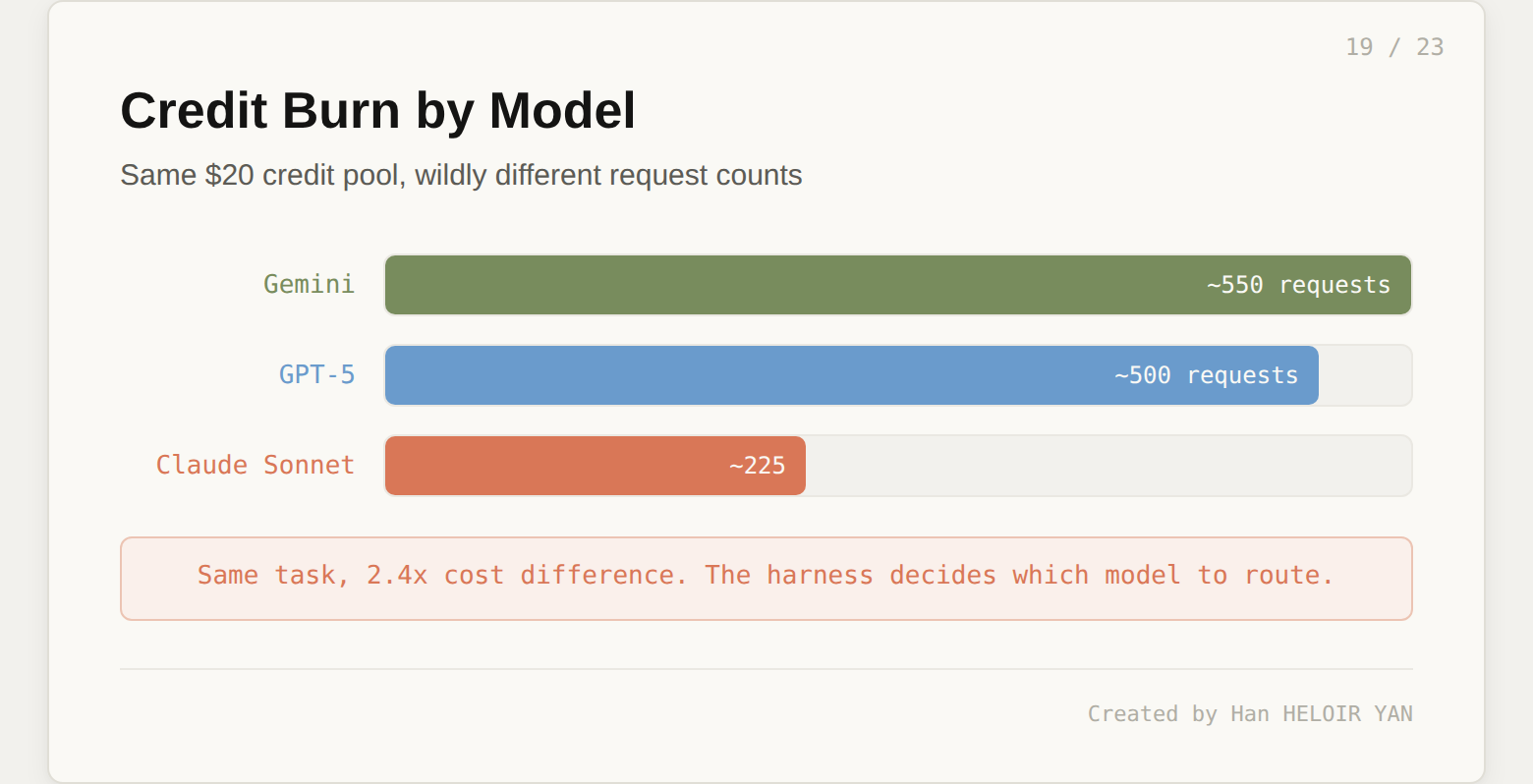
Credit burn. Heavy agentic workflows drain credits fast. The Pro plan compute ceiling gets hit mid-month for developers who lean hard on parallel agents. Agent mode runs several model calls per task at roughly $0.04 each, and Claude Sonnet costs 2.4x more per request than Gemini. The harness decides which model to route, and that routing decision has real cost implications.
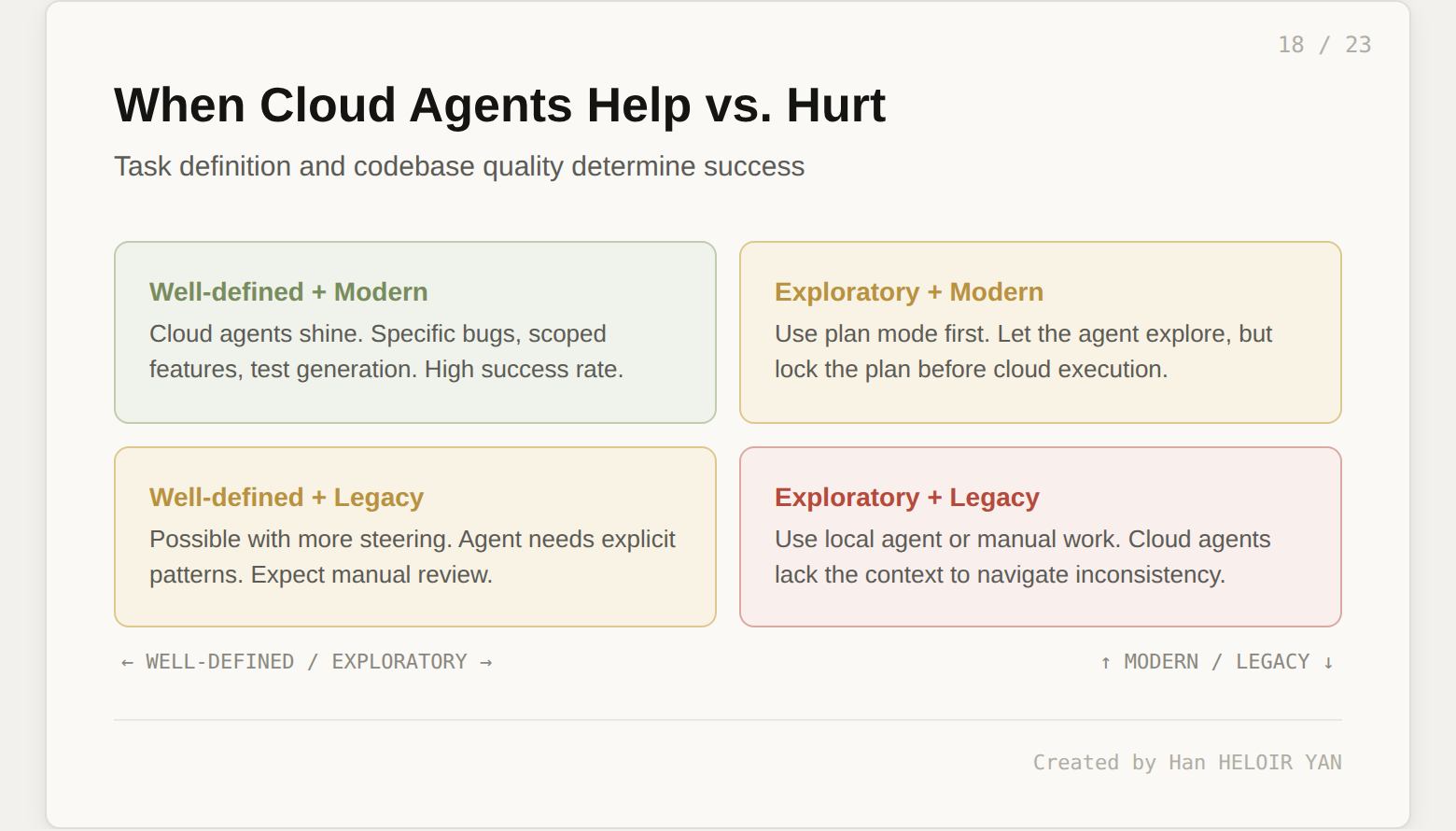
Task scoping is the real skill. Tasks that are too broad ("refactor the auth module") produce sweeping changes that require extensive review. Tasks that are too narrow ("rename this variable") are overkill. The sweet spot is medium-sized discrete tasks: "add rate limiting to the /api/auth/login route, using the existing middleware pattern in /api/users." Learning this scoping takes a few days of practice.
Legacy codebases hit the wall. Cloud agents work best with well-structured, modern codebases that have consistent conventions and good test coverage. If you point one at a legacy monolith with inconsistent patterns, expect more manual steering and lower success rates.
Agent recovery is clunky. When an agent goes in the wrong direction, the correction workflow (pause, describe the wrong turn, redirect) creates more friction than the old conversational chat model did. Cursor 3's Agents Window improved this with task cards you can fork and restart, but it is still rougher than the iterative back-and-forth of Cursor 2.
Shadow code. For CTOs and engineering managers, the biggest operational fear is logic written autonomously by an AI that human developers fail to understand or properly review. Cursor's Enterprise plan includes an AI code tracking API and audit logs to track which model authored which lines. But the review discipline has to come from the team, not the tool.
This is not a product review of Claude Code or OpenAI Codex. It is a harness comparison. All three tools solve the same job: ship code autonomously while the developer does something else. They use the same class of frontier models. The results are completely different because the harnesses are completely different.
Claude Code takes the opposite architectural bet from Cursor on almost every dimension. It is terminal-first. Code stays on your local machine. There are no cloud VMs. Instead of parallel orchestration across many agents, Claude Code goes deep on single complex tasks: subagent spawning with worktree isolation means Claude can work on multiple branches of a project simultaneously without interference, but all of it runs locally.
The reasoning depth is where Claude Code pulls ahead. With Opus and up to 200K tokens of context, Claude Code handles architectural refactors and complex multi-file changes that require sustained reasoning across a large codebase. The MCP integration is native and deep: Claude Code connects to local tools, databases, and services through a full ecosystem of protocol servers.
What Claude Code does not have: video artifacts, cloud VMs, or a GUI orchestration layer. The output is a diff and a conversation log, not a PR with video proof. The trust model is local-first: your code never leaves your machine, which makes it the default choice for teams with strict data residency requirements.
The Dispatch feature (launched March 17, 2026) adds a remote control layer: scan a QR code and your phone becomes a walkie-talkie to the Claude Code session running on your desktop. This solves the "AI works while you're away" problem, but with a single agent on a single machine, not with parallel cloud VMs.
Codex runs tasks in cloud sandboxes triggered from a web interface or GitHub issues. The harness is simpler than Cursor's: one task at a time, tight GitHub integration, no video artifacts, no model racing. The bet is that most useful agent work starts from well-scoped issues in an issue tracker and ends with a PR.
Where Codex wins is simplicity. Point it at a GitHub issue. It reads the issue, creates a branch, implements the change, and opens a PR. The workflow is linear and predictable. Where it loses is the absence of verification (no computer use, no video proof) and the lack of parallelism.
| Harness Layer | Cursor Cloud | Claude Code | OpenAI Codex |
|---|---|---|---|
| Interface | IDE + Slack + GitHub + Mobile + Web | Terminal + Phone (Dispatch) | Web + GitHub |
| Orchestration | Parallel dispatch, model racing, plan mode | Subagent spawning, worktree isolation | Single task from issue |
| Execution | Cloud VMs (10 to 20 parallel) | Local machine | Cloud sandbox |
| Verification | Computer use + video + screenshots + logs | Test execution (no visual proof) | Test execution (no visual proof) |
| Output | PR + video artifacts | Diff + conversation | PR + diff |
| Model | GPT-5 / Claude / Gemini / Composer 2 | Claude only | GPT series only |
| Trust boundary | Code leaves machine (unless self-hosted) | Code stays local | Code in OpenAI cloud |
| Parallelism | 10 to 20 agents | Multiple subagents (same machine) | One task at a time |
Cursor wins when you have 10+ well-defined tasks to parallelize, you want visual proof for reviewers, your team communicates via Slack and GitHub, and you are comfortable with code in cloud VMs (or can self-host).
Claude Code wins when you have one complex architectural task requiring deep reasoning, code must stay local, you need MCP integrations with local tools, or you work terminal-first.
Codex wins when your workflow is GitHub-issue-driven, tasks are well scoped, and you want the simplest possible path from issue to PR.
Same models available to all three. Completely different harnesses. Completely different developer experiences. The harness is the product.



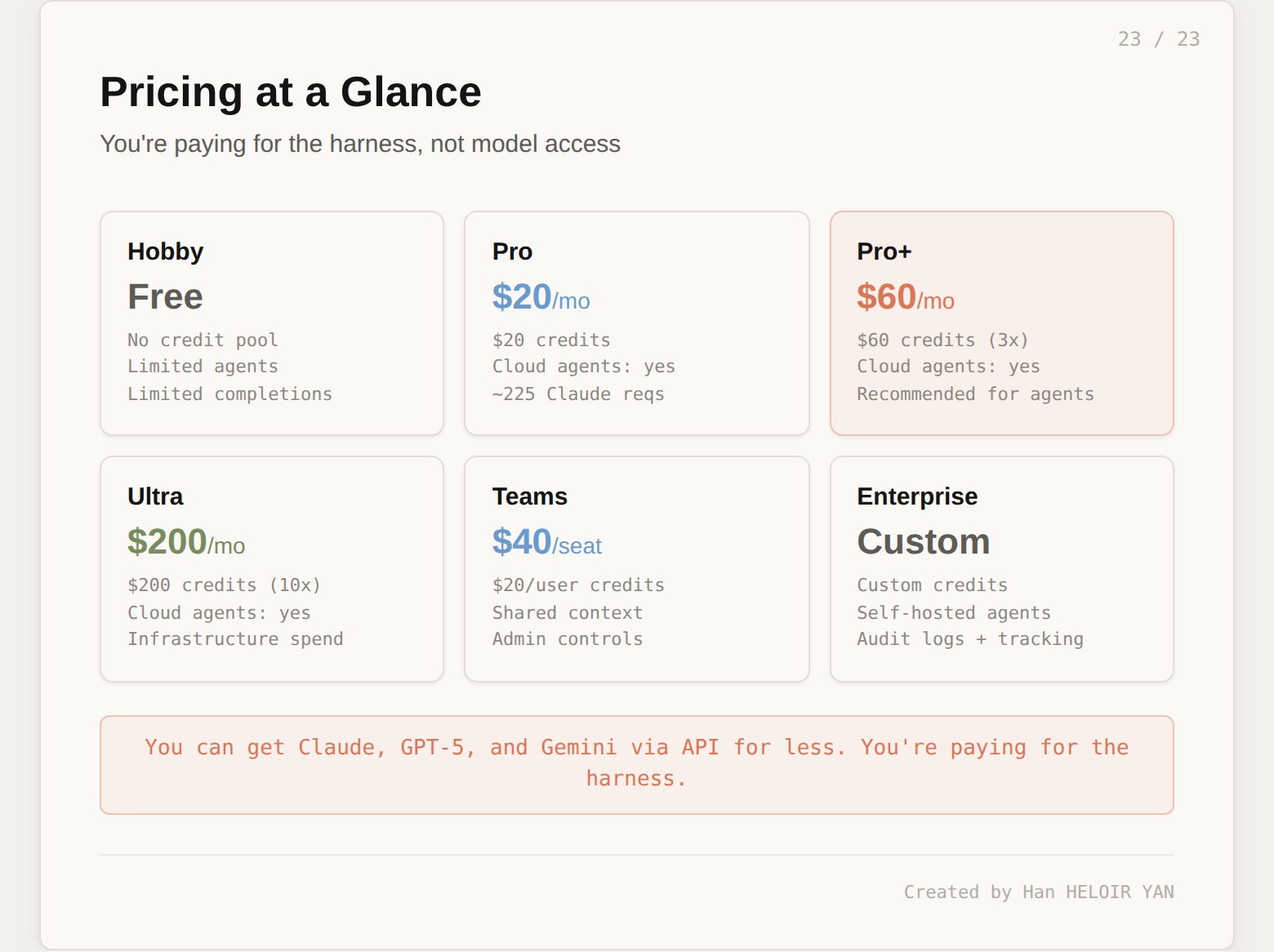
Cursor uses credit-based billing. Every paid plan includes a credit pool denominated in dollars. When you make an AI request, credits are deducted based on two factors: which model you use and how complex the task is.
| Plan | Monthly | Annual | Credit Pool | Cloud Agents | Self-Hosted |
|---|---|---|---|---|---|
| Hobby | Free | Free | None | Limited | No |
| Pro | $20 | $16 | $20 | Yes | No |
| Pro+ | $60 | $48 | $60 (3x) | Yes | No |
| Ultra | $200 | $160 | $200 (10x) | Yes | No |
| Teams | $40/seat | $32/seat | $20/user | Yes | No |
| Enterprise | Custom | Custom | Custom | Yes | Yes |
The credit math matters. The $20 Pro pool covers approximately 225 Claude Sonnet requests, 550 Gemini requests, or 500 GPT-5 requests. Agent mode runs multiple model calls per task, each at roughly $0.04. A complex parallel session with 5 agents on Claude Sonnet can consume several dollars of credits in minutes. Pro compute ceiling gets hit after roughly 15 to 20 complex parallel sessions per month.
The insight: you are not paying for model access. You can get Claude, GPT-5, and Gemini through their respective APIs for less. You are paying for the harness: VM infrastructure, codebase indexing, artifact generation pipeline, plugin ecosystem, and the orchestration layer that ties it all together.
Try this week: pick one well-scoped bug from your backlog. Kick off a single Cursor Cloud Agent (or Claude Code background agent, or Codex). Review the output. Pay attention to how the harness shaped the experience, not which model was inside it. That observation will tell you more about where this industry is going than any benchmark.
Created by Han HELOIR YAN