For six weeks you fought Claude Code. Prompts that used to work stopped working. Usage limits drained twice as fast. Sessions felt forgetful, repetitive, oddly lazy. You blamed yourself. You blamed your prompts. You read the Reddit threads where someone calmly explained that the model is fine and you're holding it wrong.
On April 23, Anthropic published the receipts. The model was fine. Three things in the harness around it were not.
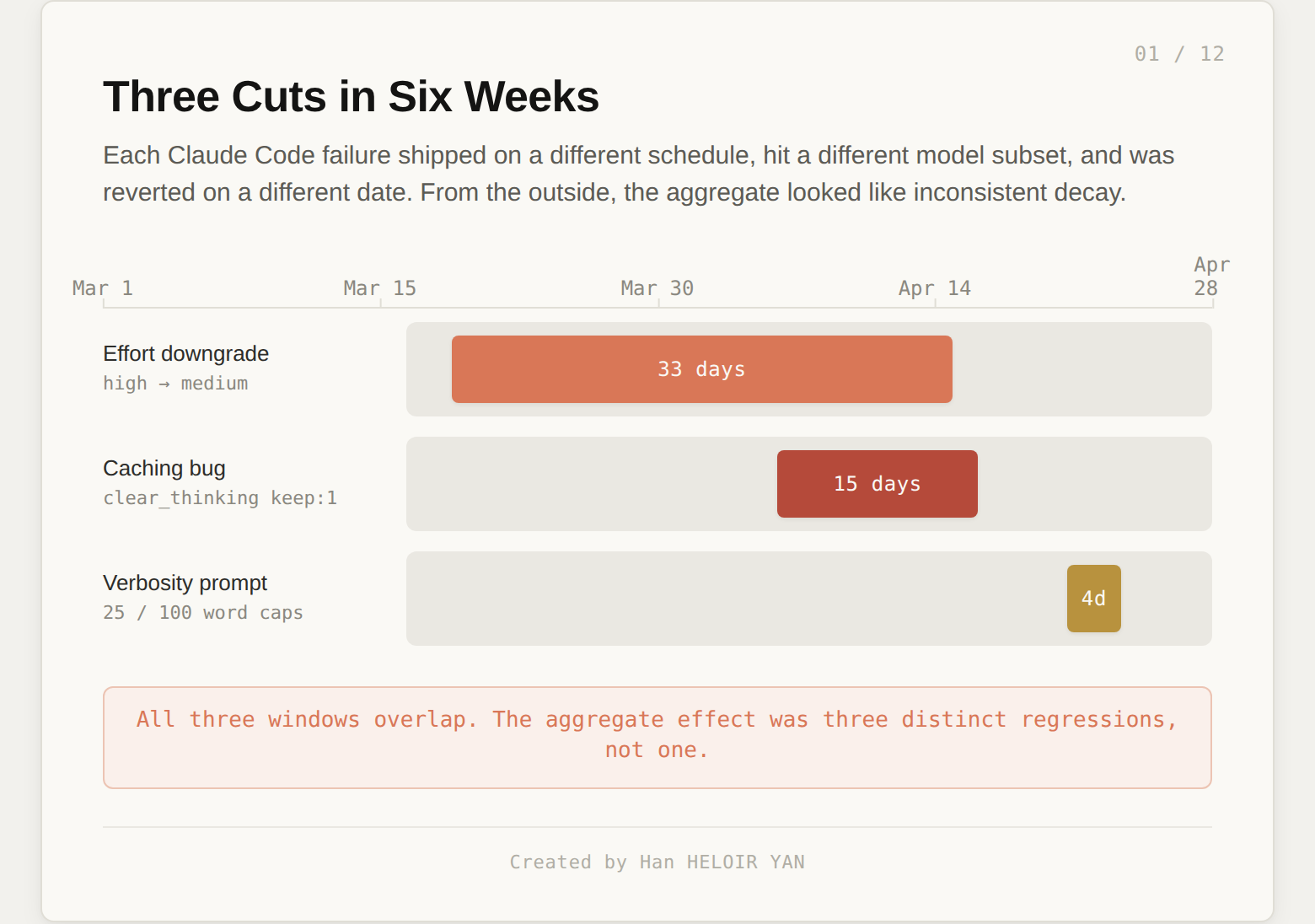
Three changes. Three schedules. Three bug fixes. Each shipped through code review, internal evals, and dogfooding. Each survived weeks before users forced the diagnosis. The post mortem is the cleanest field experiment in harness engineering anyone has published. The pattern in it is more important than the bugs.
🦸🏻♀️ If this helps you ship better AI systems:
👏 Clap 50 times (yes, you can!): Medium's algorithm favors this, increasing visibility to others who then discover the article.
🔔 Follow me on Medium, LinkedIn and subscribe to get my latest article.
On March 4, Pieter Levels (@levelsio, half a million followers on X) posted: "Claude Code with Opus 4.6 was so dumb today I finally had to write my own code again." It got screenshotted, retweeted, replied to. Other developers started saying the same thing. Then more. Within a week the community had a name for it: Claude Code "got nerfed."
Anthropic's account stayed quiet. Internal teams could not reproduce the issue. Their evals showed no regression. Customer support replied with the standard line: the model has not changed.
The community kept investigating. Stella Laurenzo, Senior Director in AMD's AI group, published an audit on GitHub: 6,852 Claude Code sessions, more than 234,000 tool calls, performance falling against her own historical baseline. She ran the analysis because the official channels would not. Her thread went viral inside the developer community within hours.
For six weeks the situation held. Users insisted something was wrong. Anthropic insisted nothing had changed. Both sides were working with the data they had. Threads filled with prompts that used to work and no longer did. People started questioning whether they had imagined Claude being smarter a month ago.
On April 23, Anthropic published the receipts. Three changes. Three weeks of overlap. Three reverts. The model had not changed. They had been right about that. Three things in the harness around it had changed, and the post mortem explained each one in detail.
Six weeks. Three failures. One painful confession.
Read the post mortem closely and one sentence stands out, from Anthropic's own engineering team:
"While we began investigating reports in early March, they were challenging to distinguish from normal variation in user feedback at first, and neither our internal usage nor evals initially reproduced the issues identified."
This is the diagnostic problem stated honestly. Three changes, on three schedules, hitting three different model subsets, produce three different symptom shapes that overlap in time. Some users see latency drops. Some see forgetfulness. Some see verbose responses suddenly clipped. Some see all three. Some see none.
When failures stack like this, user reports stop being signal. They become noise, because the same user can hit all three bugs in one week and report a single experience: "Claude feels worse." That report points at none of the three causes. It points at the sum, and the sum is unfalsifiable.
This is not an Anthropic problem. SRE teams have known it for decades and call it incident superposition. When two or more regressions overlap in production, debugging through user telemetry becomes mathematically harder, not just operationally harder. The information needed to separate the causes is not in the reports.
The honest takeaway: Anthropic's six week diagnostic delay was not a failure of effort. It was a failure of method. They were trying to read three overlapping signals as one, and waiting for cleaner reports that were never going to come.
What broke the deadlock was not better instrumentation. It was Pieter Levels and Stella Laurenzo. Two people with audiences large enough to force a wider eval ablation that would not have been run otherwise. We will come back to that.
When a model feels worse, the natural question is what changed in the model. The post mortem says nothing changed in the model. So the question shifts: where in the system around the model did things change?
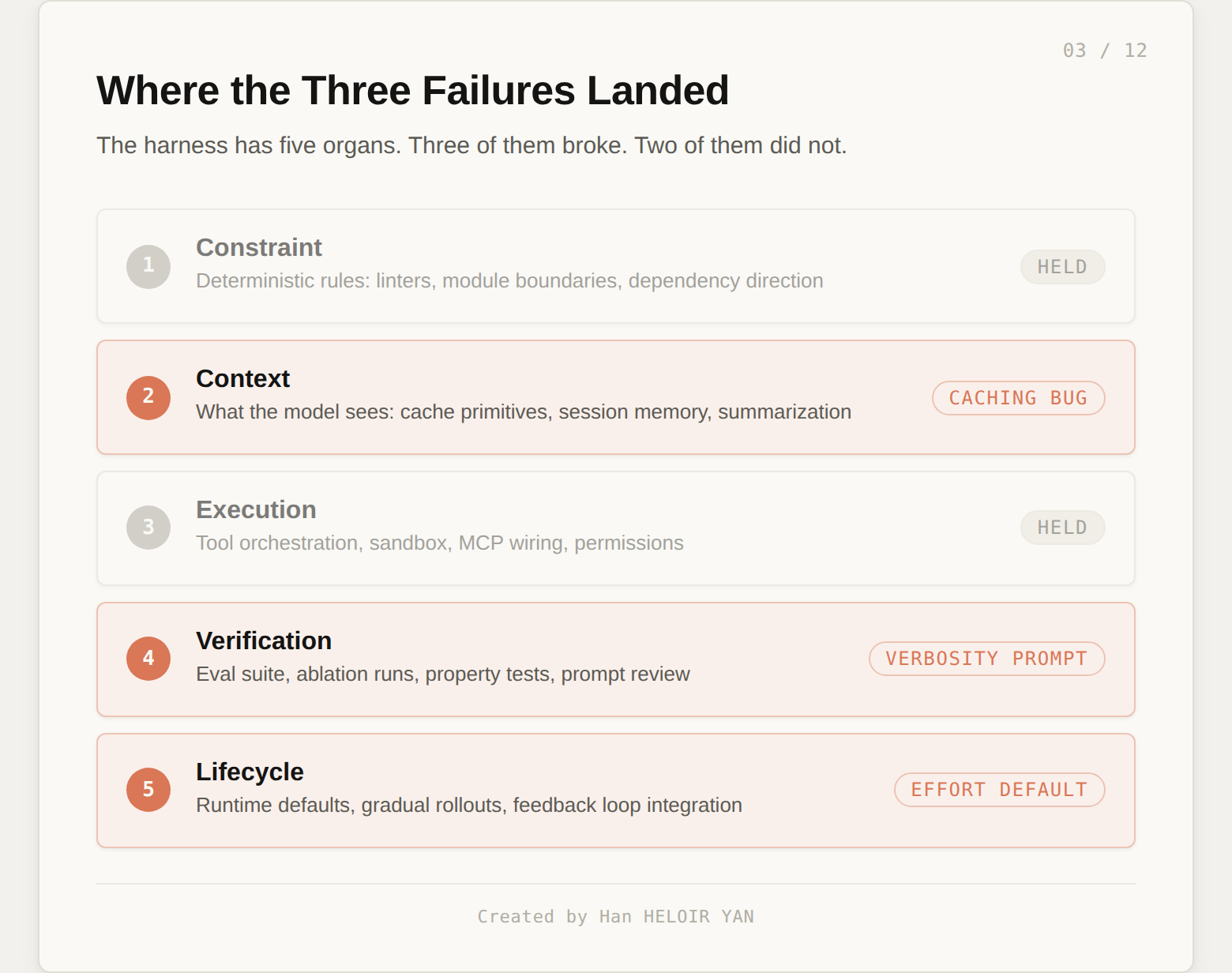
A harness has five organs. Constraint is the deterministic skeleton: linters, module boundaries, dependency direction, the rules that do not need an LLM to enforce. Context is what the model sees on each turn: the cache, the memory file, the summarization, the prompt. Execution is the hands: tool wiring, sandbox permissions, MCP. Verification is the immune system: the eval suite, ablation runs, prompt review process. Lifecycle is the nervous system: runtime defaults, gradual rollouts, the feedback loop that integrates user signal back into product decisions.
The three Anthropic failures landed on Lifecycle, Context, and Verification. Constraint and Execution did not move.
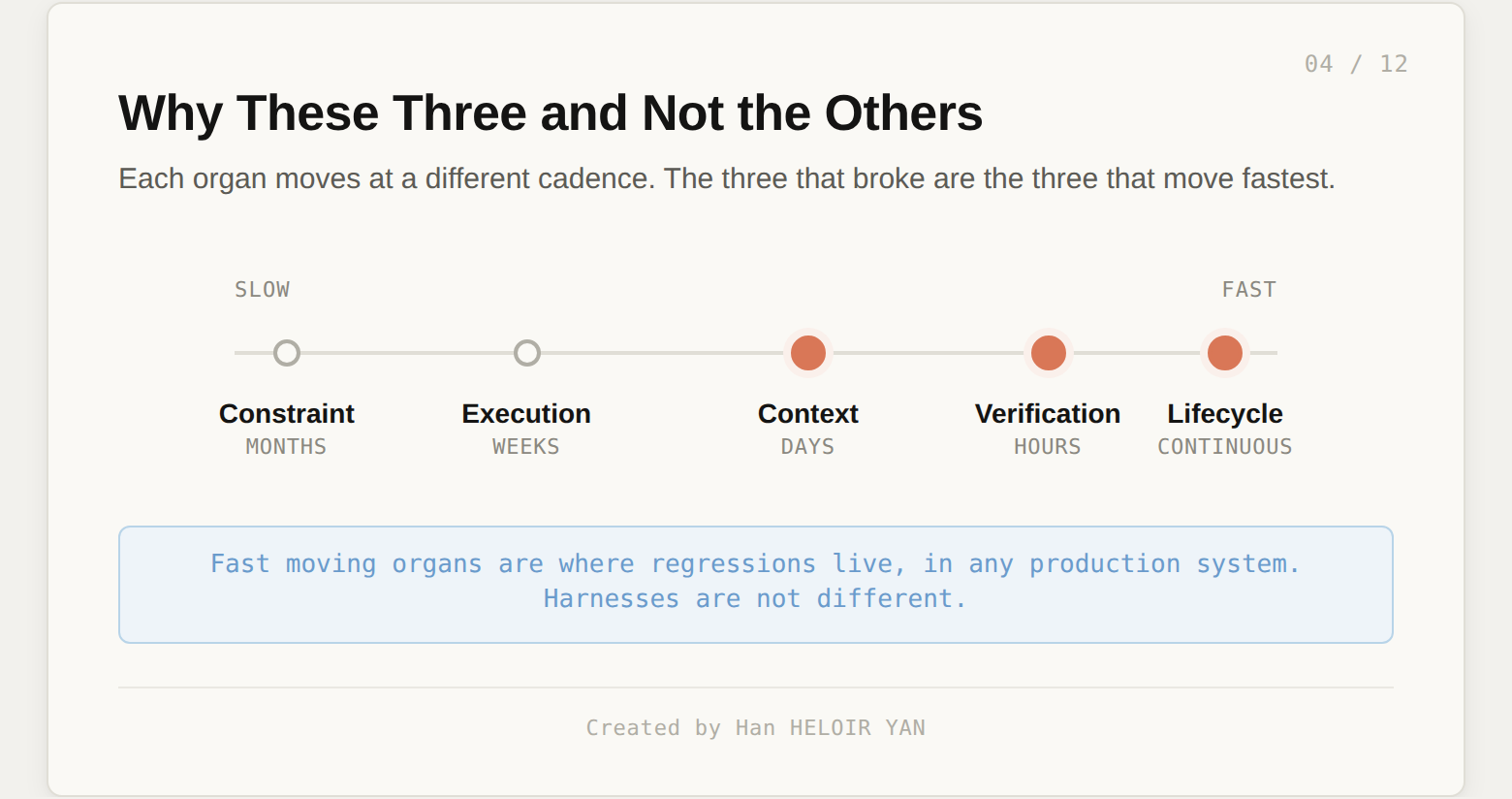
This is not coincidence. The organs that broke are the organs that change fastest. Constraint changes on the order of months. Execution on the order of weeks. Context, Verification, and Lifecycle change on the order of days, hours, and continuously.
The structural reason runs deeper than cadence. Code review culture protects what looks like code. Configs, prompts, runtime defaults, eval thresholds: these ship through different doors and different reviewers. Often the door is a config repo with one approver. Often the reviewer is the same person who wrote the change. Often the change is a single line.
Every harness team is one prompt change away from a quiet 3% degradation, because the prompt change does not look like a deployment. The fast moving organs are the ones that produce regressions, in any production system. AI products are not different in kind. They are different in degree, because more of their behavior is determined by the fast moving organs than is true for traditional software.
That generalization sets up the three structural laws this incident proves. One law per Cut.
Defaults move more user behavior than any feature launch. They get less review than any feature launch. That inversion is what shipped on March 4.
When Opus 4.6 launched in Claude Code in February, the default reasoning effort was set to high. Some users hit a tail latency issue: at high effort, Claude would occasionally think for over a minute before responding, and the UI would appear frozen. On March 4, a single line of config flipped the default from high to medium. Internal evals confirmed the trade was clean: slightly lower intelligence, significantly less latency, fewer usage limit hits for the majority of tasks. The decision shipped.

The change moved every Claude Code user who did not override the default. Most users do not override defaults. So a one line config change quietly redefined the experience of the entire product, in service of a metric (latency) that the affected users were not optimizing for. They wanted intelligence. They were willing to wait.
The Lifecycle organ owns this trade. It is supposed to detect mismatches between the metric you optimize for and the metric your users optimize for, through the feedback loop. It did, eventually. It took 33 days.
Why 33 days. The internal evals were short, fast, and dominant. The user signal was long delay, late arrival, weak weight. Pieter Levels' tweet on March 4 carried no weight in the calibration loop. It would have, if the loop had been wired to count it. The decision point sat where both signals fed in, but in practice one ran on a clock and the other ran on the news cycle.
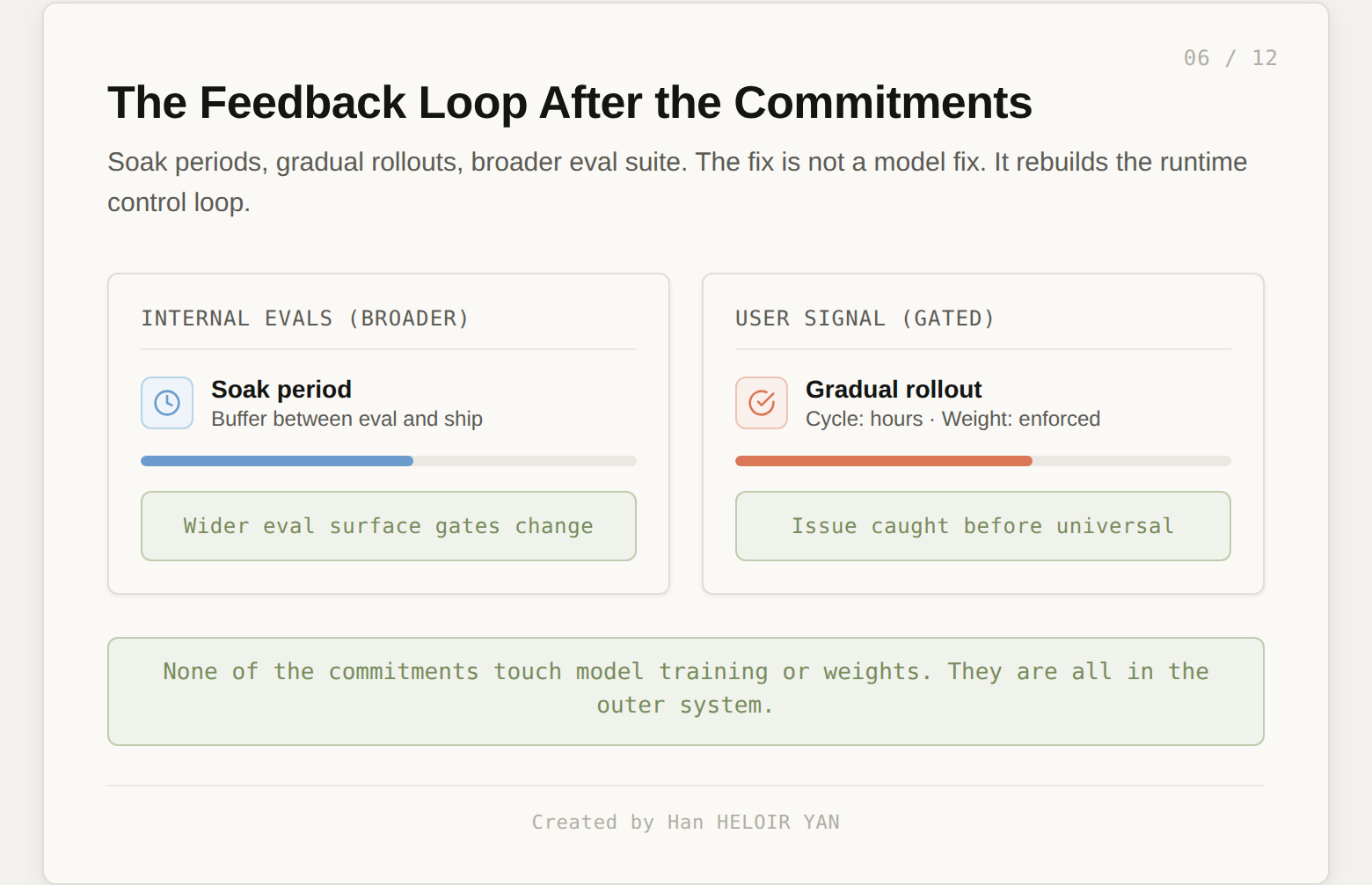
Anthropic's commitments here do not fix the model. They rebuild the loop. Soak periods. Gradual rollouts. Broader eval surface. All of it lives outside the model.
The portable lesson is uncomfortable. Almost no team treats default changes as the deployments they are. Defaults ship through config repos. Feature launches ship through PMs, blog posts, three rounds of review. The lever that moves the most behavior gets the least scrutiny, in service of a polite fiction that defaults are not "real" product changes.
They are. Anthropic just spent 33 days proving it.
Fast tests cannot find slow bugs. Most LLM bugs are slow.
The caching bug was not in the cache primitive. It was in the schedule. The clear_thinking_20251015 flag with keep:1 was supposed to fire once when a session crossed an hour idle gap, dropping uncached reasoning blocks that would be a cache miss anyway. The intent was sound. The implementation fired the prune every turn for the rest of the session.
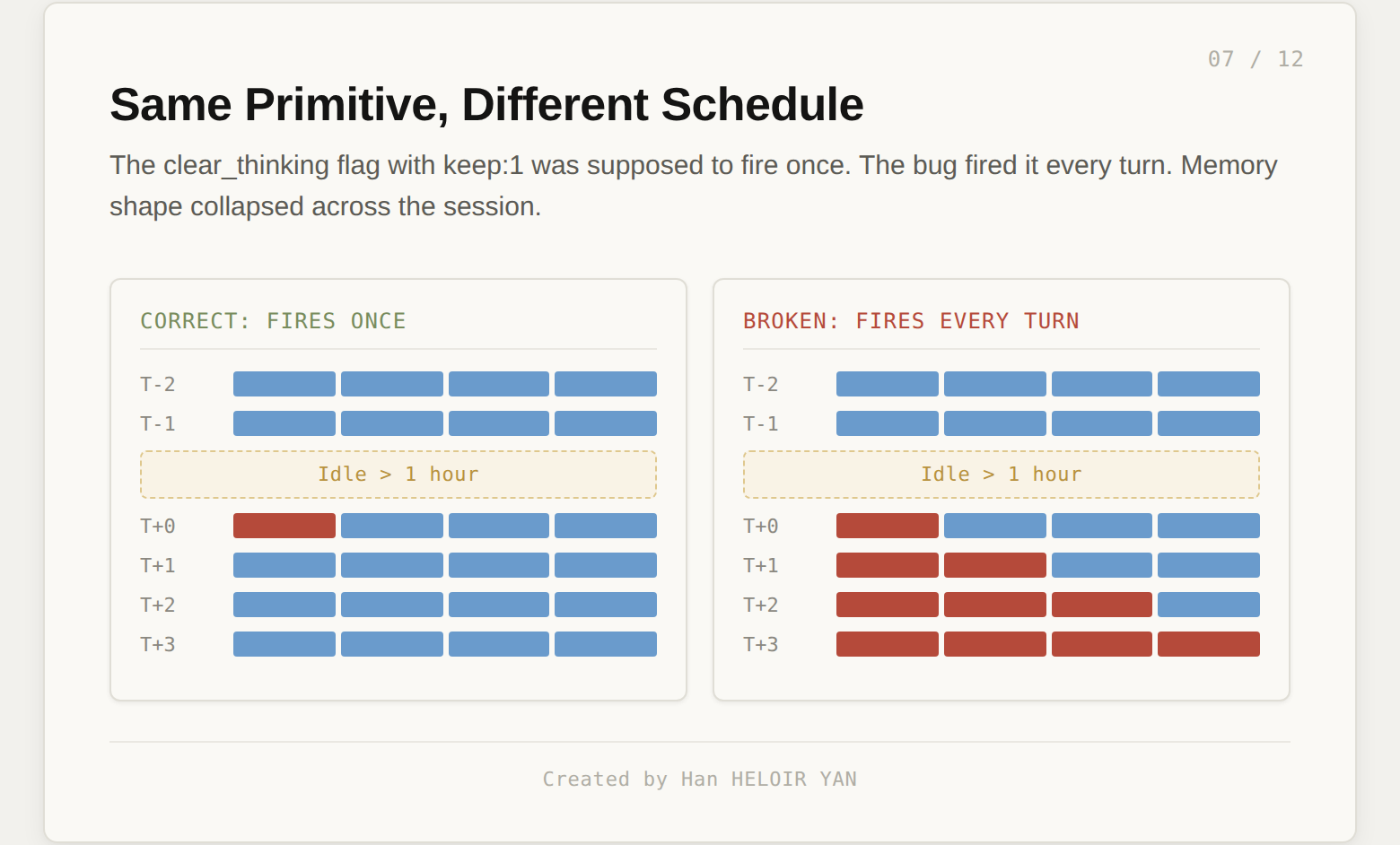
After a session crossed the idle threshold once, every subsequent request told the API to keep only the most recent reasoning block. If a follow up message landed mid tool use, that started a new turn under the broken flag, so even the current turn's reasoning was dropped. Claude kept executing, but progressively without memory of why.
The bug passed code review, unit tests, end to end tests, automated verification, and dogfooding. Anthropic is candid about this. The reason it passed is not that the reviewers were sloppy. The reason is structural.
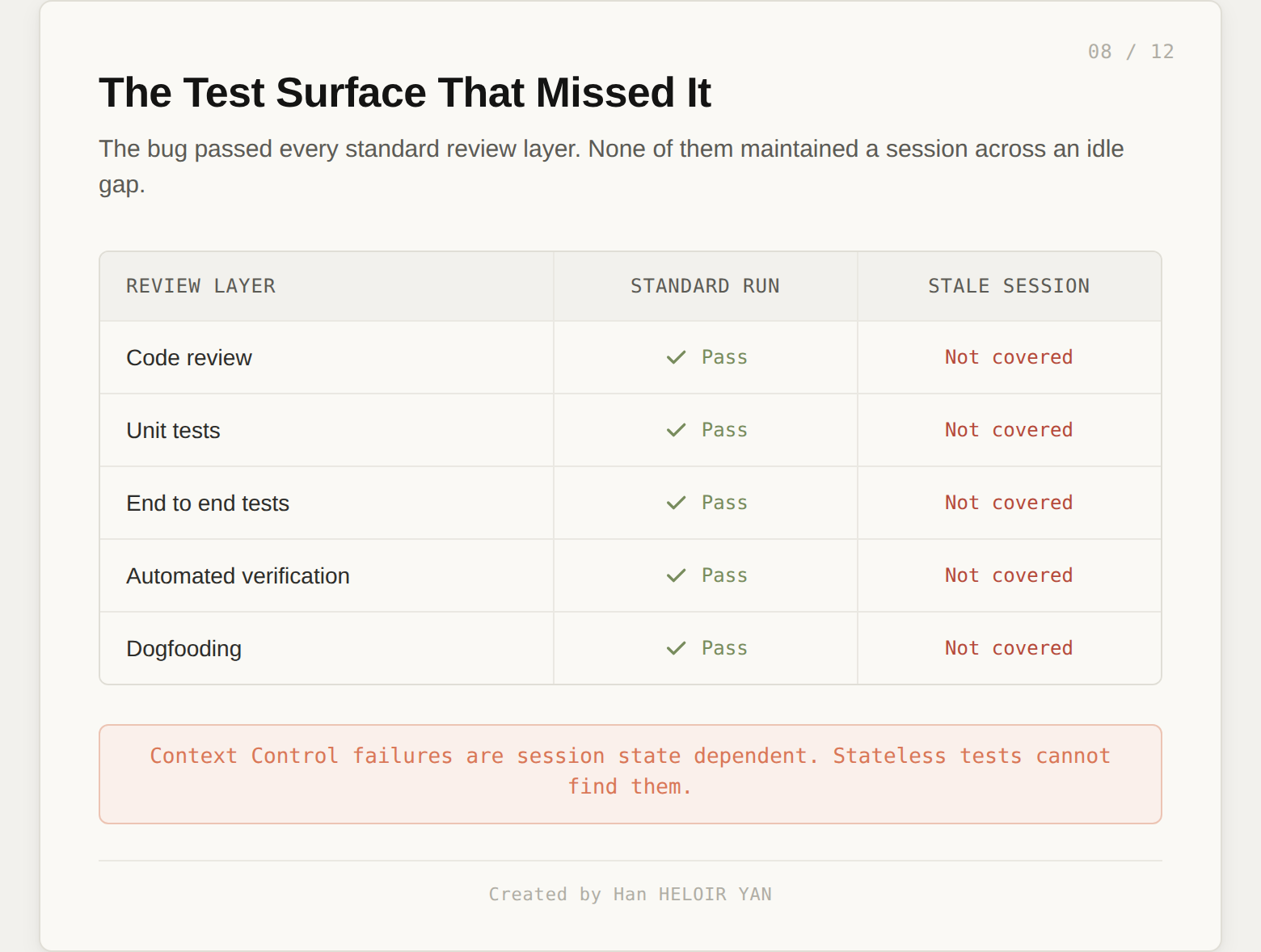
Code review takes minutes. Unit tests run in seconds. End to end tests run in tens of seconds, sometimes minutes if you splurge. Automated verification has the same budget. Dogfooding restarts sessions naturally as engineers move between tasks. Every gate that runs fast enough to ship behind, by definition, runs faster than an hour. The bug needed an hour of idle time to show up. It was invisible to every fast surface and visible only to real users with long, real sessions.
This is the dark matter of harness engineering. Session state dependent bugs do not surface in any test that resets between assertions or finishes before the bug ripens. CI has a deadline. The bug had patience. The bug won.
The fix Anthropic shipped is a one line schedule patch. The fix that prevents the next instance is a category of test that did not exist at Anthropic before April 10: long horizon, stateful, idle aware. Most teams do not have one. Most teams will not build one until they have shipped their own version of this bug.
The wider claim. As agents take longer turns, hold more state, and resume sessions hours or days later, the proportion of bugs that require patience to manifest goes up. CI was built for a world of stateless requests. The LLM era is increasingly a world of patient state. The mismatch is going to keep producing incidents like this one.
Your eval suite tells you what you can ship safely. It also tells you what you can only break by accident.
The verbosity prompt is the most important of the three failures because the bug was not the prompt. The bug was the eval that approved it.
The line is one sentence: "Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail." Internal evals ran for weeks. No regression. Anthropic shipped it confidently on April 16 alongside Opus 4.7.
The leaked Claude Code source contains an A/B comment next to the same line, recording the measurement that justified it: roughly a 1.2% reduction in output tokens against softer phrasing. That number is real. It was the number that won the argument internally.
The post mortem reports a different number. After users complained, Anthropic ran a broader ablation. The wider eval found a 3% coding quality drop on both Opus 4.6 and Opus 4.7. Also real.
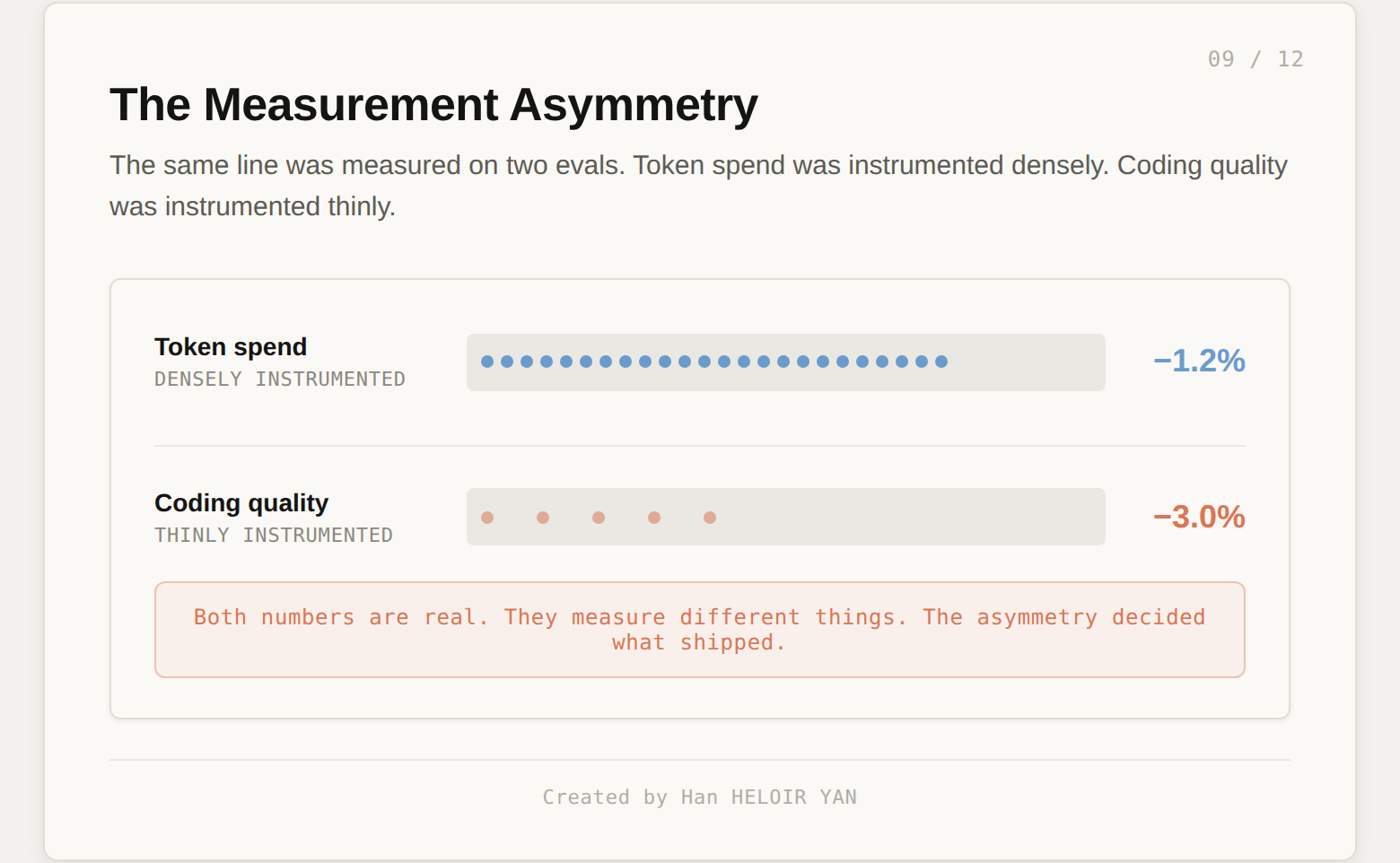
Both numbers were measured on the same line. They measured different properties. Token spend was densely instrumented. Coding quality was thinly instrumented, until users forced the wider run.
This is a structural law of measurement, not an Anthropic mistake. Token spend is O(1) to measure. You count tokens per request. Done. Coding quality is O(N) to measure. You need a benchmark suite, a grader, a stable comparison set, and enough scale to distinguish a 3% drop from variance. The cost difference is at least two orders of magnitude.

Every team will under instrument the expensive measurement, forever, unless they fight it. The verbosity prompt did not fail. The eval suite failed by design. It optimized what was cheap to measure, and drift accumulated in what was expensive.
Anthropic's commitments here are the most explicit in the post mortem. Per model evals for every system prompt change. Continuing ablations to understand the impact of each line. New tooling to make prompt changes easier to review and audit. Read each phrase carefully. None of these fix the model. All of them widen the measurement surface.
The uncomfortable extension goes further than Anthropic does. If quality is fundamentally O(N) to measure and your team's review velocity needs to be O(1), there is a permanent bias in what you can ship safely. You can ship token reductions confidently. You can ship latency improvements confidently. You can only ship quality changes confidently if you have built infrastructure that almost no team has built. Every regression in your harness will land in whatever property you could not afford to instrument densely.
The shape of your evals is a fossil record of what your team prioritized building. Read it carefully, because that record also tells you exactly where your next incident will come from.
Constraint and Execution did not appear in the post mortem. Both organs ship through code review and version control. The deterministic rules. The tool wiring. The sandbox boundary. None of these were touched during the window. The honest reading: they did not fail because they did not move.
This is not comfort. It is timing. When Constraint changes (a new module boundary, a new lint rule for agent generated code) it will change through the same review process the broken organs already use. When Execution changes (a new MCP server, a new sandbox permission) it will too. The deployment infrastructure that protected them is exactly as good as the deployment infrastructure that failed for the other three. They are quiet because they did not ship anything new.
When they do ship something new, they will fail in proportion to how much they ship. The two organs are not safe. They are slow.
There is a quiet admission inside Anthropic's commitment to weight user signal earlier. The user signal that broke this case was not in any eval. It was on Twitter and GitHub.
Pieter Levels' tweet on March 4 was the first widely shared report. By March 7, the @levelsio thread had thousands of replies from developers comparing notes. The thread was Anthropic's first informal eval of their March 4 default change, and it was running on a platform Anthropic does not own.
Stella Laurenzo's GitHub audit two weeks later was the first quantitative external benchmark. 6,852 sessions. 234,000 tool calls. A historical baseline she had built for her own use. Her audit had more granularity than most internal evals. It also ran on a platform Anthropic does not control.
When the post mortem says "we will weight user signal earlier in our calibration," what it means in practice is: we will read Twitter and GitHub more seriously as runtime telemetry. That is the only place the signal lived. The commitment is an admission that the harness extends beyond their repo, into platforms where their power users complain in public.
This is uncomfortable for two reasons.
First, every harness team now needs a way to ingest social signal as part of their feedback loop. This is not a problem most engineering teams know how to solve. Sentiment analysis on Twitter is not the answer. Tracking specific high signal accounts (Pieter Levels, Simon Willison, the leak watchers, the technical bloggers who run their own benchmarks) is closer, but it does not scale and it does not productize.
Second, smaller vendors with no Pieter Levels equivalent will run their bugs longer. Anthropic got six weeks. A startup with five thousand users and no power user accounts on X gets six months at minimum. Quality stratification at the harness layer is now a real phenomenon. Big vendors with public power user bases are on a faster fix loop than small vendors with the same engineering quality. Uncomfortable but true.
Three actions, in order of cost.
First, audit your defaults. Make a list of every runtime default in your AI product. Reasoning effort. Temperature. Max tokens. Tool budgets. Context window targets. Cache eviction thresholds. For each one, write down which user signal you optimized for when you set it, and which signal a vocal subset of users would optimize for instead. If those two signals are different, you have a Pieter Levels timer running, and it started the day you shipped the default.
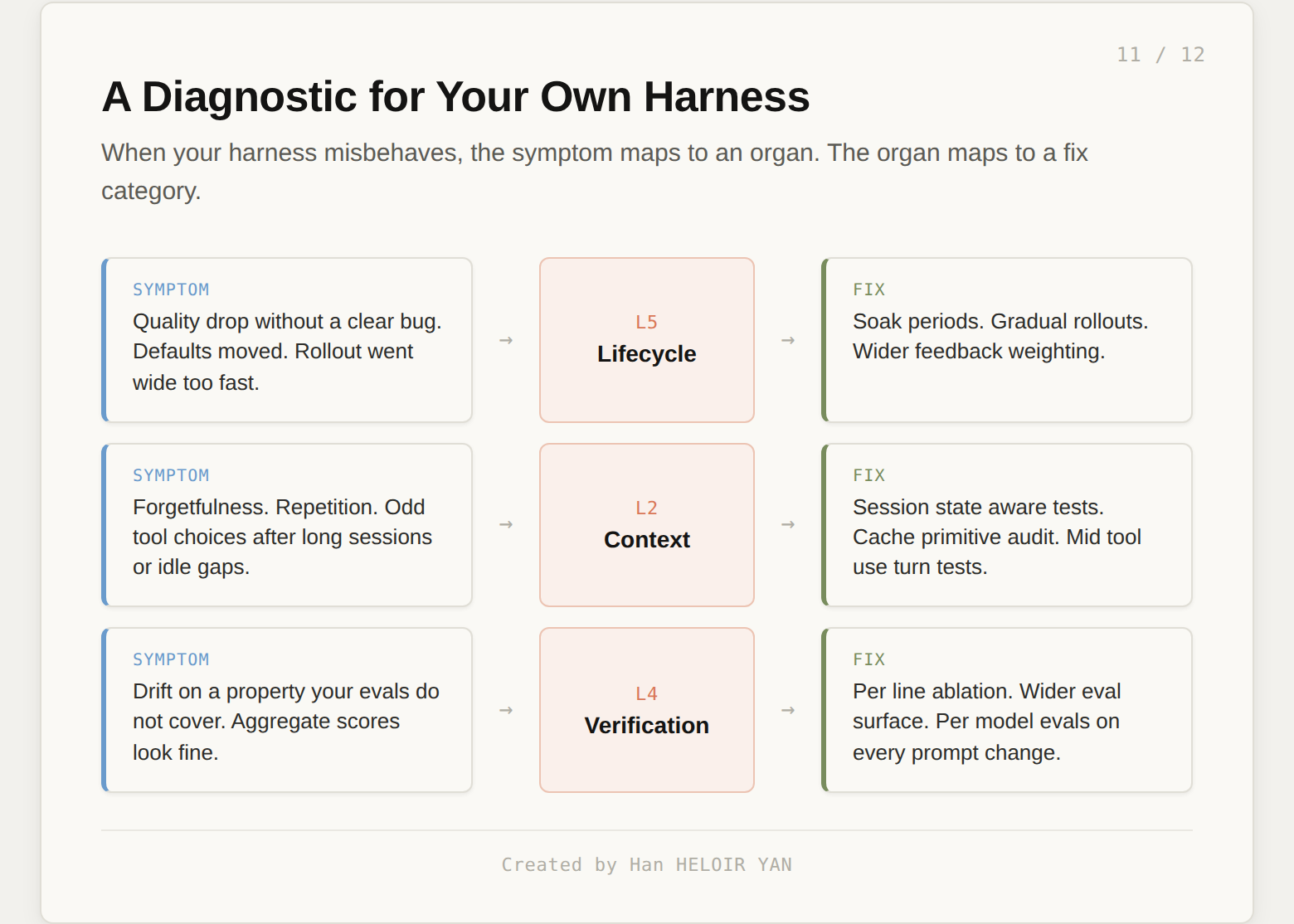
Second, build one stateful test. Pick the agent behavior most likely to break under long sessions. Idle resumption. Mid tool use interruption. Multi turn context survival. Write one test that runs at least an hour, holds session state across the gap, and asserts what the agent should remember. Add it to your CI as a nightly job. You now have one test that can find slow bugs. Most teams have zero.
Third, name the property your evals do not measure. Pull up your eval suite. List what it measures densely (latency, token count, tool call success rate, cost). List what it measures thinly or not at all (coding quality on hard problems, factual accuracy under load, multi turn coherence, refusal calibration). The thinly measured list is your bug surface for the next twelve months.
Then watch the next vendor's post mortem. Cursor, Cognition, OpenAI Codex, Replit. They will hit the same pattern. Lifecycle, Context, Verification, in roughly this proportion. If they do, the framework holds. If they do not, the framework gets revised. Either way, harness engineering is no longer a frame. It has a reference incident. The bar moved in April.
Created by Han HELOIR YAN, Ph.D.