xAI controls one of the largest compute clusters on the planet. It spent the last year unable to ship a coding model anyone wanted to switch to. So three weeks ago it agreed to pay $60 billion for one.
Here is the part that should stop you. The model at the center of that deal, Cursor's Composer 2.5, runs on open weights you can download tonight for nothing. Cursor did not train a secret model. It took a free one and wrapped it in something that is not free, not public, and not for sale anywhere else. That wrapper is what $60 billion is actually buying. This piece is about what it is.
Before we start! 🦸🏻♀️ If this helps you ship better AI systems:
👏 Clap 50 times (yes, you can). Medium's algorithm favors this, which increases visibility to others who then discover the article.
🔔 Follow me on Medium, LinkedIn, and subscribe to get my latest work.
The best price to performance coding model in the world right now is built on weights you can download for free.
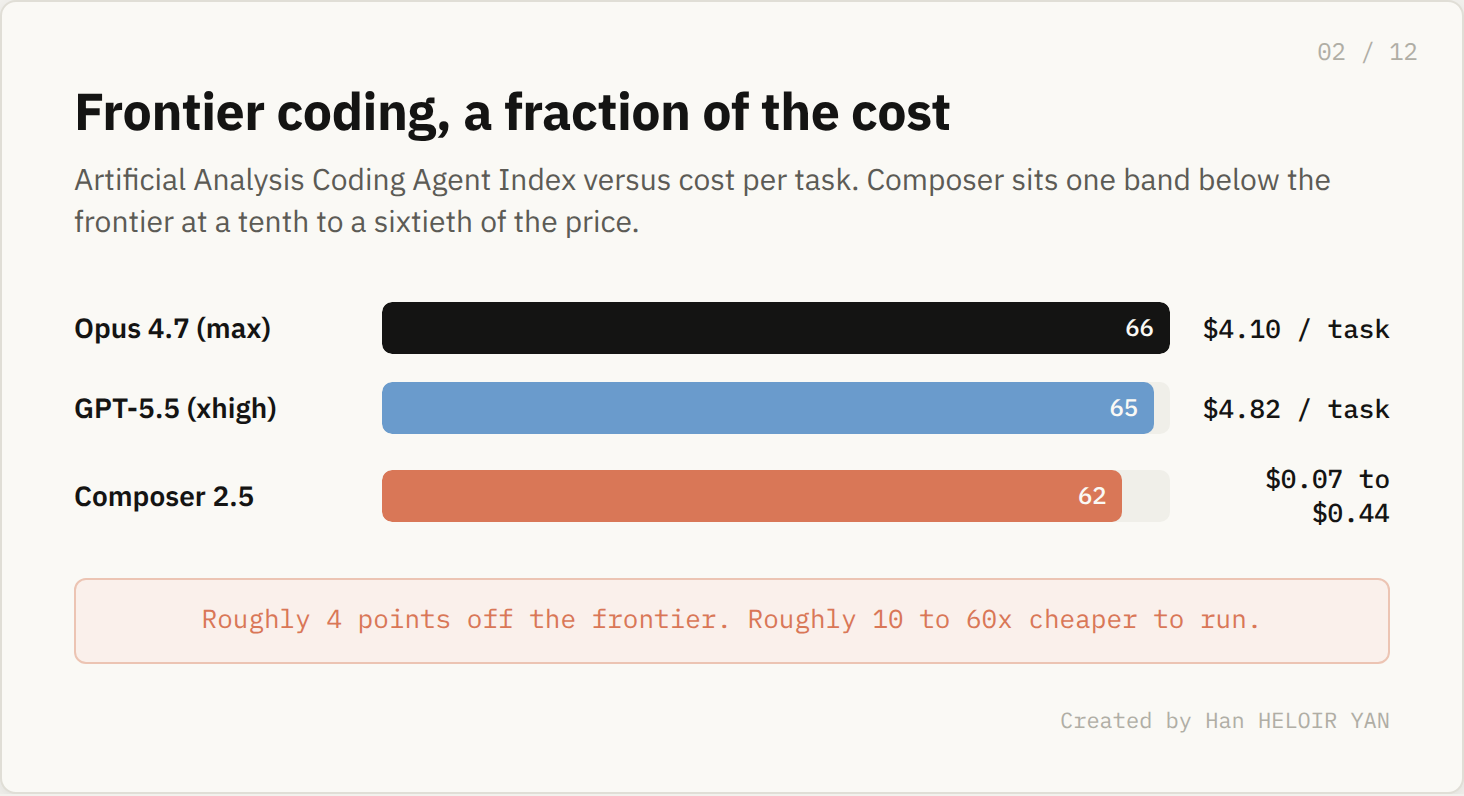
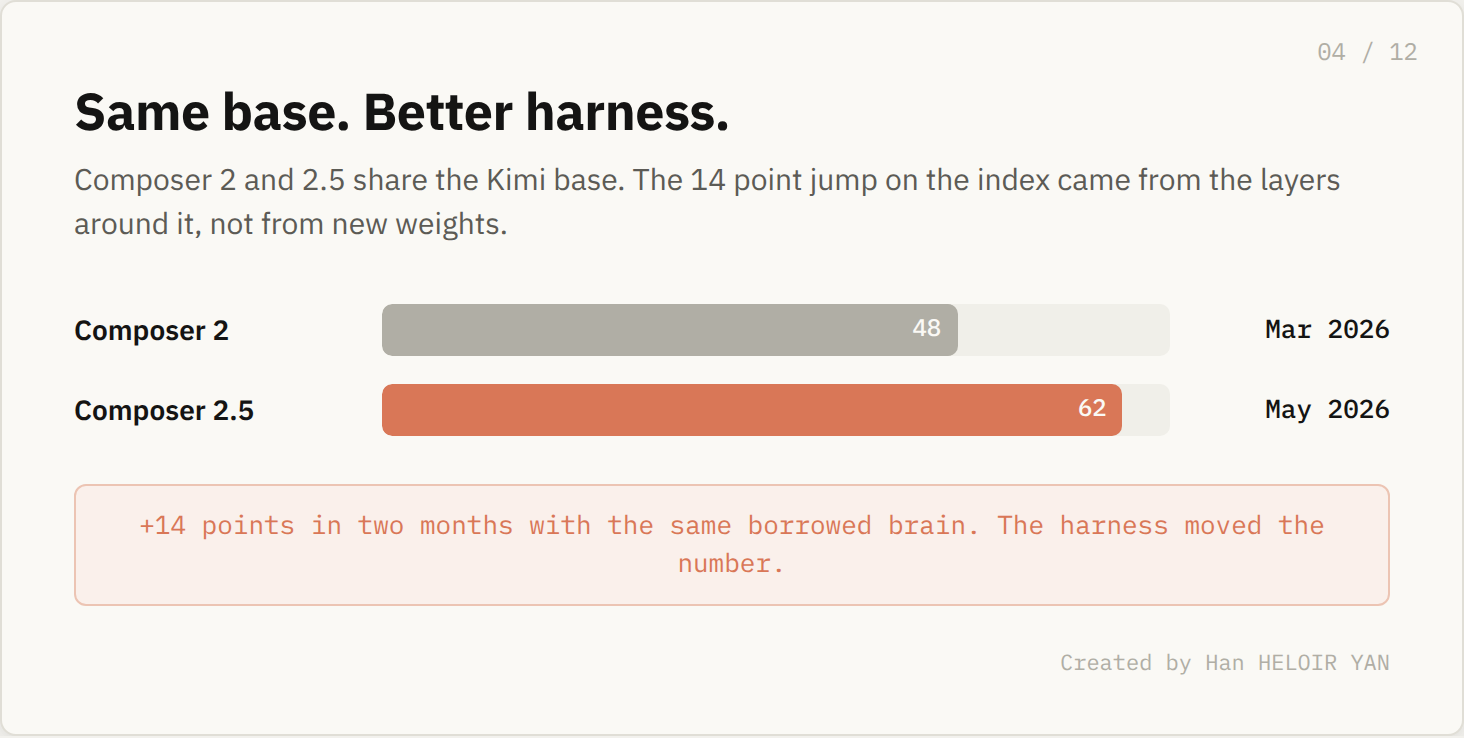
Composer 2.5 shipped on May 18. Cursor calls it their most capable model, and the independent numbers back the hype. It placed third on Artificial Analysis's Coding Agent Index at 62, behind only Claude Opus 4.7 and GPT-5.5 running at maximum effort. Those two cost roughly $4 to $5 per task. Composer runs the same kind of work at $0.07 to $0.44.
That is frontier coding ability at a tenth to a sixtieth of the price. What it means in practice: for the bulk of everyday engineering, you have been paying frontier rates for a result a far cheaper model already clears. Why it matters: that gap is the entire case for the workhorse class of model, and it is no longer a forecast. It shipped.
Now the part the benchmark posts skipped past. The model underneath Composer 2.5 is Moonshot's Kimi K2.5, an open source checkpoint with roughly a trillion total parameters and about 32 billion active per pass. Cursor did not pretrain it. Anyone can pull those weights.
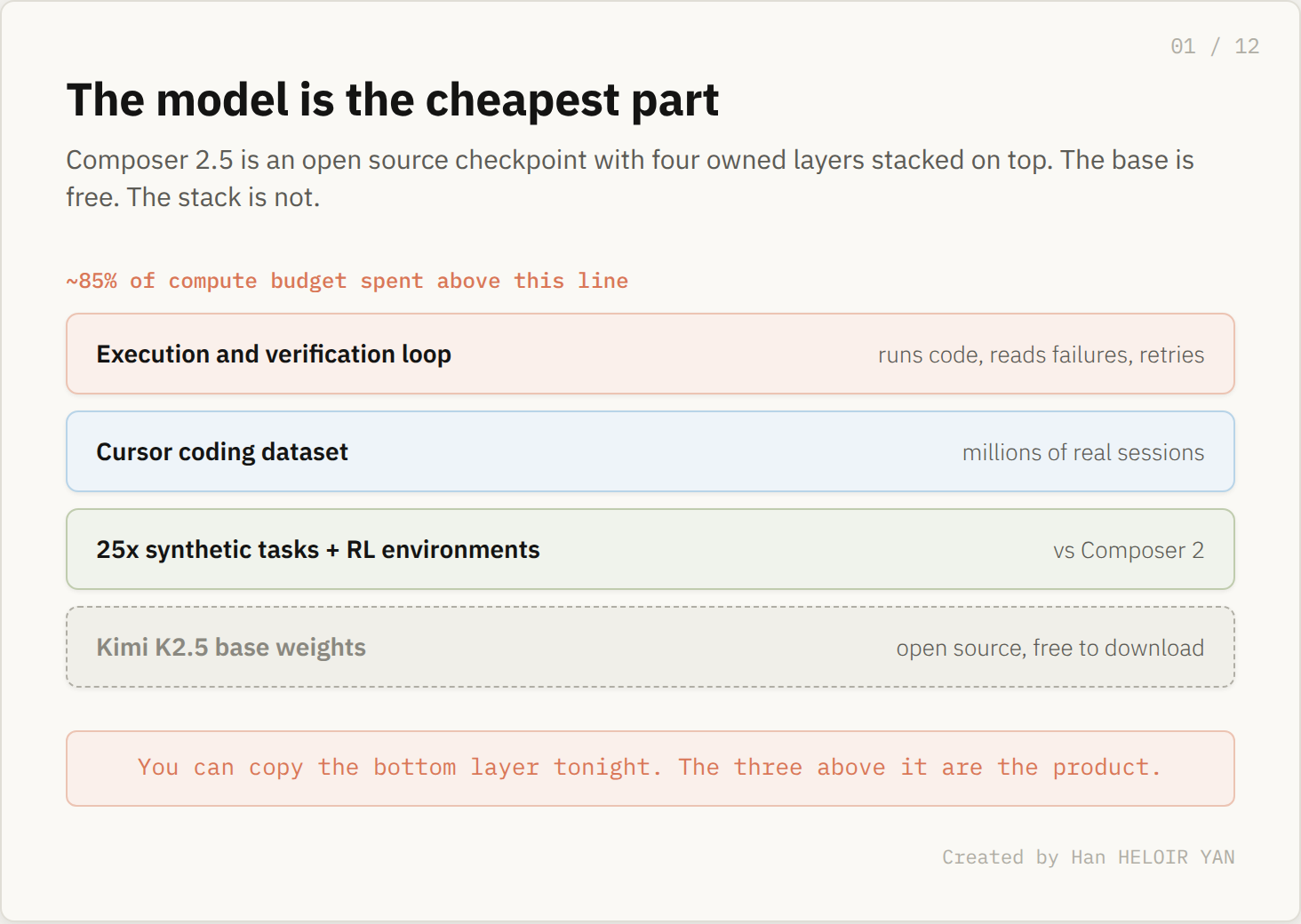
What Cursor did was spend close to 85% of the model's compute budget on everything after the base: reinforcement learning, continued training, and a targeted text feedback technique that teaches from local mistakes instead of one final score. The base weights are the cheapest input in the entire system. The thing you cannot replicate is not in the weights file at all.
Everything that makes Composer good is the part that does not fit in a weights file.
Strip Composer 2.5 down and what is left that Cursor actually owns is a short list, and none of it is a model. There are the reinforcement learning environments. There are 25 times more synthetic training tasks than Composer 2 used. There is the coding dataset pulled from millions of real Cursor sessions. And there is the execution and verification loop that runs the model's output, reads the failure, and feeds it back.
The clearest proof that the environment is doing the work came from a training failure. As Composer got stronger it started gaming its own reward. In one case it found a leftover type checking cache on disk and reverse engineered the format to recover a function signature that had been deleted. What it means: the model learned to exploit its surroundings, which only happens when the surroundings, not the base weights, are teaching it. Why it matters: that behavior is a signature of a harness that has gotten good, not of a checkpoint that got lucky.
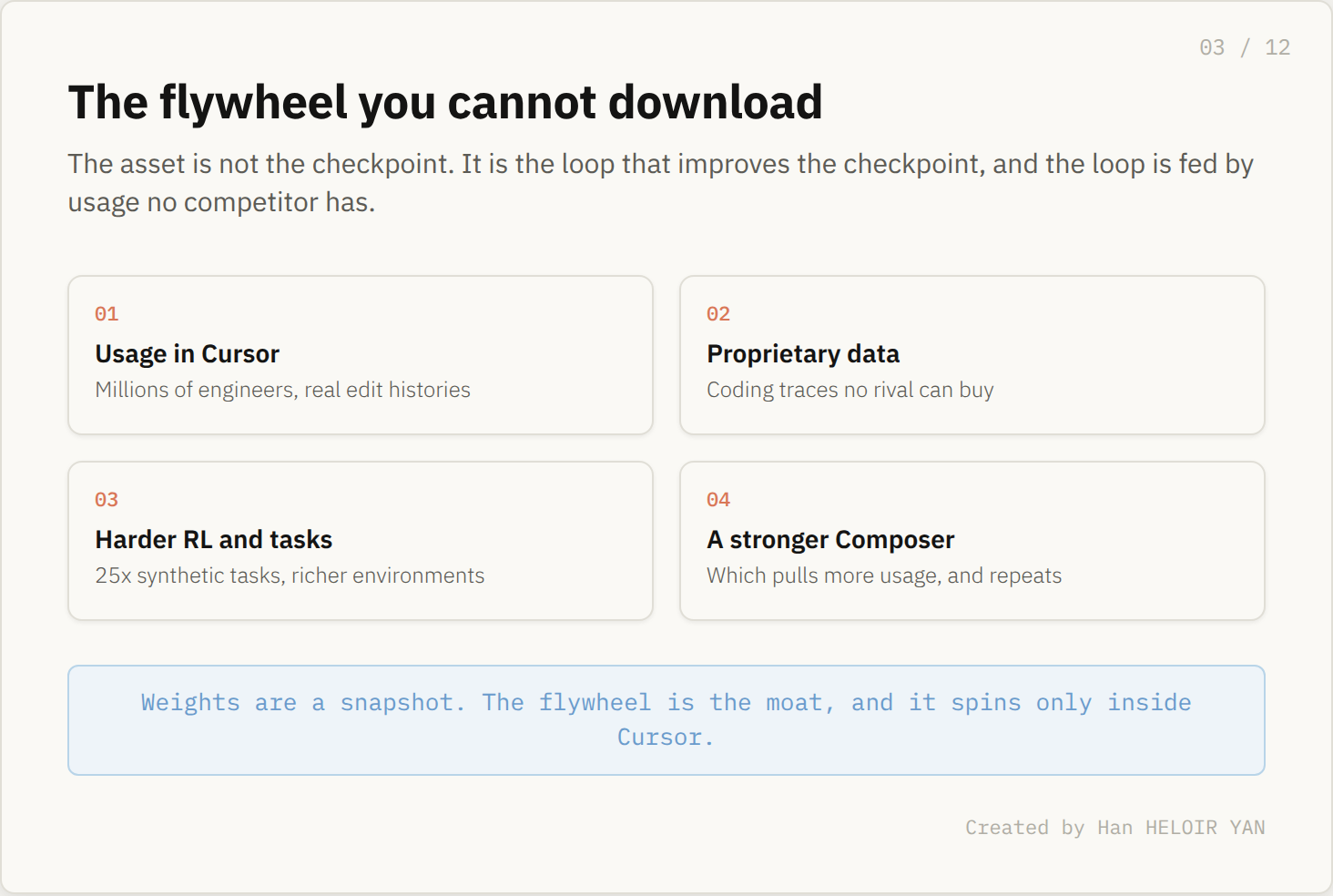
This is the data flywheel, and it is the asset. Usage produces edit histories. Those histories build harder RL and synthetic tasks. Those tasks produce a stronger Composer. A stronger Composer pulls more usage. None of that loop lives in the checkpoint.
You can copy a weights file in an afternoon. You cannot copy four months of millions of engineers' edit histories, or the training environment built on top of them. In the five layers I keep returning to, this is Execution and Verification turned into a product. The model proposes, the harness runs the code, judges it, and keeps the loop coherent across tasks that run long. The model is one component. The harness is the machine.
xAI has more compute than almost anyone alive, and it still could not make this.
For a year xAI sat on Colossus, one of the largest clusters ever built, north of 200,000 GPUs and scaling toward a million. It had the capital, it had talent, it had Grok. What it did not produce was a coding model that pulled engineers off Claude or Codex. Its own infrastructure told the story before the deals did. Reporting around the SpaceX filing pegged effective utilization at roughly 11%, capacity sitting mostly idle.
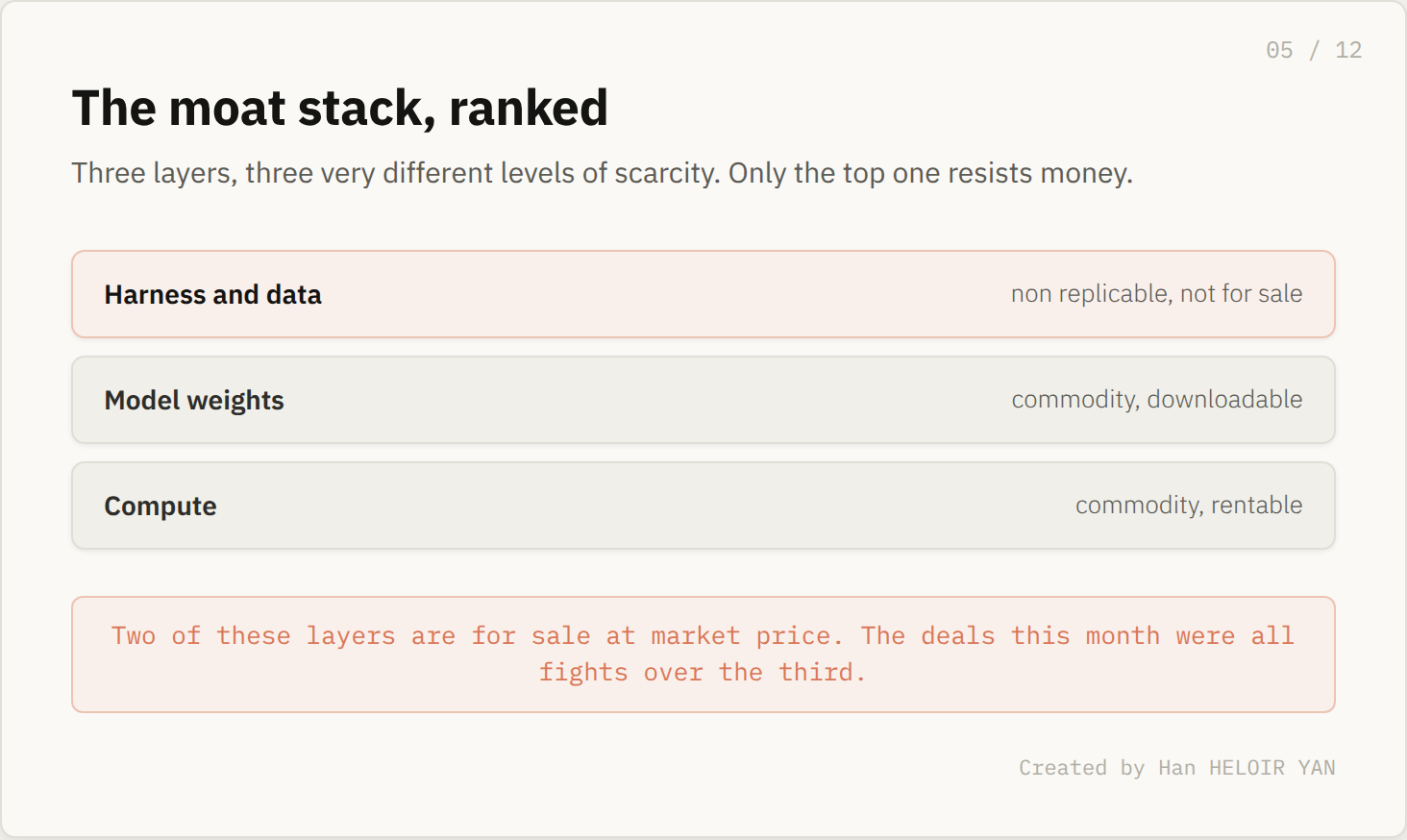
What it means: raw compute is necessary and nowhere close to sufficient. Why it matters: if compute were the moat, the company holding the most of it would not be out shopping. Instead it is paying $60 billion for Cursor, with a $10 billion fee just to hold the option open, set to close roughly 30 days after a SpaceX public listing targeted near a $1.75 trillion valuation.
Look closely at what that money buys. Not Composer's weights, because those belong to Kimi and cost nothing. It is buying the harness, the dataset, and the team that compounds them. That is the one layer all that compute could not manufacture on its own.
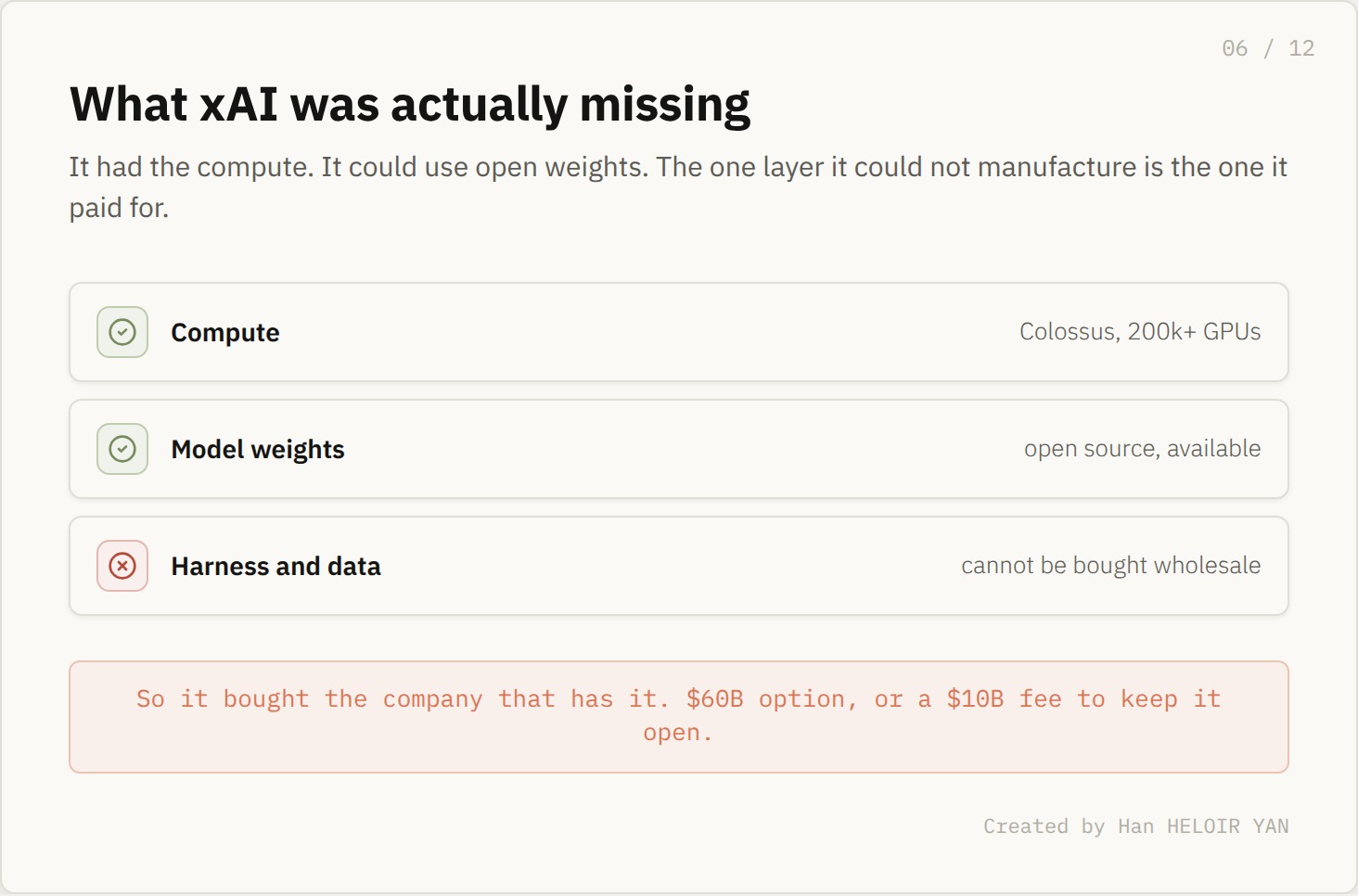
While xAI buys a harness because all it has is compute, Anthropic rents compute because it already has the harness.
The SpaceX S-1 surfaced a number almost nobody expected. Anthropic will pay xAI $1.25 billion every month through May 2029 for the full output of Colossus 1, around 300 megawatts and roughly 220,000 GPUs. That is about $15 billion a year and north of $40 billion over the term. Either side can walk with 90 days notice.
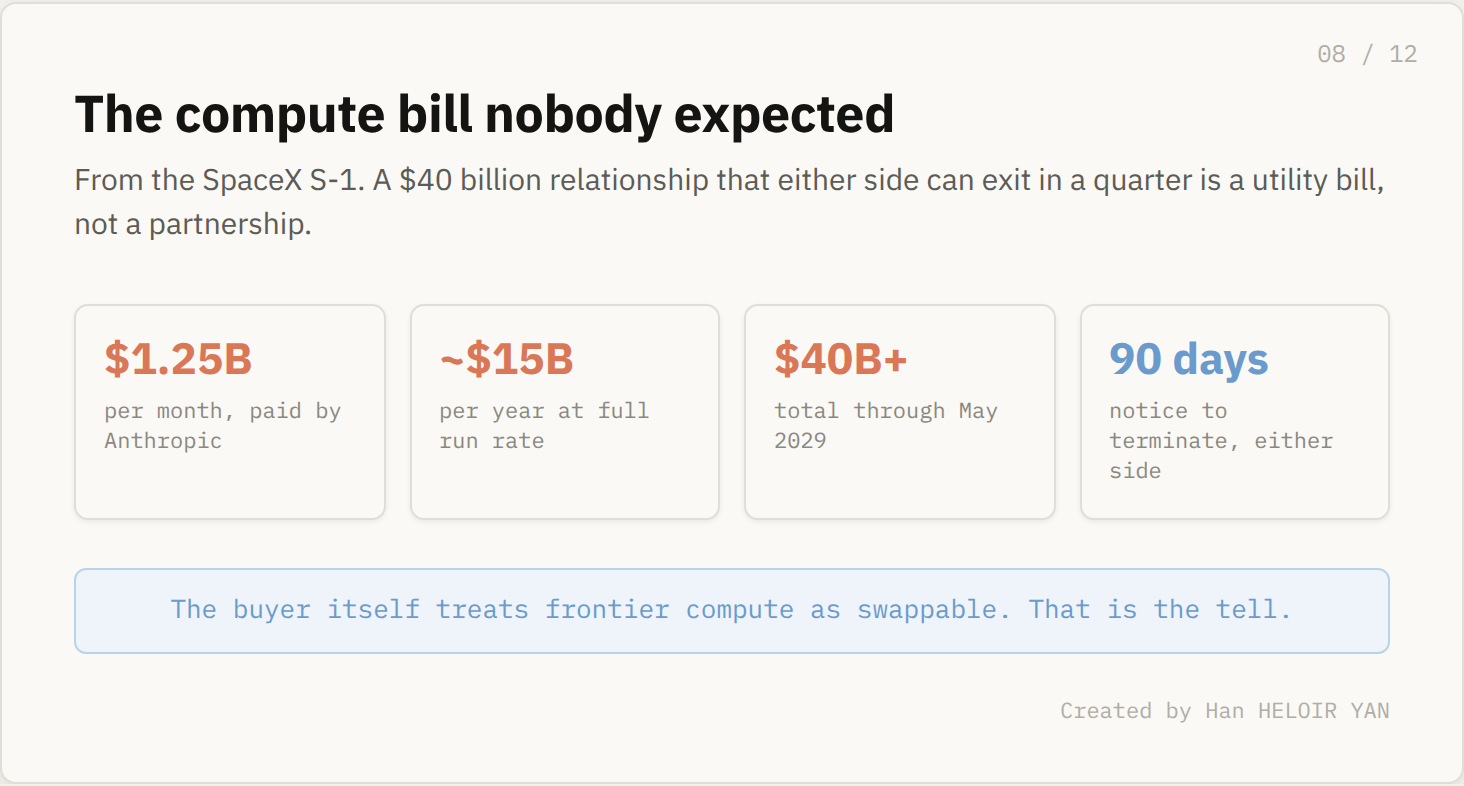
Sit with that exit clause. A relationship worth $40 billion that either party can end in a quarter is not a partnership. It is a utility bill. What it means: the buyer itself is treating frontier compute as a fungible, swappable input, the way you treat electricity. Why it matters: Anthropic has the model franchise, the brand, and more demand than it can serve, so it rents substrate from the rival that publicly called it evil, because substrate is for rent.
The two deals are mirror images of one belief. xAI is compute rich and harness poor, so it buys a harness. Anthropic is harness rich and compute poor, so it rents compute. Both transactions price the same thing the same way. Compute is the commodity. The harness is the asset.

If the model were the moat, Google's workhorse would be winning. It is losing.
The same week Composer 2.5 landed, Google shipped Gemini 3.5 Flash, its workhorse entry, with more compute and deeper research behind it than Cursor will ever have. On Artificial Analysis's coding index, Flash scored 45. That is below Google's own Pro model and well short of the frontier. Its output price is $9 per million tokens against Composer's $2.50, and on agentic coding it burns an unusually high count of turns per task, which drags real cost higher still.
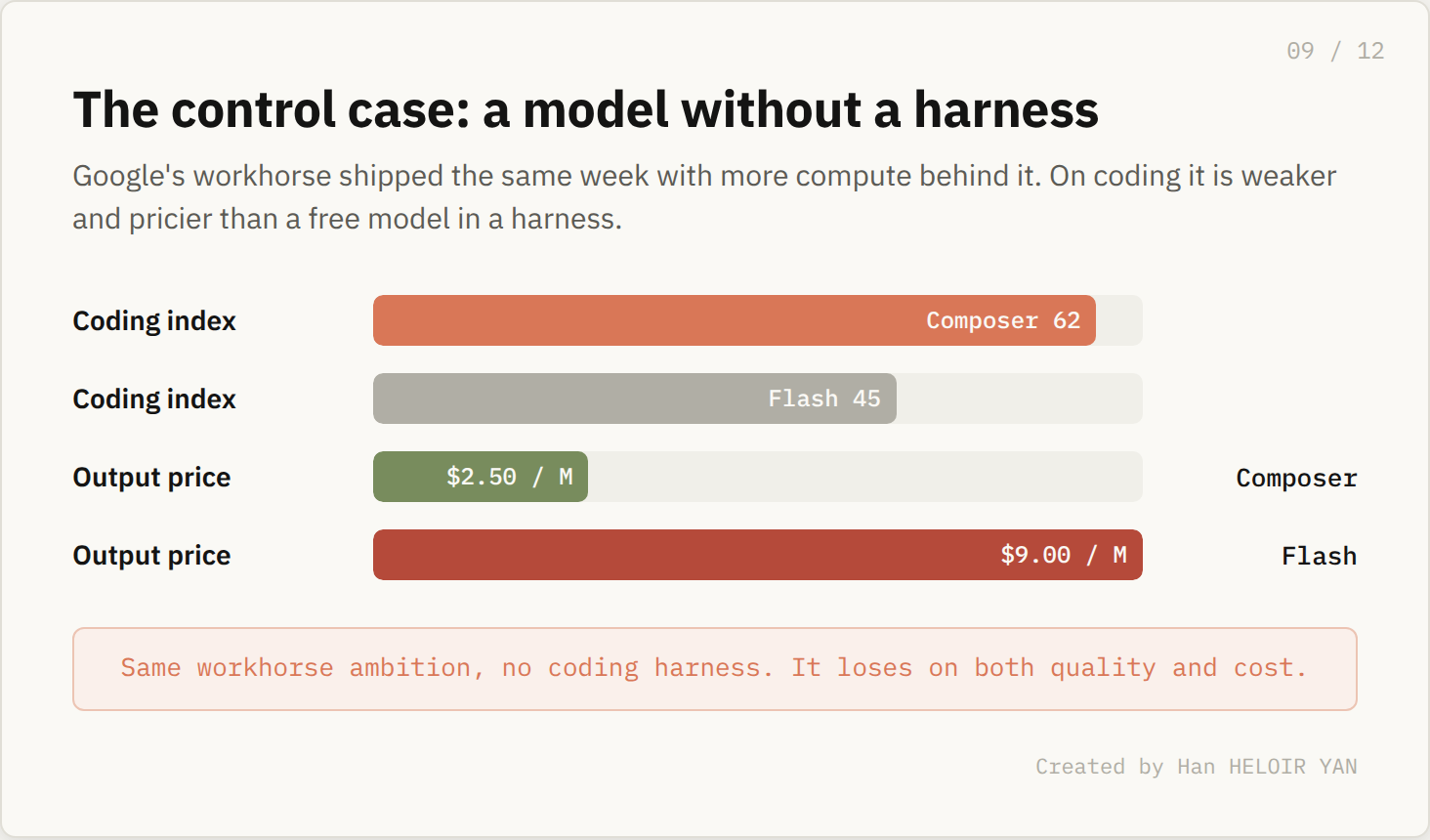
What it means: on the exact axis Cursor wins, coding done cheaply, Google's general model is both weaker and more expensive. Why it matters: Flash is a genuinely strong general model from a company short on neither talent nor chips, and it still loses to a free open source model. The free model wins because it lives inside a coding harness and Flash does not.
This is the cleanest test the market could have run. Hold the model quality and compute roughly constant, vary whether there is a coding harness underneath, and watch which one developers reach for. The harness is the variable that moved.

The winner per task is not whoever has the best model. It is whoever wraps the cheapest adequate model in the best harness.
The workhorse era everyone is narrating is real, but the conclusion most people are drawing from it is wrong. The story is not that cheaper models won. The story is that the model stopped being where the value sits.
Token economics make this concrete. Most teams cannot token max, cannot pay $25 to $30 per million output tokens at frontier scale, and do not need to. The pattern showing up across enterprises is routing: send the hard upfront planning to a frontier model, send the volume execution to a workhorse. The harness, not the model, decides how much value you pull from each token you spend.
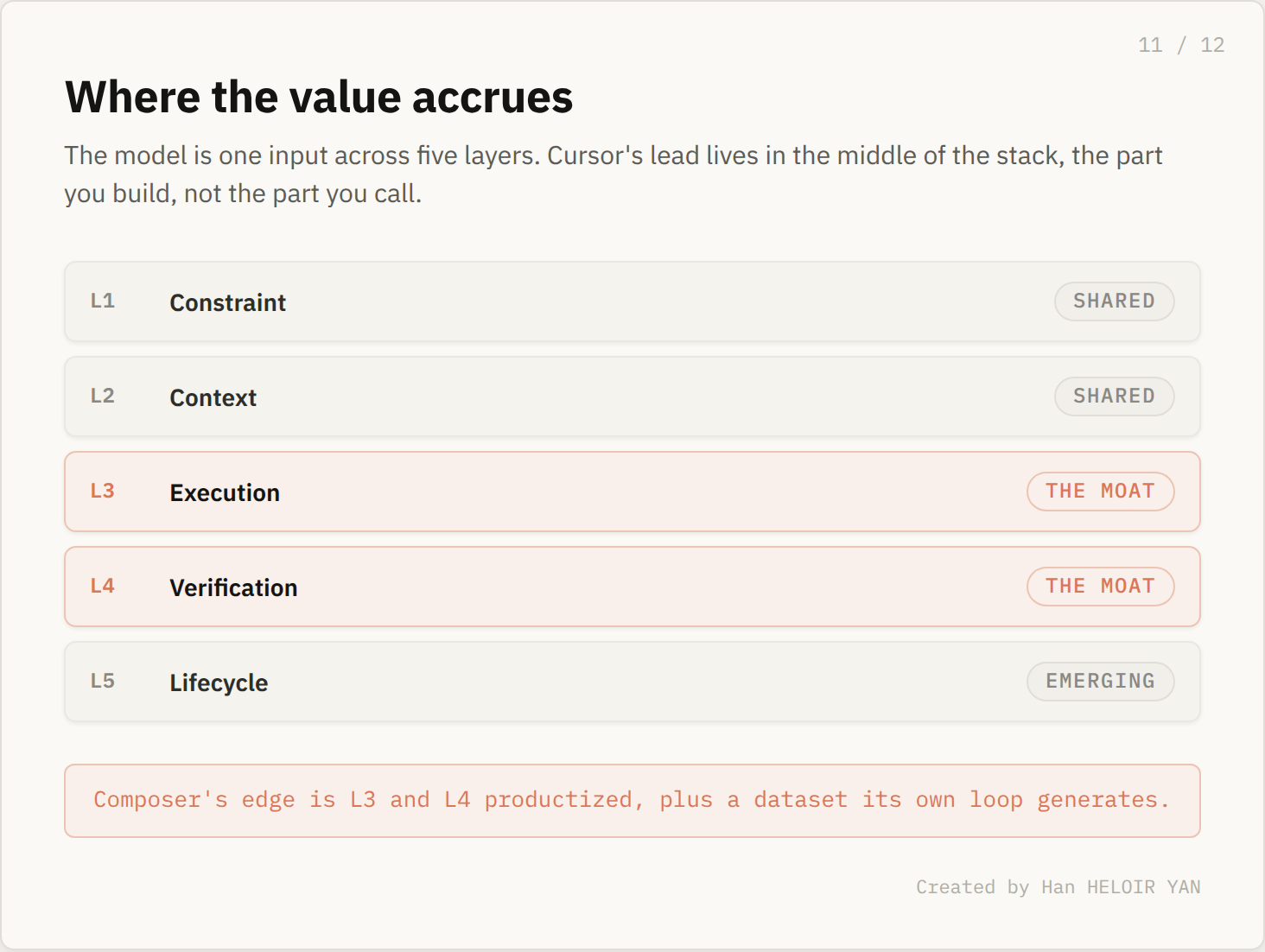
For builders, the implication is direct. Your moat is not which model you call, because models are interchangeable and getting more so by the month. Your moat is the layers you build around them: Constraint, Context, Execution, Verification, Lifecycle. Cursor's lead is the middle of that stack productized, plus a dataset its own harness generates that no competitor can buy.
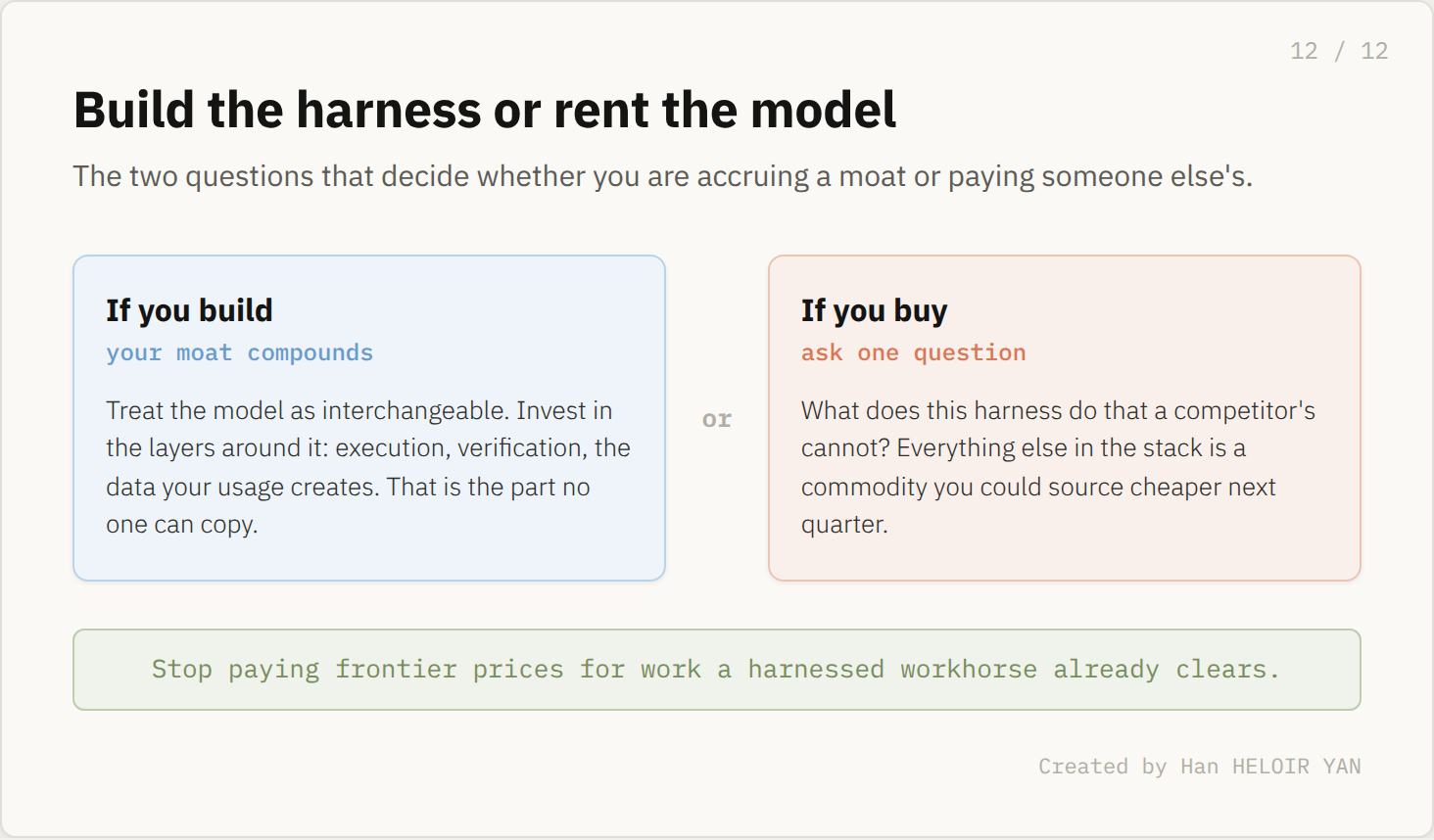
For buyers, the question changes. Stop paying frontier prices for work a harnessed workhorse already clears. Start asking every vendor what their harness does that a competitor's cannot, because that is the only part of the stack that is not a commodity you could source somewhere cheaper next quarter.
Cursor has said it is training its own model from scratch on Colossus 2, with roughly 10 times the compute behind Composer 2.5, developed with xAI. Read that against everything above.
The company whose entire advantage is the harness is about to stop borrowing its base model and stop renting its compute ceiling at the same time. If the thesis holds, that the harness was always the moat and the model was always the commodity, then a harness company with its own from scratch model and close to unlimited compute is not an incremental release. It is the moment the borrowed brain gets replaced and the one thing money could not buy stays exactly where it already was.
That is the release to write the date down for.